 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Unlocking the Power of Representations in Long-term Novelty-based Exploration
May 02, 2023



We introduce Robust Exploration via Clustering-based Online Density Estimation (RECODE), a non-parametric method for novelty-based exploration that estimates visitation counts for clusters of states based on their similarity in a chosen embedding space. By adapting classical clustering to the nonstationary setting of Deep RL, RECODE can efficiently track state visitation counts over thousands of episodes. We further propose a novel generalization of the inverse dynamics loss, which leverages masked transformer architectures for multi-step prediction; which in conjunction with RECODE achieves a new state-of-the-art in a suite of challenging 3D-exploration tasks in DM-Hard-8. RECODE also sets new state-of-the-art in hard exploration Atari games, and is the first agent to reach the end screen in "Pitfall!".
BYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022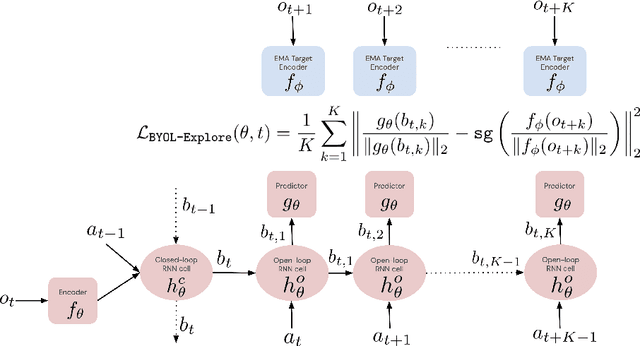
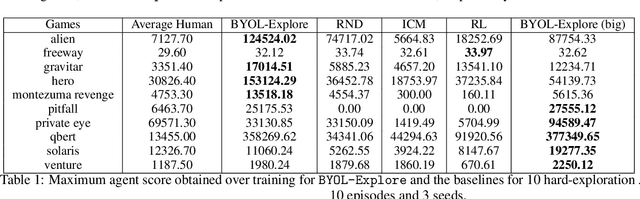

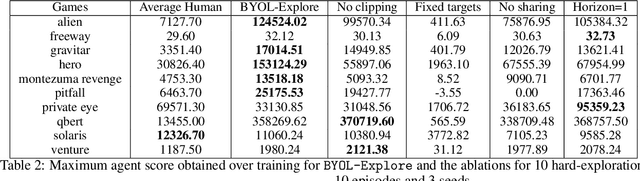
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
Geometric Entropic Exploration
Jan 07, 2021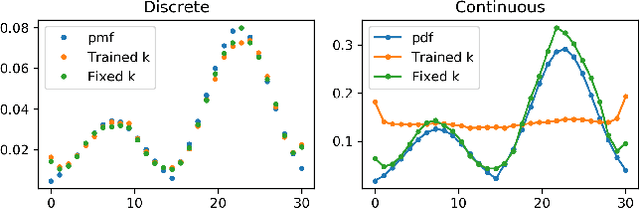
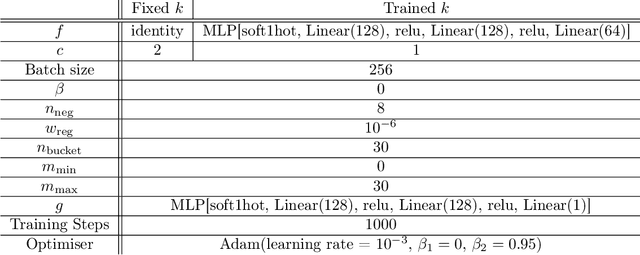
Exploration is essential for solving complex Reinforcement Learning (RL) tasks. Maximum State-Visitation Entropy (MSVE) formulates the exploration problem as a well-defined policy optimization problem whose solution aims at visiting all states as uniformly as possible. This is in contrast to standard uncertainty-based approaches where exploration is transient and eventually