 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Model Merging in Domain-Specific Ad-hoc Retrieval
Sep 26, 2025In this study, we evaluate the effect of model merging in ad-hoc retrieval tasks. Model merging is a technique that combines the diverse characteristics of multiple models. We hypothesized that applying model merging to domain-specific ad-hoc retrieval tasks could improve retrieval effectiveness. To verify this hypothesis, we merged the weights of a source retrieval model and a domain-specific (non-retrieval) model using a linear interpolation approach. A key advantage of our approach is that it requires no additional fine-tuning of the models. We conducted two experiments each in the medical and Japanese domains. The first compared the merged model with the source retrieval model, and the second compared it with a LoRA fine-tuned model under both full and limited data settings for model construction. The experimental results indicate that model merging has the potential to produce more effective domain-specific retrieval models than the source retrieval model, and may serve as a practical alternative to LoRA fine-tuning, particularly when only a limited amount of data is available.
Towards Consistency Filtering-Free Unsupervised Learning for Dense Retrieval
Aug 05, 2023Domain transfer is a prevalent challenge in modern neural Information Retrieval (IR). To overcome this problem, previous research has utilized domain-specific manual annotations and synthetic data produced by consistency filtering to finetune a general ranker and produce a domain-specific ranker. However, training such consistency filters are computationally expensive, which significantly reduces the model efficiency. In addition, consistency filtering often struggles to identify retrieval intentions and recognize query and corpus distributions in a target domain. In this study, we evaluate a more efficient solution: replacing the consistency filter with either direct pseudo-labeling, pseudo-relevance feedback, or unsupervised keyword generation methods for achieving consistent filtering-free unsupervised dense retrieval. Our extensive experimental evaluations demonstrate that, on average, TextRank-based pseudo relevance feedback outperforms other methods. Furthermore, we analyzed the training and inference efficiency of the proposed paradigm. The results indicate that filtering-free unsupervised learning can continuously improve training and inference efficiency while maintaining retrieval performance. In some cases, it can even improve performance based on particular datasets.
Learned k-NN Distance Estimation
Aug 29, 2022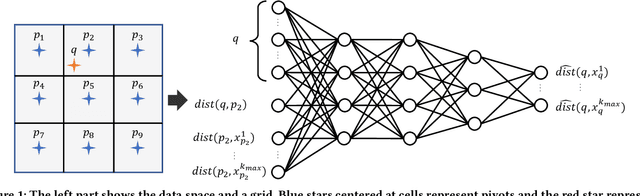
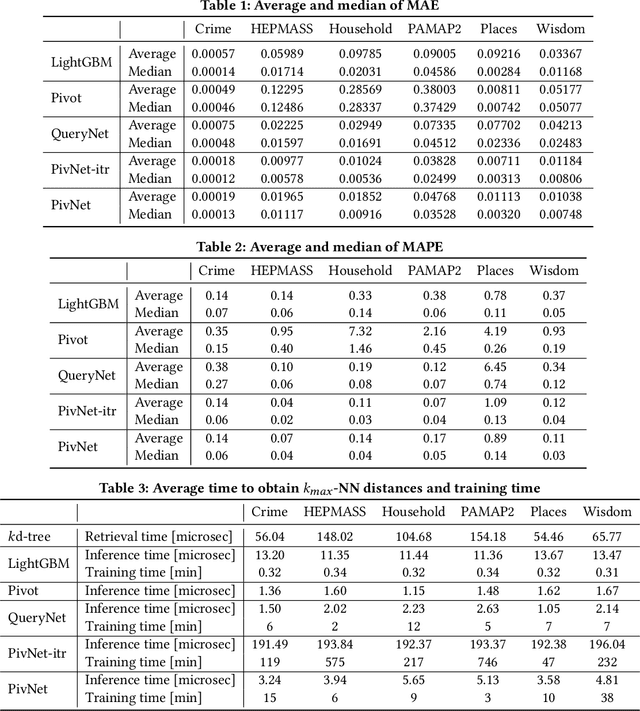

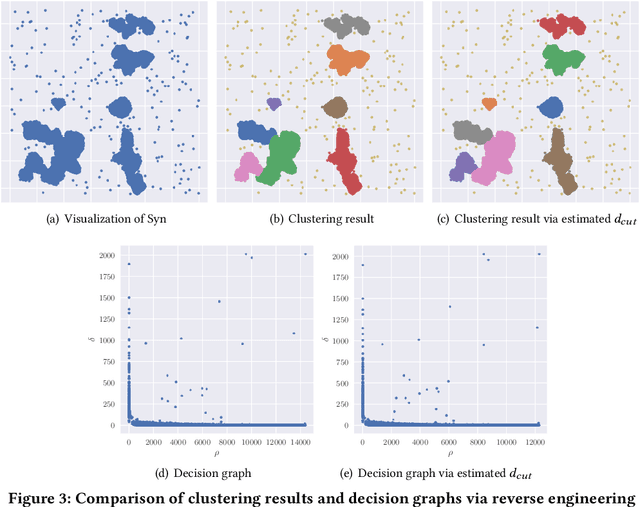
Big data mining is well known to be an important task for data science, because it can provide useful observations and new knowledge hidden in given large datasets. Proximity-based data analysis is particularly utilized in many real-life applications. In such analysis, the distances to k nearest neighbors are usually employed, thus its main bottleneck is derived from data retrieval. Much efforts have been made to improve the efficiency of these analyses. However, they still incur large costs, because they essentially need many data accesses. To avoid this issue, we propose a machine-learning technique that quickly and accurately estimates the k-NN distances (i.e., distances to the k nearest neighbors) of a given query. We train a fully connected neural network model and utilize pivots to achieve accurate estimation. Our model is designed to have useful advantages: it infers distances to the k-NNs at a time, its inference time is O(1) (no data accesses are incurred), but it keeps high accuracy. Our experimental results and case studies on real datasets demonstrate the efficiency and effectiveness of our solution.
