 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024

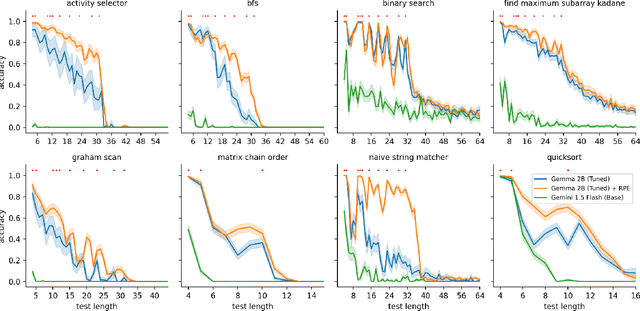
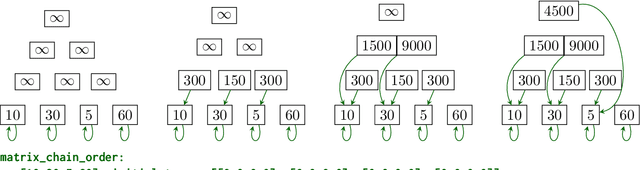
Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Mar 12, 2024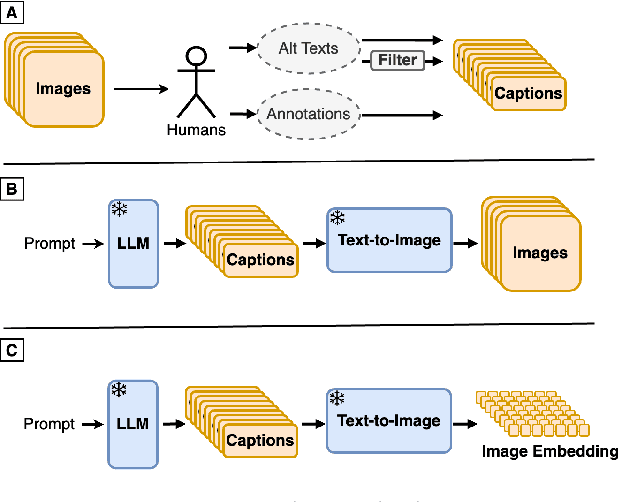
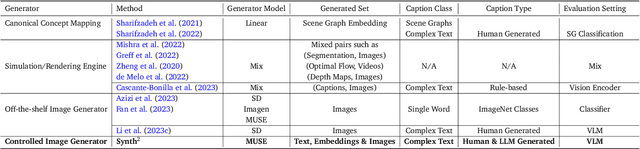


The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). We propose a novel approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs pretraining a text-to-image model to synthesize image embeddings starting from captions generated by an LLM. These synthetic pairs are then used to train a VLM. Extensive experiments demonstrate that the VLM trained with synthetic data exhibits comparable performance on image captioning, while requiring a fraction of the data used by models trained solely on human-annotated data. In particular, we outperform the baseline by 17% through augmentation with a synthetic dataset. Furthermore, we show that synthesizing in the image embedding space is 25% faster than in the pixel space. This research introduces a promising technique for generating large-scale, customizable image datasets, leading to enhanced VLM performance and wider applicability across various domains, all with improved data efficiency and resource utilization.