vanishes. However, existing approaches to MSVE are theoretically justified only for discrete state-spaces as they are oblivious to the geometry of continuous domains. We address this challenge by introducing Geometric Entropy Maximisation (GEM), a new algorithm that maximises the geometry-aware Shannon entropy of state-visits in both discrete and continuous domains. Our key theoretical contribution is casting geometry-aware MSVE exploration as a tractable problem of optimising a simple and novel noise-contrastive objective function. In our experiments, we show the efficiency of GEM in solving several RL problems with sparse rewards, compared against other deep RL exploration approaches.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020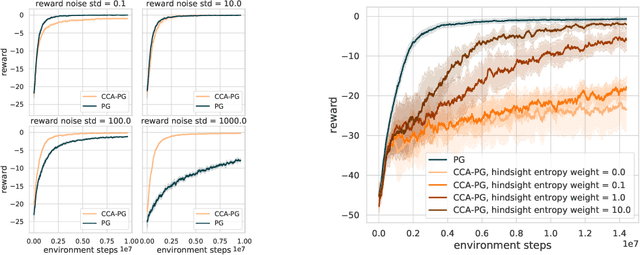
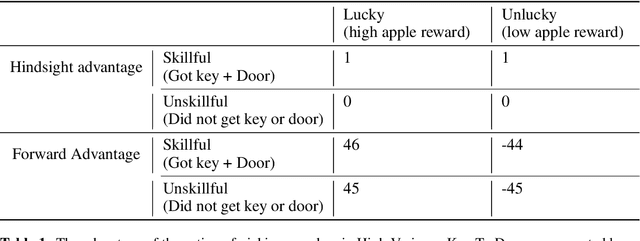

Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces
Nov 05, 2018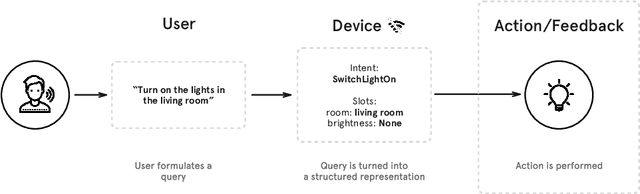

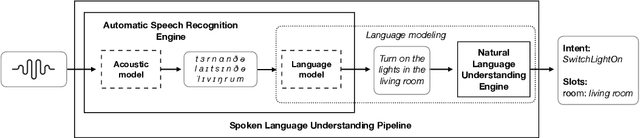
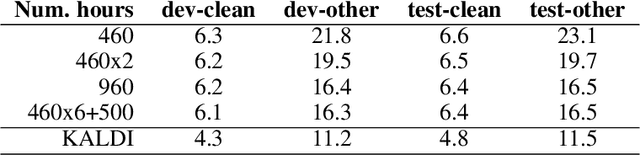
This paper presents the machine learning architecture of the Snips Voice Platform, a software solution to perform Spoken Language Understanding on microprocessors typical of IoT devices. The embedded inference is fast and accurate while enforcing privacy by design, as no personal user data is ever collected. Focusing on Automatic Speech Recognition and Natural Language Understanding, we detail our approach to training high-performance Machine Learning models that are small enough to run in real-time on small devices. Additionally, we describe a data generation procedure that provides sufficient, high-quality training data without compromising user privacy.