BanditRank: Learning to Rank Using Contextual Bandits
Oct 23, 2019
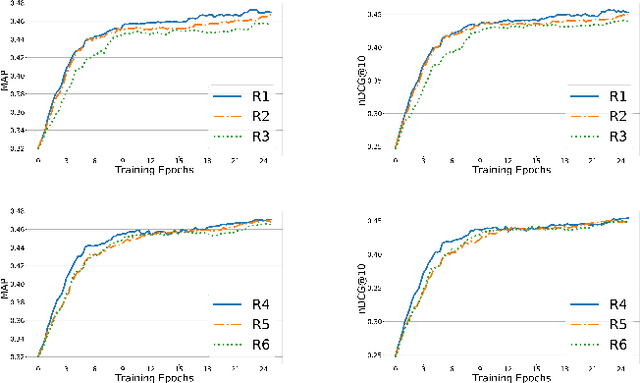


We propose an extensible deep learning method that uses reinforcement learning to train neural networks for offline ranking in information retrieval (IR). We call our method BanditRank as it treats ranking as a contextual bandit problem. In the domain of learning to rank for IR, current deep learning models are trained on objective functions different from the measures they are evaluated on. Since most evaluation measures are discrete quantities, they cannot be leveraged by directly using gradient descent algorithms without an approximation. BanditRank bridges this gap by directly optimizing a task-specific measure, such as mean average precision (MAP), using gradient descent. Specifically, a contextual bandit whose action is to rank input documents is trained using a policy gradient algorithm to directly maximize the reward. The reward can be a single measure, such as MAP, or a combination of several measures. The notion of ranking is also inherent in BanditRank, similar to the current \textit{listwise} approaches. To evaluate the effectiveness of BanditRank, we conducted a series of experiments on datasets related to three different tasks, i.e., web search, community, and factoid question answering. We found that it performs better than state-of-the-art methods when applied on the question answering datasets. On the web search dataset, we found that BanditRank performed better than four strong listwise baselines including LambdaMART, AdaRank, ListNet and Coordinate Ascent.
From VQA to Multimodal CQA: Adapting Visual QA Models for Community QA Tasks
Aug 29, 2018

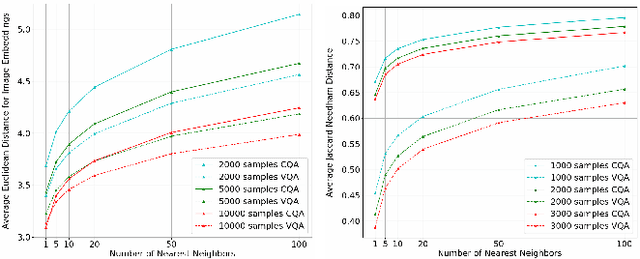
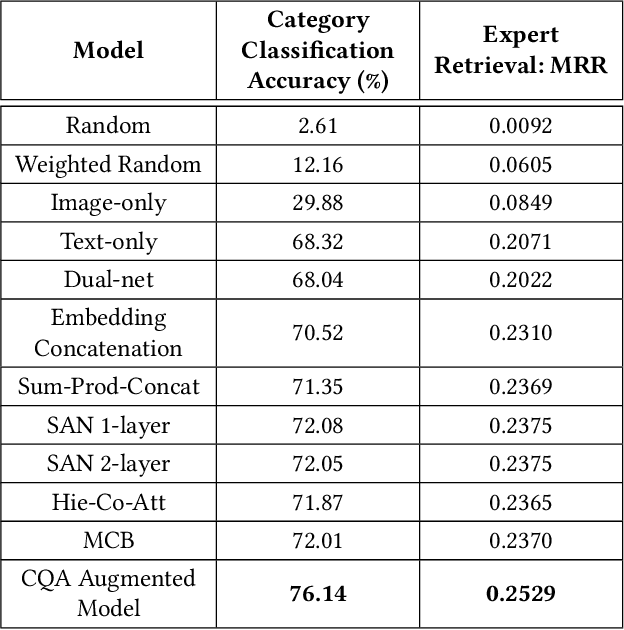
In this work, we present novel methods to adapt visual QA models for community QA tasks of practical significance - automated question category classification and finding experts for question answering - on questions containing both text and image. To the best of our knowledge, this is the first work to tackle the multimodality challenge in CQA, and is an enabling step towards basic question-answering on image-based CQA. First, we analyze the differences between visual QA and community QA datasets, discussing the limitations of applying VQA models directly to CQA tasks, and then we propose novel augmentations to VQA-based models to best address those limitations. Our model, with the augmentations of an image-text combination method tailored for CQA and use of auxiliary tasks for learning better grounding features, significantly outperforms the text-only and VQA model baselines for both tasks on real-world CQA data from Yahoo! Chiebukuro, a Japanese counterpart of Yahoo! Answers.
