 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-Footprint Open-Vocabulary Keyword Spotting with Quantized LSTM Networks
Feb 25, 2020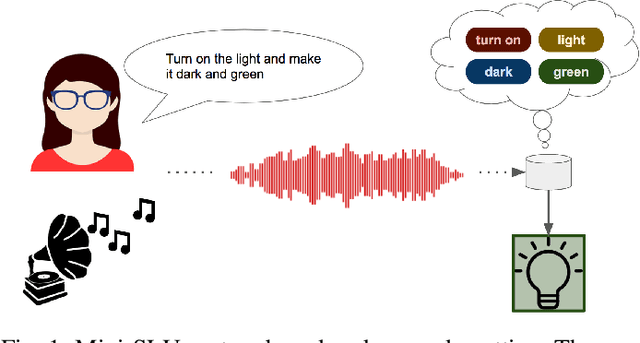
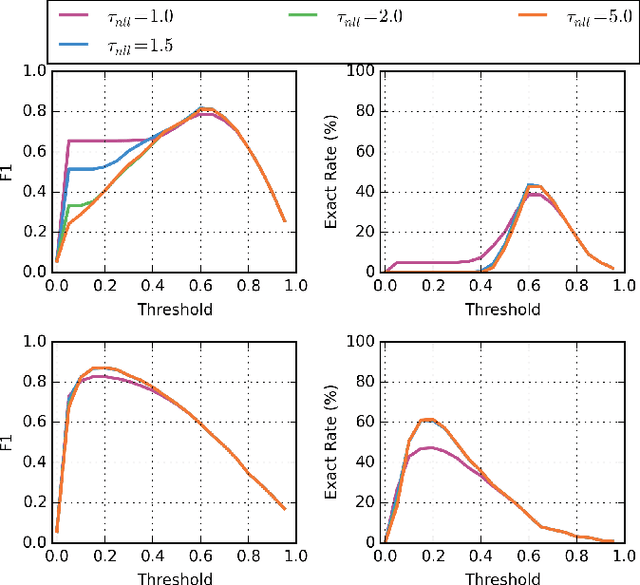
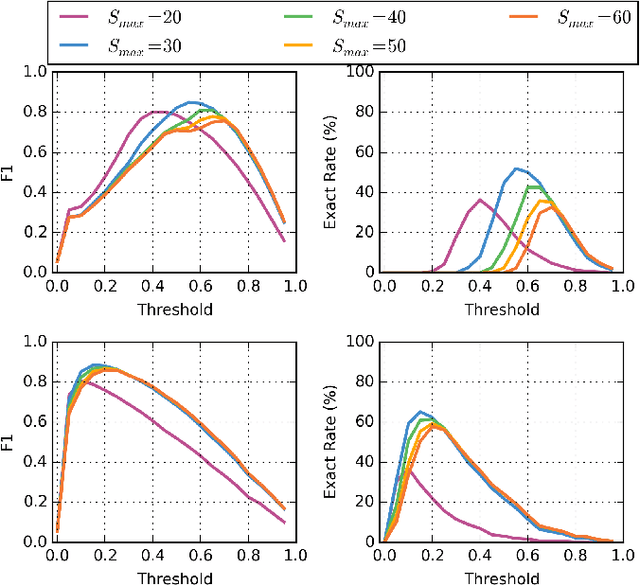
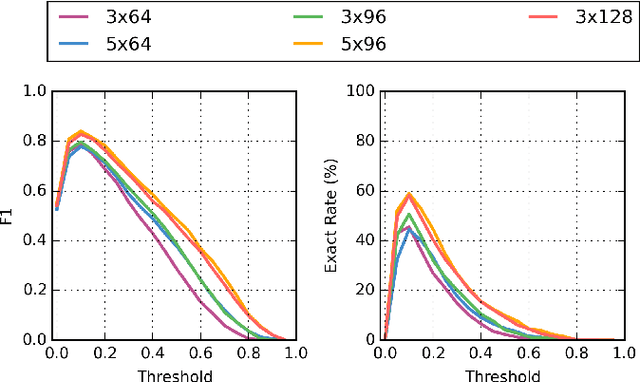
We explore a keyword-based spoken language understanding system, in which the intent of the user can directly be derived from the detection of a sequence of keywords in the query. In this paper, we focus on an open-vocabulary keyword spotting method, allowing the user to define their own keywords without having to retrain the whole model. We describe the different design choices leading to a fast and small-footprint system, able to run on tiny devices, for any arbitrary set of user-defined keywords, without training data specific to those keywords. The model, based on a quantized long short-term memory (LSTM) neural network, trained with connectionist temporal classification (CTC), weighs less than 500KB. Our approach takes advantage of some properties of the predictions of CTC-trained networks to calibrate the confidence scores and implement a fast detection algorithm. The proposed system outperforms a standard keyword-filler model approach.
Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces
Nov 05, 2018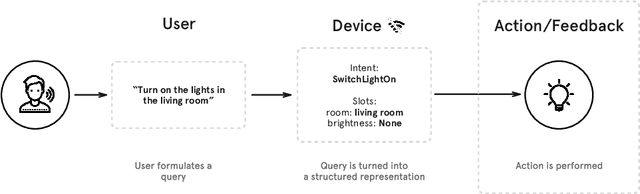

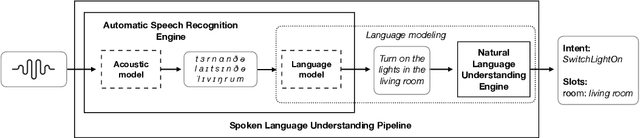
This paper presents the machine learning architecture of the Snips Voice Platform, a software solution to perform Spoken Language Understanding on microprocessors typical of IoT devices. The embedded inference is fast and accurate while enforcing privacy by design, as no personal user data is ever collected. Focusing on Automatic Speech Recognition and Natural Language Understanding, we detail our approach to training high-performance Machine Learning models that are small enough to run in real-time on small devices. Additionally, we describe a data generation procedure that provides sufficient, high-quality training data without compromising user privacy.
Spoken Language Understanding on the Edge
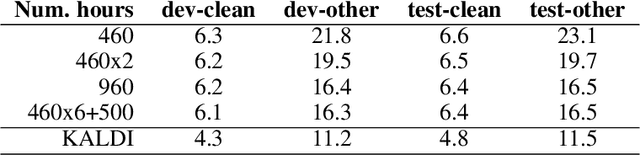
Oct 30, 2018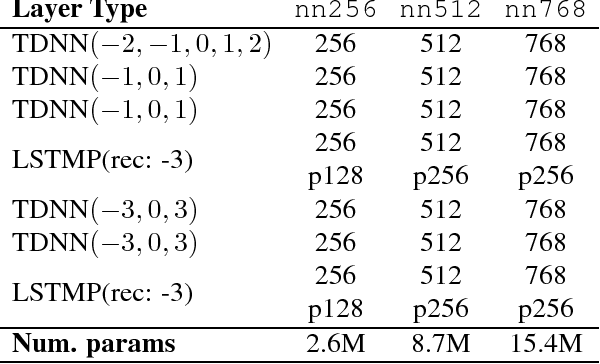

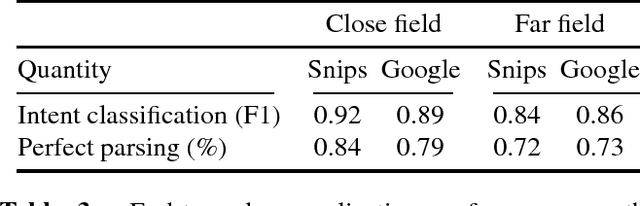
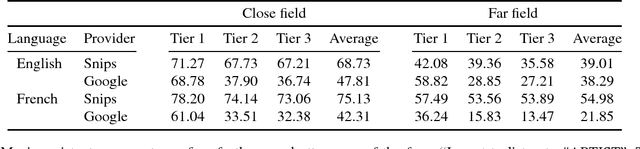
We consider the problem of performing Spoken Language Understanding (SLU) on small devices typical of IoT applications. Our contributions are twofold. First, we outline the design of an embedded, private-by-design SLU system and show that it has performance on par with cloud-based commercial solutions. Second, we release the datasets used in our experiments in the interest of reproducibility and in the hope that they can prove useful to the SLU community.