Improving fine-grained understanding in image-text pre-training
Jan 18, 2024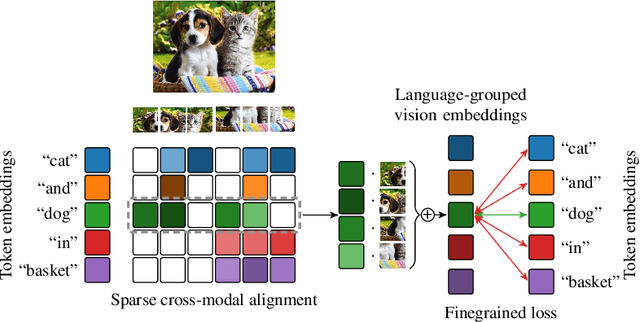
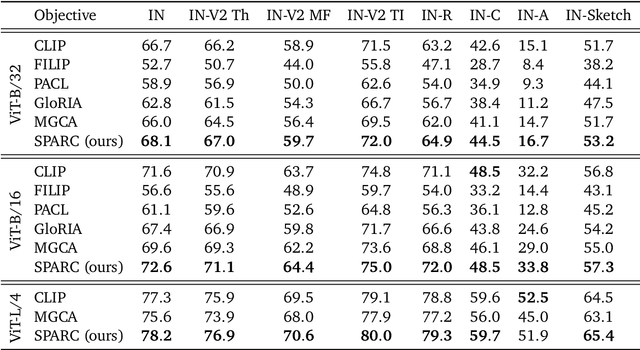
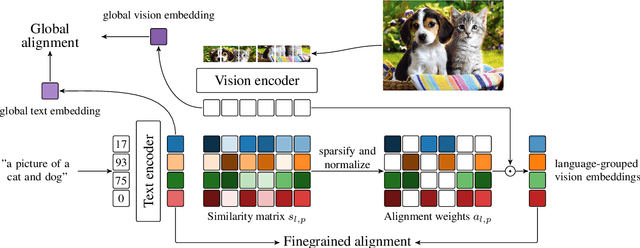
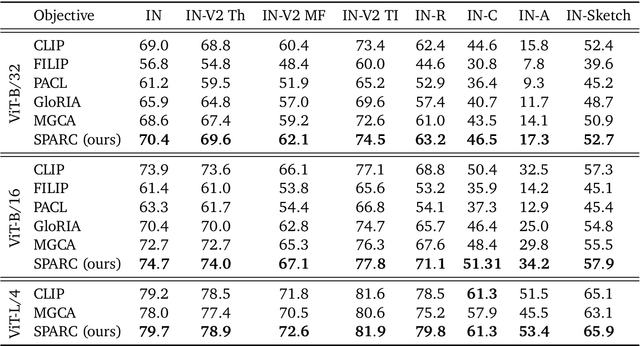
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
Unlocking the Power of Representations in Long-term Novelty-based Exploration
May 02, 2023



We introduce Robust Exploration via Clustering-based Online Density Estimation (RECODE), a non-parametric method for novelty-based exploration that estimates visitation counts for clusters of states based on their similarity in a chosen embedding space. By adapting classical clustering to the nonstationary setting of Deep RL, RECODE can efficiently track state visitation counts over thousands of episodes. We further propose a novel generalization of the inverse dynamics loss, which leverages masked transformer architectures for multi-step prediction; which in conjunction with RECODE achieves a new state-of-the-art in a suite of challenging 3D-exploration tasks in DM-Hard-8. RECODE also sets new state-of-the-art in hard exploration Atari games, and is the first agent to reach the end screen in "Pitfall!".
Neural Algorithmic Reasoning with Causal Regularisation
Feb 20, 2023



Recent work on neural algorithmic reasoning has investigated the reasoning capabilities of neural networks, effectively demonstrating they can learn to execute classical algorithms on unseen data coming from the train distribution. However, the performance of existing neural reasoners significantly degrades on out-of-distribution (OOD) test data, where inputs have larger sizes. In this work, we make an important observation: there are many \emph{different} inputs for which an algorithm will perform certain intermediate computations \emph{identically}. This insight allows us to develop data augmentation procedures that, given an algorithm's intermediate trajectory, produce inputs for which the target algorithm would have \emph{exactly} the same next trajectory step. Then, we employ a causal framework to design a corresponding self-supervised objective, and we prove that it improves the OOD generalisation capabilities of the reasoner. We evaluate our method on the CLRS algorithmic reasoning benchmark, where we show up to 3$\times$ improvements on the OOD test data.
