 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Weak Supervision Framework for Query Intent Classification in Video Search
Sep 13, 2024


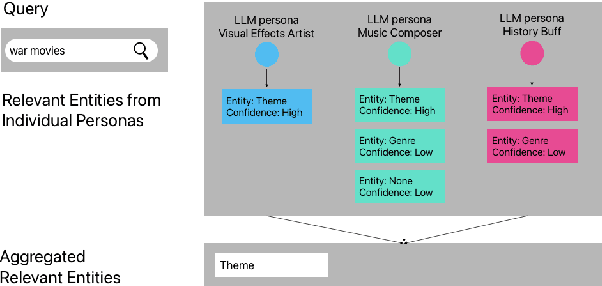
Streaming services have reshaped how we discover and engage with digital entertainment. Despite these advancements, effectively understanding the wide spectrum of user search queries continues to pose a significant challenge. An accurate query understanding system that can handle a variety of entities that represent different user intents is essential for delivering an enhanced user experience. We can build such a system by training a natural language understanding (NLU) model; however, obtaining high-quality labeled training data in this specialized domain is a substantial obstacle. Manual annotation is costly and impractical for capturing users' vast vocabulary variations. To address this, we introduce a novel approach that leverages large language models (LLMs) through weak supervision to automatically annotate a vast collection of user search queries. Using prompt engineering and a diverse set of LLM personas, we generate training data that matches human annotator expectations. By incorporating domain knowledge via Chain of Thought and In-Context Learning, our approach leverages the labeled data to train low-latency models optimized for real-time inference. Extensive evaluations demonstrated that our approach outperformed the baseline with an average relative gain of 113% in recall. Furthermore, our novel prompt engineering framework yields higher quality LLM-generated data to be used for weak supervision; we observed 47.60% improvement over baseline in agreement rate between LLM predictions and human annotations with respect to F1 score, weighted according to the distribution of occurrences of the search queries. Our persona selection routing mechanism further adds an additional 3.67% increase in weighted F1 score on top of our novel prompt engineering framework.
Investigating the locality of neural network training dynamics
Nov 01, 2021
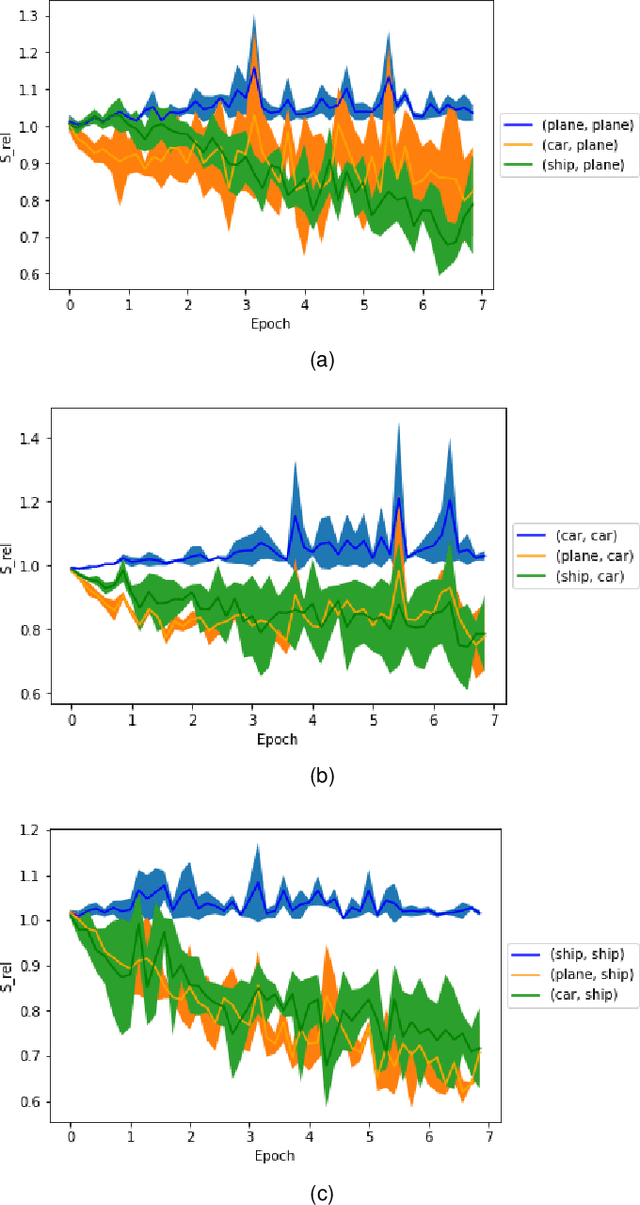
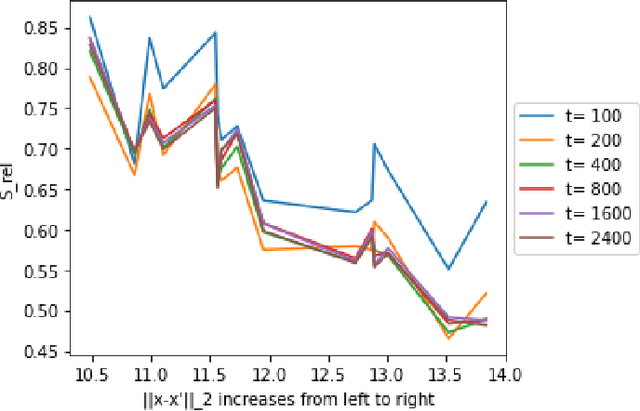
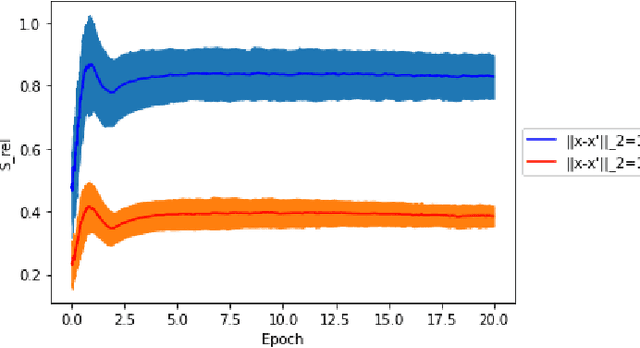
A fundamental quest in the theory of deep-learning is to understand the properties of the trajectories in the weight space that a learning algorithm takes. One such property that had very recently been isolated is that of "local elasticity" ($S_{\rm rel}$), which quantifies the propagation of influence of a sampled data point on the prediction at another data point. In this work, we perform a comprehensive study of local elasticity by providing new