 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom VQA to Multimodal CQA: Adapting Visual QA Models for Community QA Tasks
Paper and Code


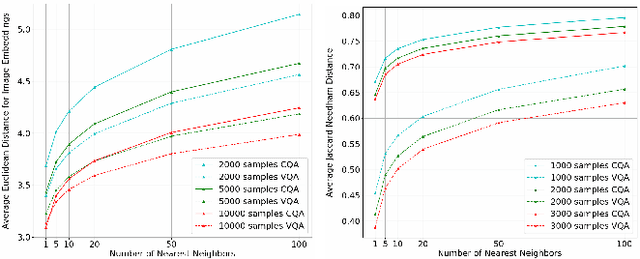
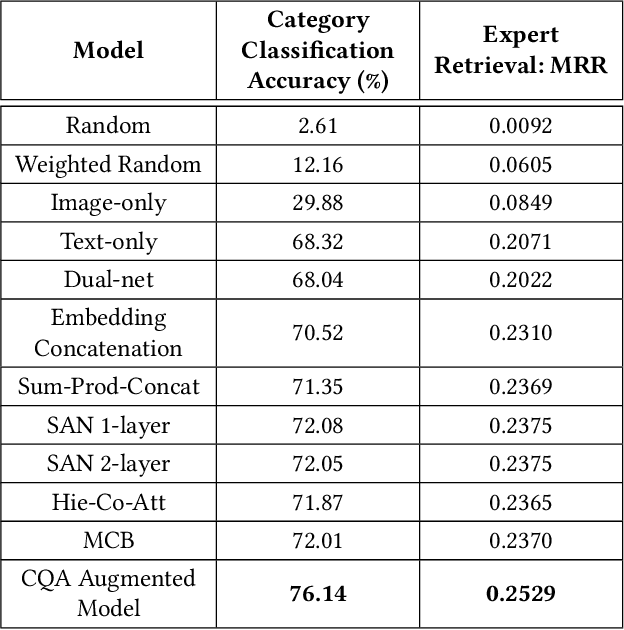
In this work, we present novel methods to adapt visual QA models for community QA tasks of practical significance - automated question category classification and finding experts for question answering - on questions containing both text and image. To the best of our knowledge, this is the first work to tackle the multimodality challenge in CQA, and is an enabling step towards basic question-answering on image-based CQA. First, we analyze the differences between visual QA and community QA datasets, discussing the limitations of applying VQA models directly to CQA tasks, and then we propose novel augmentations to VQA-based models to best address those limitations. Our model, with the augmentations of an image-text combination method tailored for CQA and use of auxiliary tasks for learning better grounding features, significantly outperforms the text-only and VQA model baselines for both tasks on real-world CQA data from Yahoo! Chiebukuro, a Japanese counterpart of Yahoo! Answers.