SemPPL: Predicting pseudo-labels for better contrastive representations
Jan 12, 2023Learning from large amounts of unsupervised data and a small amount of supervision is an important open problem in computer vision. We propose a new semi-supervised learning method, Semantic Positives via Pseudo-Labels (SemPPL), that combines labelled and unlabelled data to learn informative representations. Our method extends self-supervised contrastive learning -- where representations are shaped by distinguishing whether two samples represent the same underlying datum (positives) or not (negatives) -- with a novel approach to selecting positives. To enrich the set of positives, we leverage the few existing ground-truth labels to predict the missing ones through a $k$-nearest neighbours classifier by using the learned embeddings of the labelled data. We thus extend the set of positives with datapoints having the same pseudo-label and call these semantic positives. We jointly learn the representation and predict bootstrapped pseudo-labels. This creates a reinforcing cycle. Strong initial representations enable better pseudo-label predictions which then improve the selection of semantic positives and lead to even better representations. SemPPL outperforms competing semi-supervised methods setting new state-of-the-art performance of $68.5\%$ and $76\%$ top-$1$ accuracy when using a ResNet-$50$ and training on $1\%$ and $10\%$ of labels on ImageNet, respectively. Furthermore, when using selective kernels, SemPPL significantly outperforms previous state-of-the-art achieving $72.3\%$ and $78.3\%$ top-$1$ accuracy on ImageNet with $1\%$ and $10\%$ labels, respectively, which improves absolute $+7.8\%$ and $+6.2\%$ over previous work. SemPPL also exhibits state-of-the-art performance over larger ResNet models as well as strong robustness, out-of-distribution and transfer performance.