Spoken Language Understanding on the Edge
Oct 30, 2018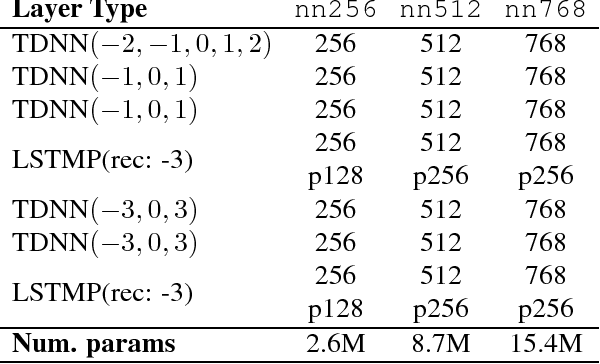

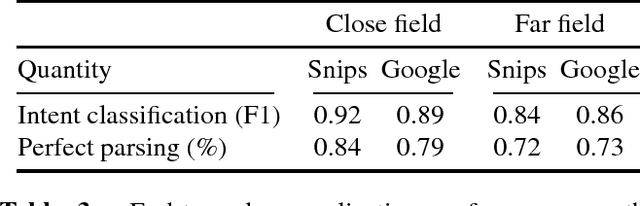
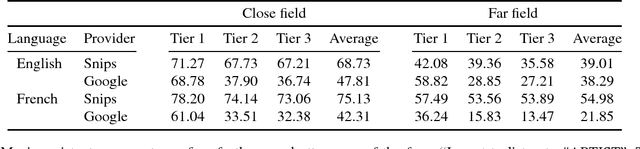
We consider the problem of performing Spoken Language Understanding (SLU) on small devices typical of IoT applications. Our contributions are twofold. First, we outline the design of an embedded, private-by-design SLU system and show that it has performance on par with cloud-based commercial solutions. Second, we release the datasets used in our experiments in the interest of reproducibility and in the hope that they can prove useful to the SLU community.
Deep Representation for Patient Visits from Electronic Health Records
Mar 26, 2018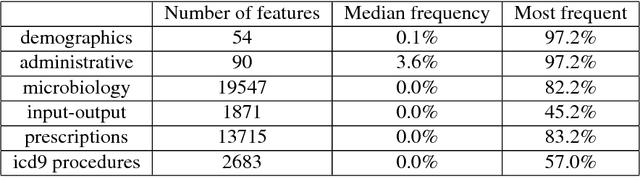
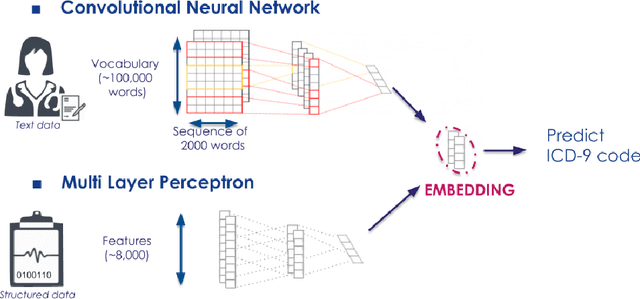
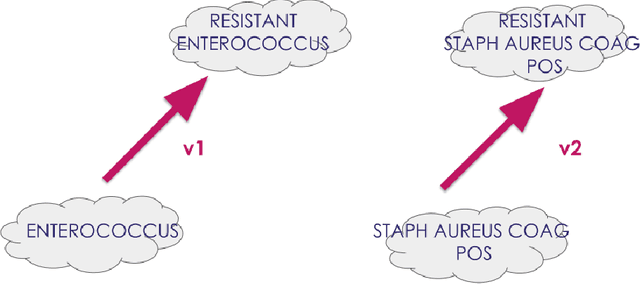
We show how to learn low-dimensional representations (embeddings) of patient visits from the corresponding electronic health record (EHR) where International Classification of Diseases (ICD) diagnosis codes are removed. We expect that these embeddings will be useful for the construction of predictive statistical models anticipated to drive personalized medicine and improve healthcare quality. These embeddings are learned using a deep neural network trained to predict ICD diagnosis categories. We show that our embeddings capture relevant clinical informations and can be used directly as input to standard machine learning algorithms like multi-output classifiers for ICD code prediction. We also show that important medical informations correspond to particular directions in our embedding space.