theoretical insights and more careful empirical evidence of this property in a variety of settings. Firstly, specific to the classification setting, we suggest a new definition of the original idea of $S_{\rm rel}$. Via experiments on state-of-the-art neural networks training on SVHN, CIFAR-10 and CIFAR-100 we demonstrate how our new $S_{\rm rel}$ detects the property of the weight updates preferring to make changes in predictions within the same class of the sampled data. Next, we demonstrate via examples of neural nets doing regression that the original $S_{\rm rel}$ reveals a $2-$phase behaviour: that their training proceeds via an initial elastic phase when $S_{\rm rel}$ changes rapidly and an eventual inelastic phase when $S_{\rm rel}$ remains large. Lastly, we give multiple examples of learning via gradient flows for which one can get a closed-form expression of the original $S_{\rm rel}$ function. By studying the plots of these derived formulas we given a theoretical demonstration of some of the experimentally detected properties of $S_{\rm rel}$ in the regression setting.
Object Files and Schemata: Factorizing Declarative and Procedural Knowledge in Dynamical Systems
Jun 30, 2020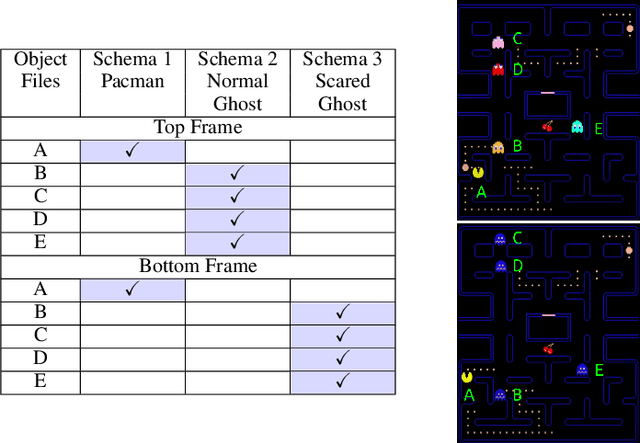
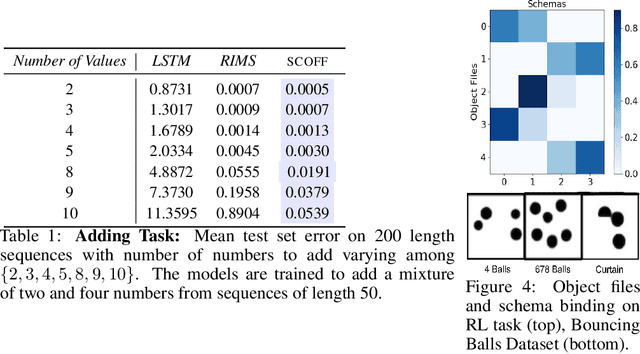
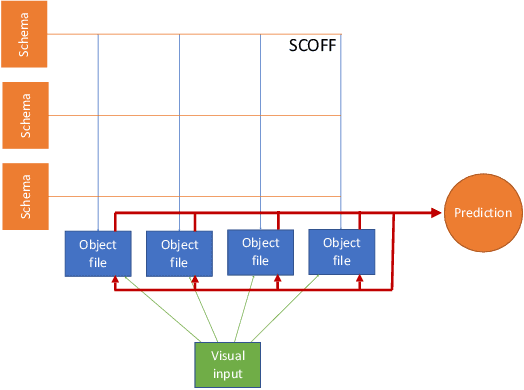

Modeling a structured, dynamic environment like a video game requires keeping track of the objects and their states (\emph{declarative} knowledge) as well as predicting how objects behave (\emph{procedural} knowledge). Black-box models with a monolithic hidden state often lack \emph{systematicity}: they fail to apply procedural knowledge consistently and uniformly. For example, in a video game, correct prediction of one enemy's trajectory does not ensure correct prediction of another's. We address this issue via an architecture that factorizes declarative and procedural knowledge and that imposes modularity within each form of knowledge. The architecture consists of active modules called \emph{object files} that maintain the state of a single object and invoke passive external knowledge sources called \emph{schemata} that prescribe state updates. To use a video game as an illustration, two enemies of the same type will share schemata but will each have their own object file to encode their distinct state (e.g., health, position). We propose to use attention to control the determination of which object files to update, the selection of schemata, and the propagation of information between object files. The resulting architecture is a drop-in replacement conforming to the same input-output interface as normal recurrent networks (e.g., LSTM, GRU) yet achieves substantially better generalization on environments that have factorized declarative and procedural knowledge, including a challenging intuitive physics benchmark.