A Generalist Neural Algorithmic Learner
Sep 22, 2022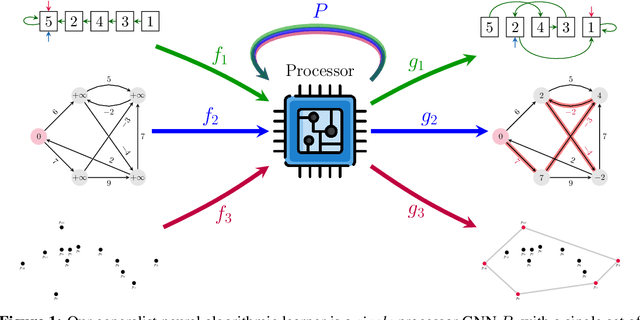
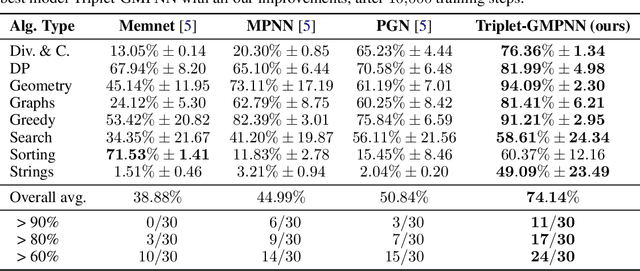
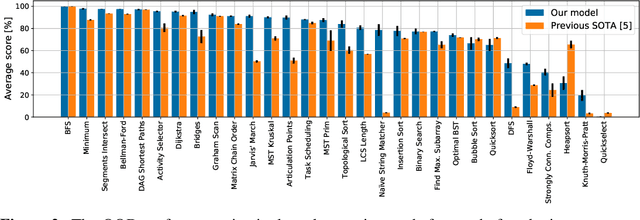
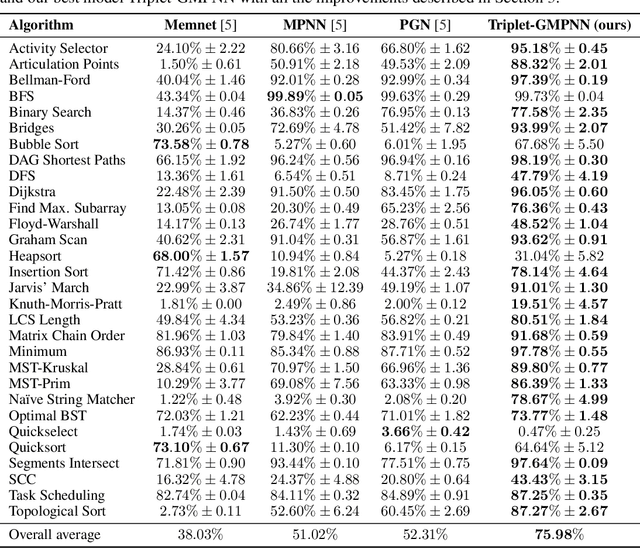
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
Human-level Atari 200x faster
Sep 15, 2022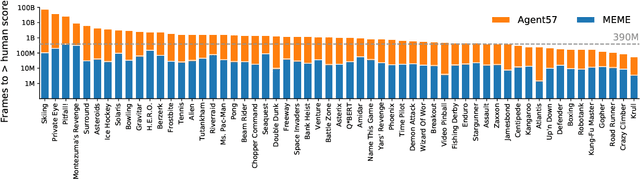
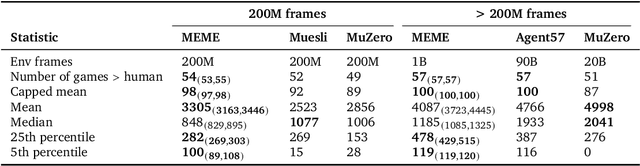
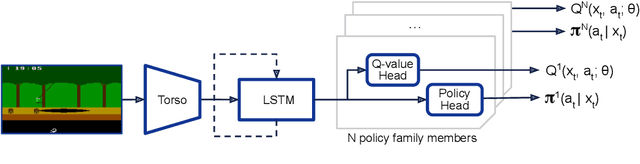

The task of building general agents that perform well over a wide range of tasks has been an important goal in reinforcement learning since its inception. The problem has been subject of research of a large body of work, with performance frequently measured by observing scores over the wide range of environments contained in the Atari 57 benchmark. Agent57 was the first agent to surpass the human benchmark on all 57 games, but this came at the cost of poor data-efficiency, requiring nearly 80 billion frames of experience to achieve. Taking Agent57 as a starting point, we employ a diverse set of strategies to achieve a 200-fold reduction of experience needed to out perform the human baseline. We investigate a range of instabilities and bottlenecks we encountered while reducing the data regime, and propose effective solutions to build a more robust and efficient agent. We also demonstrate competitive performance with high-performing methods such as Muesli and MuZero. The four key components to our approach are (1) an approximate trust region method which enables stable bootstrapping from the online network, (2) a normalisation scheme for the loss and priorities which improves robustness when learning a set of value functions with a wide range of scales, (3) an improved architecture employing techniques from NFNets in order to leverage deeper networks without the need for normalization layers, and (4) a policy distillation method which serves to smooth out the instantaneous greedy policy overtime.