Scan, Attend and Read: End-to-End Handwritten Paragraph Recognition with MDLSTM Attention
Aug 23, 2016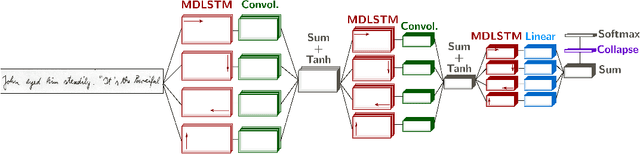

We present an attention-based model for end-to-end handwriting recognition. Our system does not require any segmentation of the input paragraph. The model is inspired by the differentiable attention models presented recently for speech recognition, image captioning or translation. The main difference is the covert and overt attention, implemented as a multi-dimensional LSTM network. Our principal contribution towards handwriting recognition lies in the automatic transcription without a prior segmentation into lines, which was crucial in previous approaches. To the best of our knowledge this is the first successful attempt of end-to-end multi-line handwriting recognition. We carried out experiments on the well-known IAM Database. The results are encouraging and bring hope to perform full paragraph transcription in the near future.
Joint Line Segmentation and Transcription for End-to-End Handwritten Paragraph Recognition
Apr 28, 2016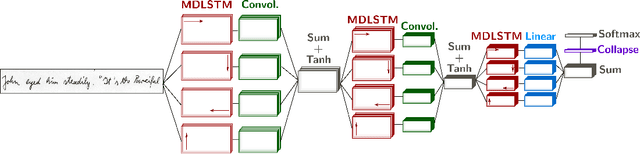

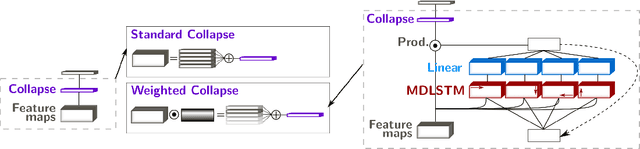
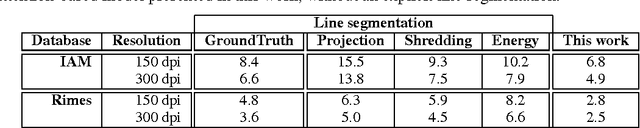
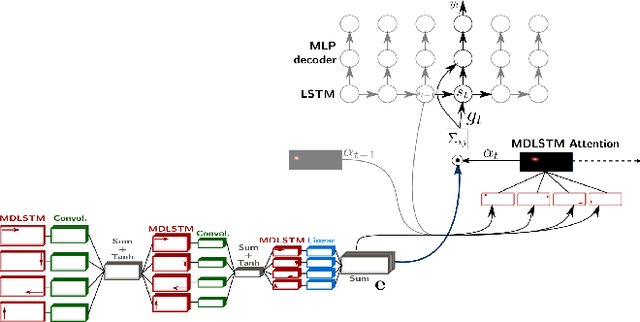
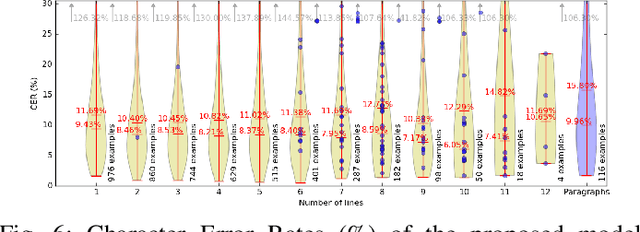
Offline handwriting recognition systems require cropped text line images for both training and recognition. On the one hand, the annotation of position and transcript at line level is costly to obtain. On the other hand, automatic line segmentation algorithms are prone to errors, compromising the subsequent recognition. In this paper, we propose a modification of the popular and efficient multi-dimensional long short-term memory recurrent neural networks (MDLSTM-RNNs) to enable end-to-end processing of handwritten paragraphs. More particularly, we replace the collapse layer transforming the two-dimensional representation into a sequence of predictions by a recurrent version which can recognize one line at a time. In the proposed model, a neural network performs a kind of implicit line segmentation by computing attention weights on the image representation. The experiments on paragraphs of Rimes and IAM database yield results that are competitive with those of networks trained at line level, and constitute a significant step towards end-to-end transcription of full documents.