Learning to Rank Query Recommendations by Semantic Similarities
Apr 12, 2012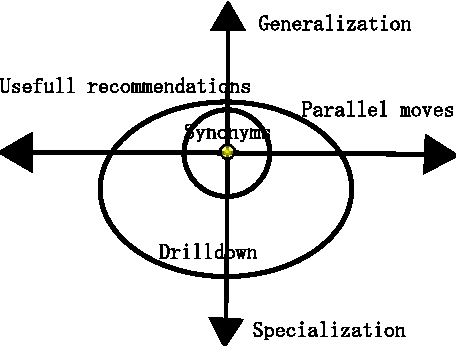
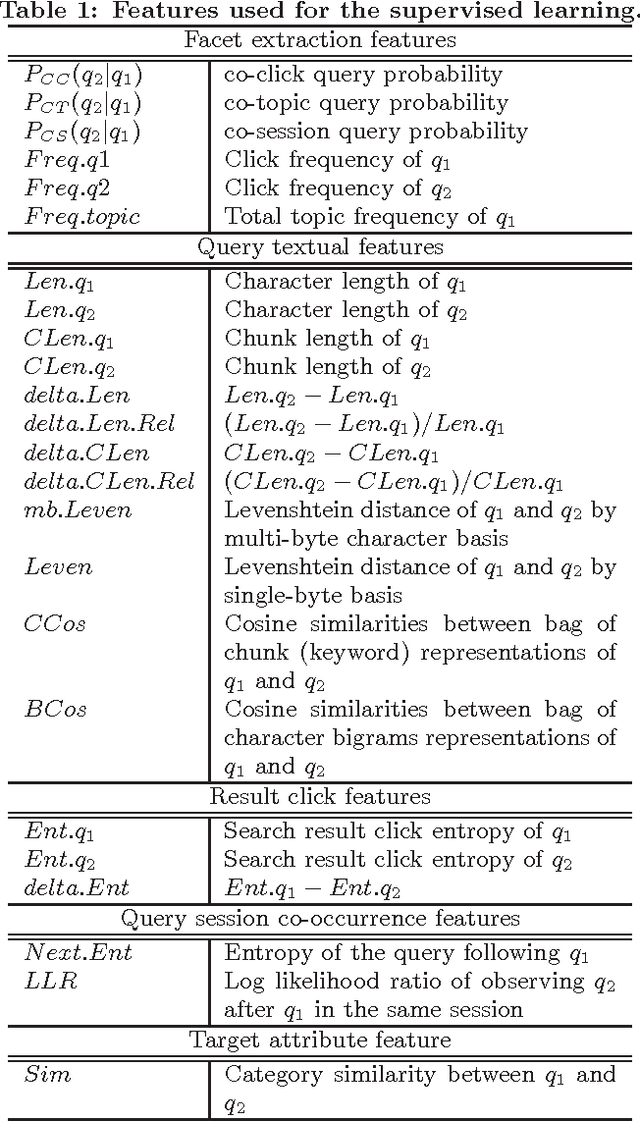
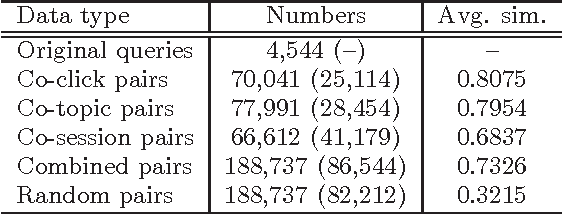

Logs of the interactions with a search engine show that users often reformulate their queries. Examining these reformulations shows that recommendations that precise the focus of a query are helpful, like those based on expansions of the original queries. But it also shows that queries that express some topical shift with respect to the original query can help user access more rapidly the information they need. We propose a method to identify from the query logs of past users queries that either focus or shift the initial query topic. This method combines various click-based, topic-based and session based ranking strategies and uses supervised learning in order to maximize the semantic similarities between the query and the recommendations, while at the same diversifying them. We evaluate our method using the query/click logs of a Japanese web search engine and we show that the combination of the three methods proposed is significantly better than any of them taken individually.