 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient keyword spotting using dilated convolutions and gating
Nov 19, 2018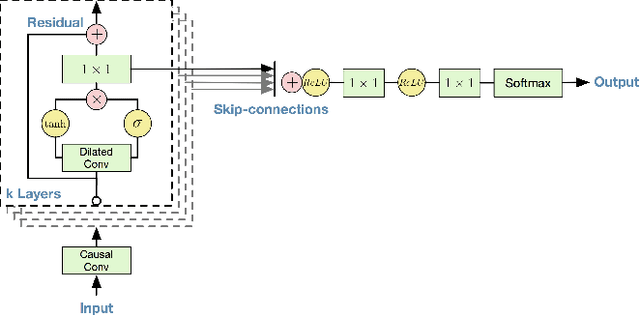
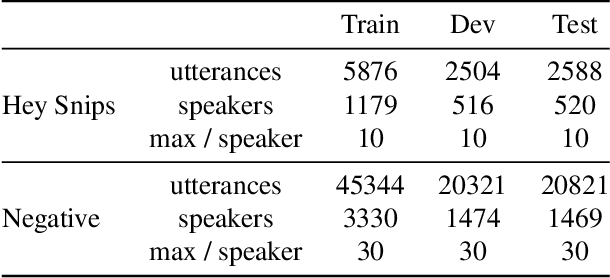
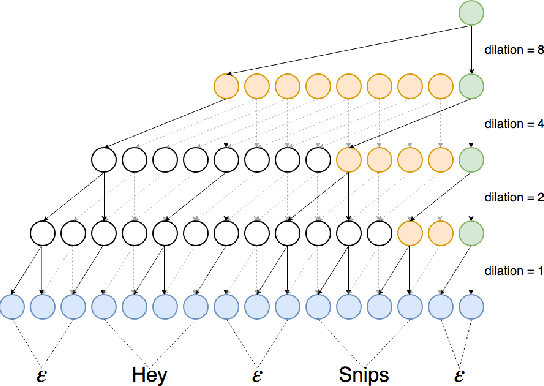
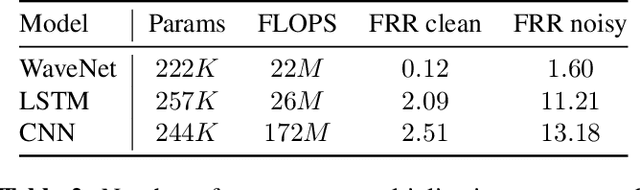
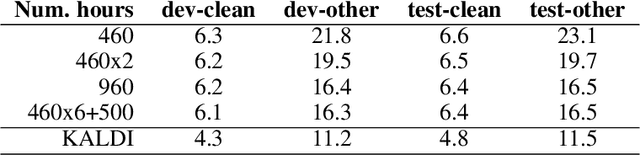
We explore the application of end-to-end stateless temporal modeling to small-footprint keyword spotting as opposed to recurrent networks that model long-term temporal dependencies using internal states. We propose a model inspired by the recent success of dilated convolutions in sequence modeling applications, allowing to train deeper architectures in resource-constrained configurations. Gated activations and residual connections are also added, following a similar configuration to WaveNet. In addition, we apply a custom target labeling that back-propagates loss from specific frames of interest, therefore yielding higher accuracy and only requiring to detect the end of the keyword. Our experimental results show that our model outperforms a max-pooling loss trained recurrent neural network using LSTM cells, with a significant decrease in false rejection rate. The underlying dataset - "Hey Snips" utterances recorded by over 2.2K different speakers - has been made publicly available to establish an open reference for wake-word detection.
Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces
Nov 05, 2018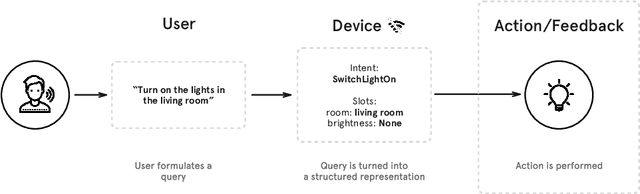