The CLRS Algorithmic Reasoning Benchmark
Jun 04, 2022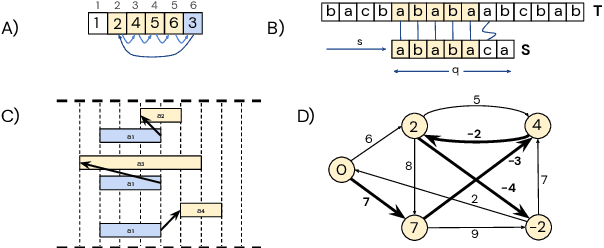
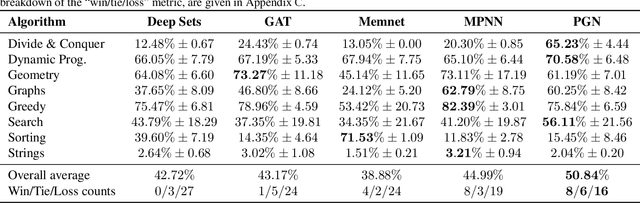

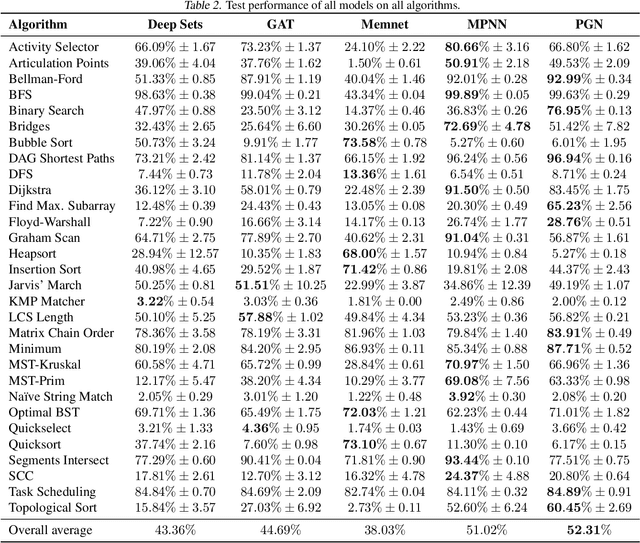
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms. Several important works have investigated whether neural networks can effectively reason like algorithms, typically by learning to execute them. The common trend in the area, however, is to generate targeted kinds of algorithmic data to evaluate specific hypotheses, making results hard to transfer across publications, and increasing the barrier of entry. To consolidate progress and work towards unified evaluation, we propose the CLRS Algorithmic Reasoning Benchmark, covering classical algorithms from the Introduction to Algorithms textbook. Our benchmark spans a variety of algorithmic reasoning procedures, including sorting, searching, dynamic programming, graph algorithms, string algorithms and geometric algorithms. We perform extensive experiments to demonstrate how several popular algorithmic reasoning baselines perform on these tasks, and consequently, highlight links to several open challenges. Our library is readily available at https://github.com/deepmind/clrs.
Retrieval-Augmented Reinforcement Learning
Mar 09, 2022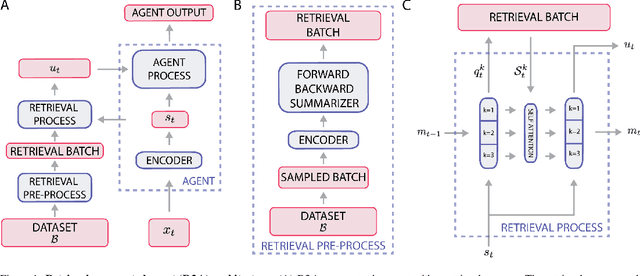

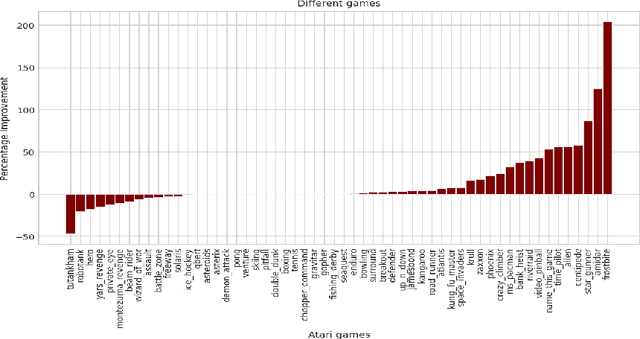
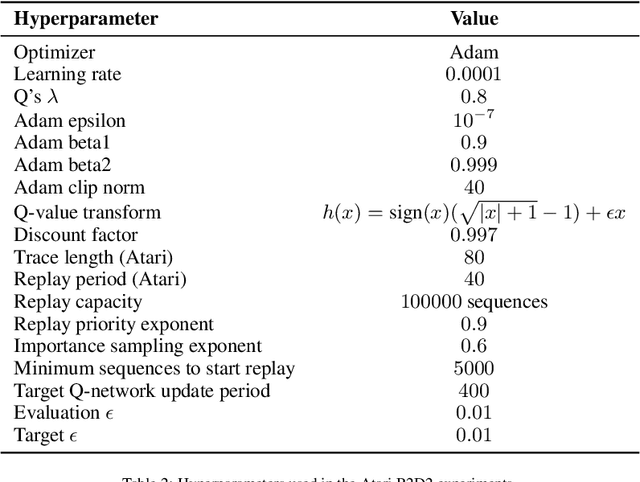
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores. We run extensive ablations to measure the contributions of the components of our proposed method.