 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall footprint Text-Independent Speaker Verification for Embedded Systems
Nov 03, 2020
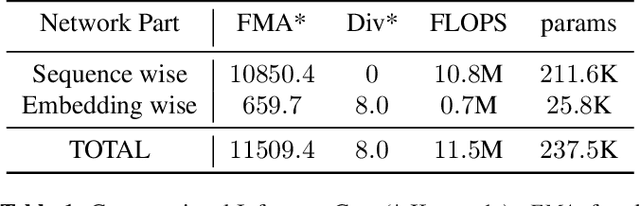

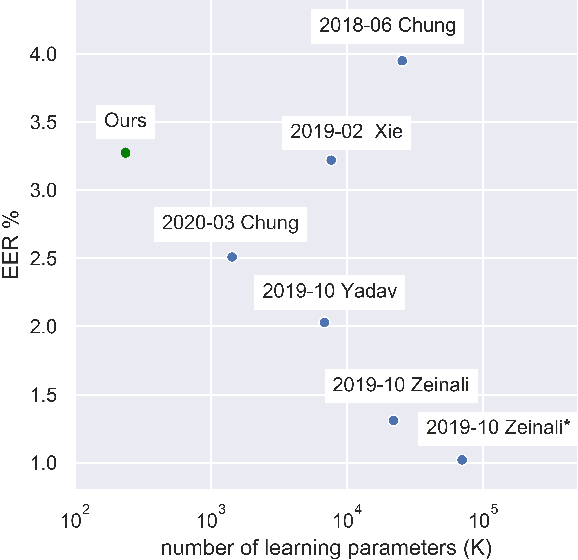
Deep neural network approaches to speaker verification have proven successful, but typical computational requirements of State-Of-The-Art (SOTA) systems make them unsuited for embedded applications. In this work, we present a two-stage model architecture orders of magnitude smaller than common solutions (237.5K learning parameters, 11.5MFLOPS) reaching a competitive result of 3.31% Equal Error Rate (EER) on the well established VoxCeleb1 verification test set. We demonstrate the possibility of running our solution on small devices typical of IoT systems such as the Raspberry Pi 3B with a latency smaller than 200ms on a 5s long utterance. Additionally, we evaluate our model on the acoustically challenging VOiCES corpus. We report a limited increase in EER of 2.6 percentage points with respect to the best scoring model of the 2019 VOiCES from a Distance Challenge, against a reduction of 25.6 times in the number of learning parameters.
Efficient keyword spotting using dilated convolutions and gating
Nov 19, 2018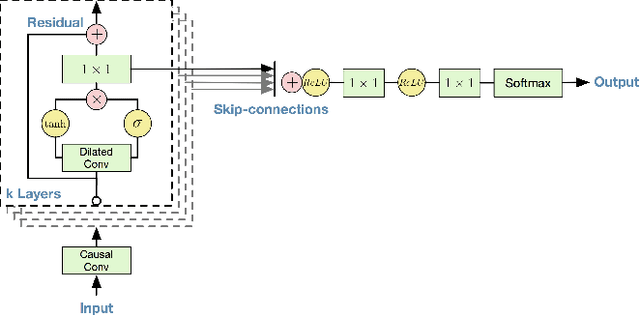
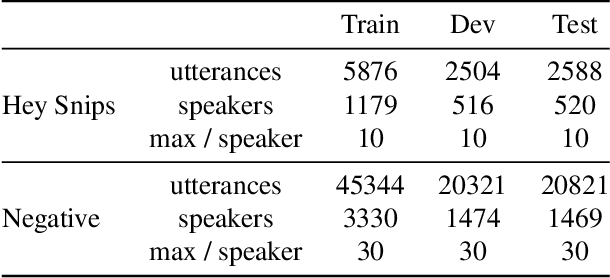
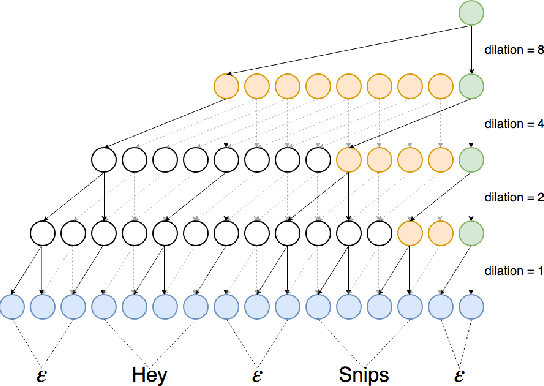
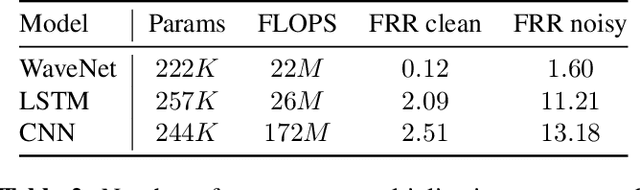
We explore the application of end-to-end stateless temporal modeling to small-footprint keyword spotting as opposed to recurrent networks that model long-term temporal dependencies using internal states. We propose a model inspired by the recent success of dilated convolutions in sequence modeling applications, allowing to train deeper architectures in resource-constrained configurations. Gated activations and residual connections are also added, following a similar configuration to WaveNet. In addition, we apply a custom target labeling that back-propagates loss from specific frames of interest, therefore yielding higher accuracy and only requiring to detect the end of the keyword. Our experimental results show that our model outperforms a max-pooling loss trained recurrent neural network using LSTM cells, with a significant decrease in false rejection rate. The underlying dataset - "Hey Snips" utterances recorded by over 2.2K different speakers - has been made publicly available to establish an open reference for wake-word detection.