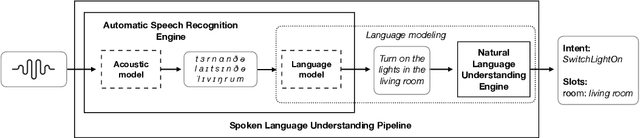
This paper presents the machine learning architecture of the Snips Voice Platform, a software solution to perform Spoken Language Understanding on microprocessors typical of IoT devices. The embedded inference is fast and accurate while enforcing privacy by design, as no personal user data is ever collected. Focusing on Automatic Speech Recognition and Natural Language Understanding, we detail our approach to training high-performance Machine Learning models that are small enough to run in real-time on small devices. Additionally, we describe a data generation procedure that provides sufficient, high-quality training data without compromising user privacy.
Federated Learning for Keyword Spotting
Oct 31, 2018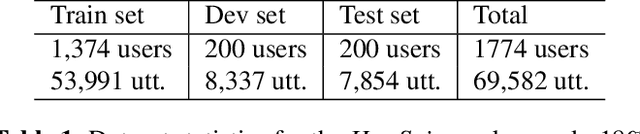
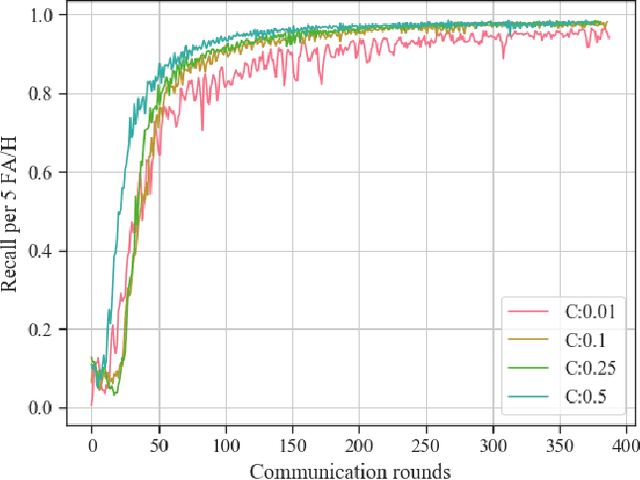

We propose a practical approach based on federated learning to solve out-of-domain issues with continuously running embedded speech-based models such as wake word detectors. We conduct an extensive empirical study of the federated averaging algorithm for the "Hey Snips" wake word based on a crowdsourced dataset that mimics a federation of wake word users. We empirically demonstrate that using an adaptive averaging strategy inspired from Adam in place of standard weighted model averaging highly reduces the number of communication rounds required to reach our target performance. The associated upstream communication costs per user are estimated at 8 MB, which is a reasonable in the context of smart home voice assistants. Additionally, the dataset used for these experiments is being open sourced with the aim of fostering further transparent research in the application of federated learning to speech data.
Spoken Language Understanding on the Edge
Oct 30, 2018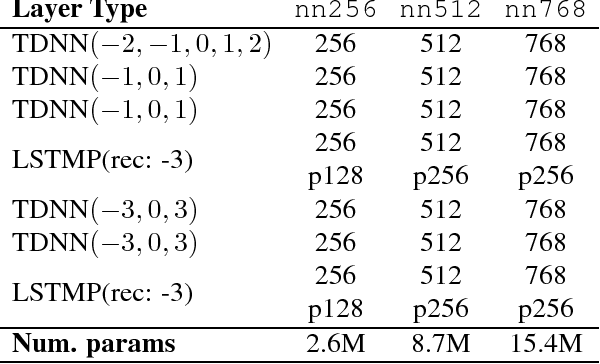

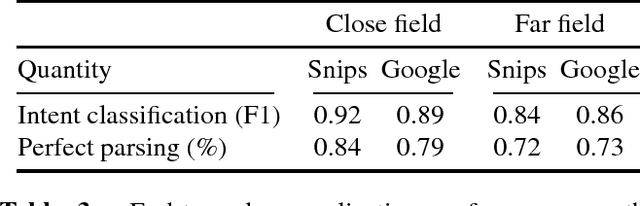
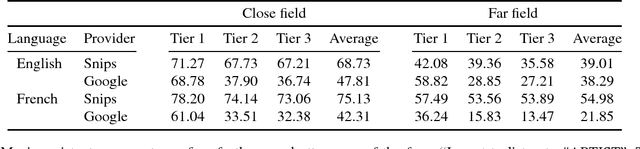
We consider the problem of performing Spoken Language Understanding (SLU) on small devices typical of IoT applications. Our contributions are twofold. First, we outline the design of an embedded, private-by-design SLU system and show that it has performance on par with cloud-based commercial solutions. Second, we release the datasets used in our experiments in the interest of reproducibility and in the hope that they can prove useful to the SLU community.