BanditRank: Learning to Rank Using Contextual Bandits
Oct 23, 2019
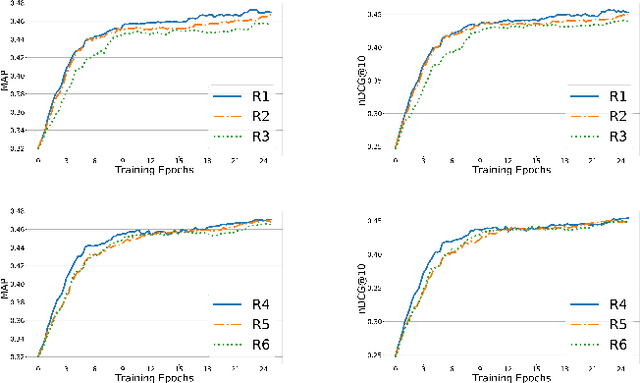


We propose an extensible deep learning method that uses reinforcement learning to train neural networks for offline ranking in information retrieval (IR). We call our method BanditRank as it treats ranking as a contextual bandit problem. In the domain of learning to rank for IR, current deep learning models are trained on objective functions different from the measures they are evaluated on. Since most evaluation measures are discrete quantities, they cannot be leveraged by directly using gradient descent algorithms without an approximation. BanditRank bridges this gap by directly optimizing a task-specific measure, such as mean average precision (MAP), using gradient descent. Specifically, a contextual bandit whose action is to rank input documents is trained using a policy gradient algorithm to directly maximize the reward. The reward can be a single measure, such as MAP, or a combination of several measures. The notion of ranking is also inherent in BanditRank, similar to the current \textit{listwise} approaches. To evaluate the effectiveness of BanditRank, we conducted a series of experiments on datasets related to three different tasks, i.e., web search, community, and factoid question answering. We found that it performs better than state-of-the-art methods when applied on the question answering datasets. On the web search dataset, we found that BanditRank performed better than four strong listwise baselines including LambdaMART, AdaRank, ListNet and Coordinate Ascent.
A Tractable Algorithm For Finite-Horizon Continuous Reinforcement Learning
Jun 26, 2019
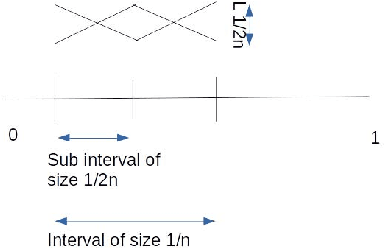


We consider the finite horizon continuous reinforcement learning problem. Our contribution is three-fold. First,we give a tractable algorithm based on optimistic value iteration for the problem. Next,we give a lower bound on regret of order $\Omega(T^{2/3})$ for any algorithm discretizes the state space, improving the previous regret bound of $\Omega(T^{1/2})$ of Ortner and Ryabko \cite{contrl} for the same problem. Next,under the assumption that the rewards and transitions are H\"{o}lder Continuous we show that the upper bound on the discretization error is $const.Ln^{-\alpha}T$. Finally,we give some simple experiments to validate our propositions.