 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioned Query Generation for Task-Oriented Dialogue Systems
Paper and Code
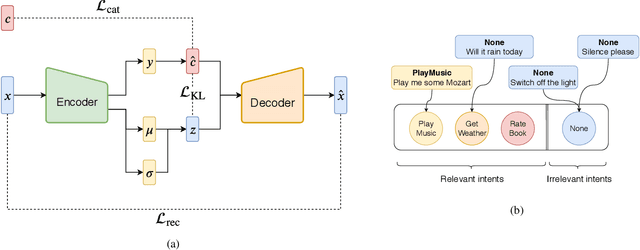

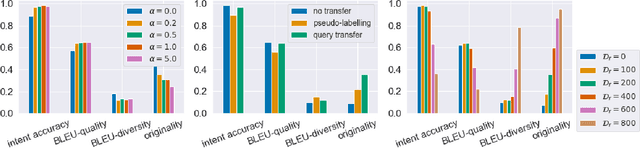

Scarcity of training data for task-oriented dialogue systems is a well known problem that is usually tackled with costly and time-consuming manual data annotation. An alternative solution is to rely on automatic text generation which, although less accurate than human supervision, has the advantage of being cheap and fast. In this paper we propose a novel controlled data generation method that could be used as a training augmentation framework for closed-domain dialogue. Our contribution is twofold. First we show how to optimally train and control the generation of intent-specific sentences using a conditional variational autoencoder. Then we introduce a novel protocol called query transfer that allows to leverage a broad, unlabelled dataset to extract relevant information. Comparison with two different baselines shows that our method, in the appropriate regime, consistently improves the diversity of the generated queries without compromising their quality.