 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioned Text Generation with Transfer for Closed-Domain Dialogue Systems
Nov 03, 2020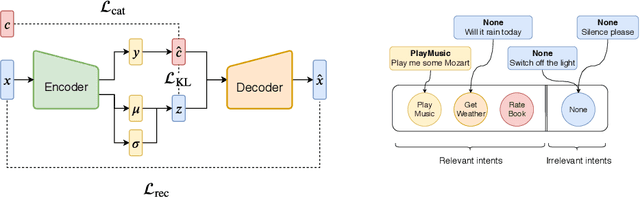
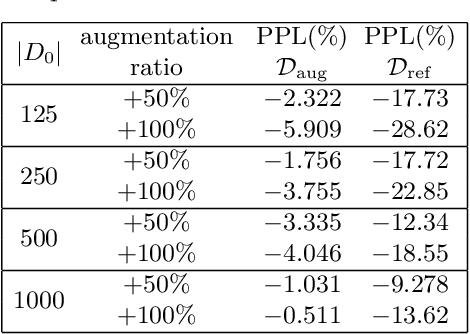


Scarcity of training data for task-oriented dialogue systems is a well known problem that is usually tackled with costly and time-consuming manual data annotation. An alternative solution is to rely on automatic text generation which, although less accurate than human supervision, has the advantage of being cheap and fast. Our contribution is twofold. First we show how to optimally train and control the generation of intent-specific sentences using a conditional variational autoencoder. Then we introduce a new protocol called query transfer that allows to leverage a large unlabelled dataset, possibly containing irrelevant queries, to extract relevant information. Comparison with two different baselines shows that this method, in the appropriate regime, consistently improves the diversity of the generated queries without compromising their quality. We also demonstrate the effectiveness of our generation method as a data augmentation technique for language modelling tasks.
Conditioned Query Generation for Task-Oriented Dialogue Systems
Nov 09, 2019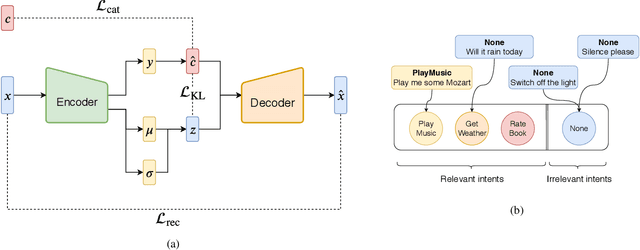

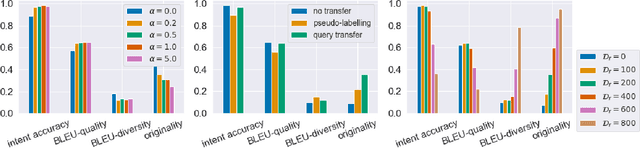

Scarcity of training data for task-oriented dialogue systems is a well known problem that is usually tackled with costly and time-consuming manual data annotation. An alternative solution is to rely on automatic text generation which, although less accurate than human supervision, has the advantage of being cheap and fast. In this paper we propose a novel controlled data generation method that could be used as a training augmentation framework for closed-domain dialogue. Our contribution is twofold. First we show how to optimally train and control the generation of intent-specific sentences using a conditional variational autoencoder. Then we introduce a novel protocol called query transfer that allows to leverage a broad, unlabelled dataset to extract relevant information. Comparison with two different baselines shows that our method, in the appropriate regime, consistently improves the diversity of the generated queries without compromising their quality.
Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces
Nov 05, 2018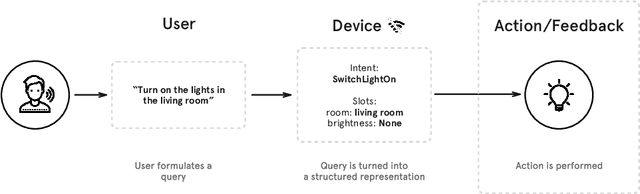

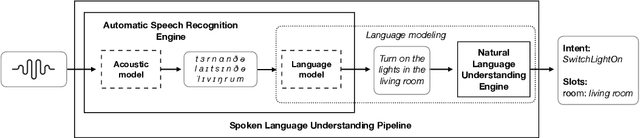
This paper presents the machine learning architecture of the Snips Voice Platform, a software solution to perform Spoken Language Understanding on microprocessors typical of IoT devices. The embedded inference is fast and accurate while enforcing privacy by design, as no personal user data is ever collected. Focusing on Automatic Speech Recognition and Natural Language Understanding, we detail our approach to training high-performance Machine Learning models that are small enough to run in real-time on small devices. Additionally, we describe a data generation procedure that provides sufficient, high-quality training data without compromising user privacy.
Spoken Language Understanding on the Edge
Oct 30, 2018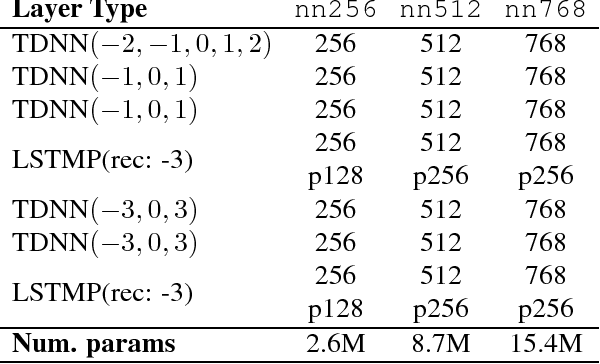

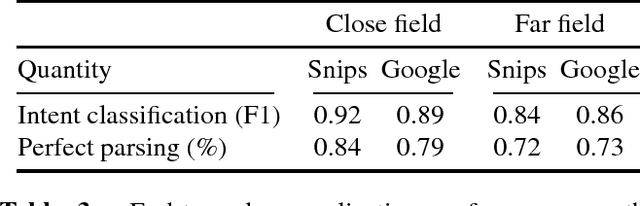
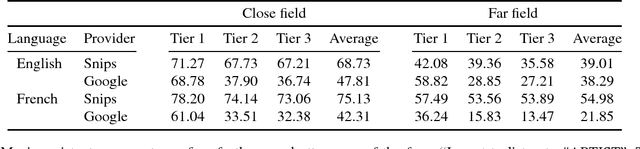
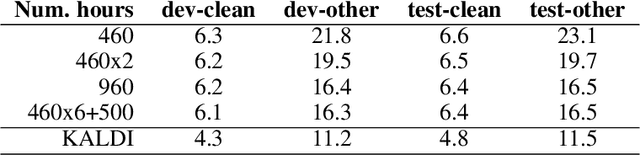
We consider the problem of performing Spoken Language Understanding (SLU) on small devices typical of IoT applications. Our contributions are twofold. First, we outline the design of an embedded, private-by-design SLU system and show that it has performance on par with cloud-based commercial solutions. Second, we release the datasets used in our experiments in the interest of reproducibility and in the hope that they can prove useful to the SLU community.