Dropout improves Recurrent Neural Networks for Handwriting Recognition
Mar 10, 2014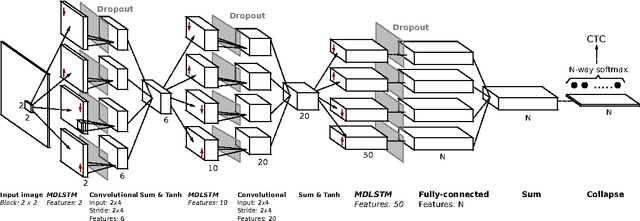
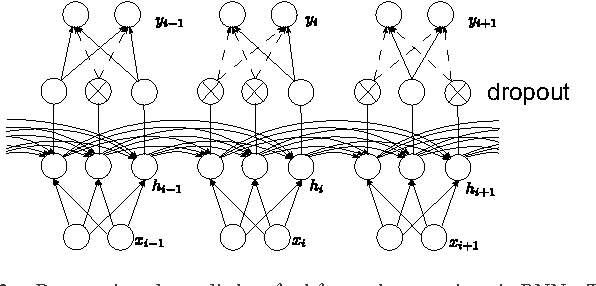
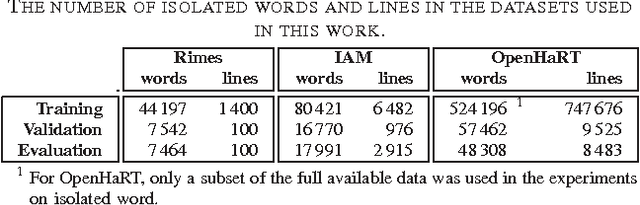
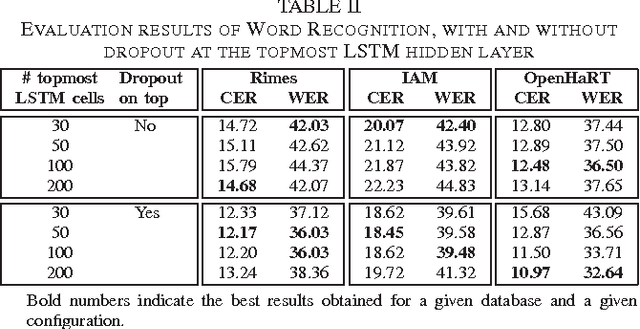
Recurrent neural networks (RNNs) with Long Short-Term memory cells currently hold the best known results in unconstrained handwriting recognition. We show that their performance can be greatly improved using dropout - a recently proposed regularization method for deep architectures. While previous works showed that dropout gave superior performance in the context of convolutional networks, it had never been applied to RNNs. In our approach, dropout is carefully used in the network so that it does not affect the recurrent connections, hence the power of RNNs in modeling sequence is preserved. Extensive experiments on a broad range of handwritten databases confirm the effectiveness of dropout on deep architectures even when the network mainly consists of recurrent and shared connections.