Spectral Inference Methods on Sparse Graphs: Theory and Applications
Oct 14, 2016
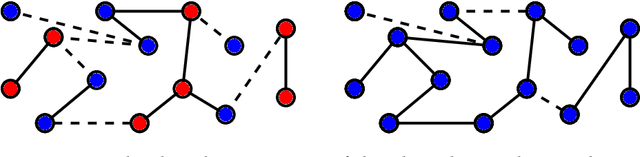
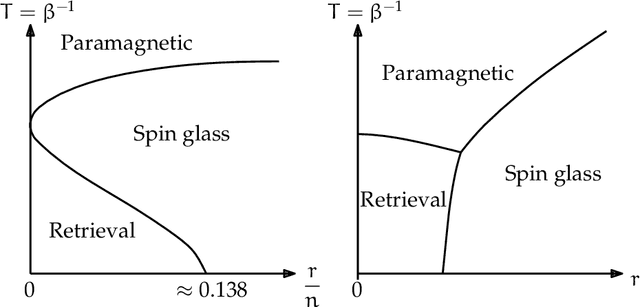
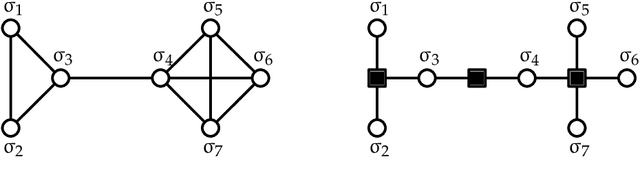
In an era of unprecedented deluge of (mostly unstructured) data, graphs are proving more and more useful, across the sciences, as a flexible abstraction to capture complex relationships between complex objects. One of the main challenges arising in the study of such networks is the inference of macroscopic, large-scale properties affecting a large number of objects, based solely on the microscopic interactions between their elementary constituents. Statistical physics, precisely created to recover the macroscopic laws of thermodynamics from an idealized model of interacting particles, provides significant insight to tackle such complex networks. In this dissertation, we use methods derived from the statistical physics of disordered systems to design and study new algorithms for inference on graphs. Our focus is on spectral methods, based on certain eigenvectors of carefully chosen matrices, and sparse graphs, containing only a small amount of information. We develop an original theory of spectral inference based on a relaxation of various mean-field free energy optimizations. Our approach is therefore fully probabilistic, and contrasts with more traditional motivations based on the optimization of a cost function. We illustrate the efficiency of our approach on various problems, including community detection, randomized similarity-based clustering, and matrix completion.
Fast Randomized Semi-Supervised Clustering
Oct 09, 2016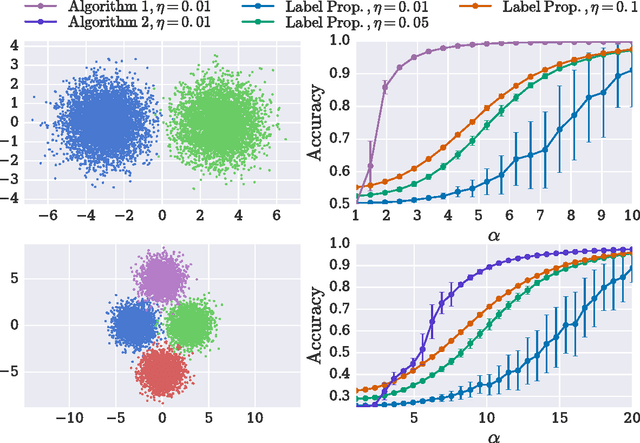
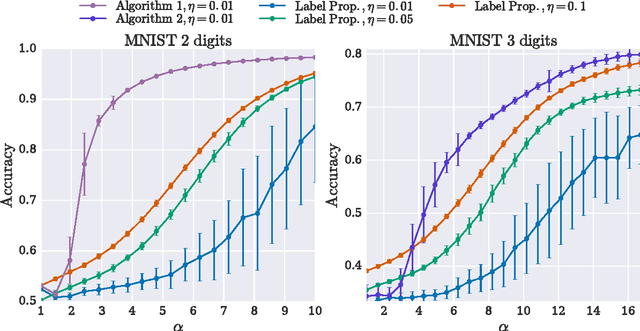
We consider the problem of clustering partially labeled data from a minimal number of randomly chosen pairwise comparisons between the items. We introduce an efficient local algorithm based on a power iteration of the non-backtracking operator and study its performance on a simple model. For the case of two clusters, we give bounds on the classification error and show that a small error can be achieved from $O(n)$ randomly chosen measurements, where $n$ is the number of items in the dataset. Our algorithm is therefore efficient both in terms of time and space complexities. We also investigate numerically the performance of the algorithm on synthetic and real world data.