 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant MuZero
Feb 09, 2023


Deep reinforcement learning repeatedly succeeds in closed, well-defined domains such as games (Chess, Go, StarCraft). The next frontier is real-world scenarios, where setups are numerous and varied. For this, agents need to learn the underlying rules governing the environment, so as to robustly generalise to conditions that differ from those they were trained on. Model-based reinforcement learning algorithms, such as the highly successful MuZero, aim to accomplish this by learning a world model. However, leveraging a world model has not consistently shown greater generalisation capabilities compared to model-free alternatives. In this work, we propose improving the data efficiency and generalisation capabilities of MuZero by explicitly incorporating the symmetries of the environment in its world-model architecture. We prove that, so long as the neural networks used by MuZero are equivariant to a particular symmetry group acting on the environment, the entirety of MuZero's action-selection algorithm will also be equivariant to that group. We evaluate Equivariant MuZero on procedurally-generated MiniPacman and on Chaser from the ProcGen suite: training on a set of mazes, and then testing on unseen rotated versions, demonstrating the benefits of equivariance. Further, we verify that our performance improvements hold even when only some of the components of Equivariant MuZero obey strict equivariance, which highlights the robustness of our construction.
Investigating the role of model-based learning in exploration and transfer
Feb 08, 2023State of the art reinforcement learning has enabled training agents on tasks of ever increasing complexity. However, the current paradigm tends to favor training agents from scratch on every new task or on collections of tasks with a view towards generalizing to novel task configurations. The former suffers from poor data efficiency while the latter is difficult when test tasks are out-of-distribution. Agents that can effectively transfer their knowledge about the world pose a potential solution to these issues. In this paper, we investigate transfer learning in the context of model-based agents. Specifically, we aim to understand when exactly environment models have an advantage and why. We find that a model-based approach outperforms controlled model-free baselines for transfer learning. Through ablations, we show that both the policy and dynamics model learnt through exploration matter for successful transfer. We demonstrate our results across three domains which vary in their requirements for transfer: in-distribution procedural (Crafter), in-distribution identical (RoboDesk), and out-of-distribution (Meta-World). Our results show that intrinsic exploration combined with environment models present a viable direction towards agents that are self-supervised and able to generalize to novel reward functions.
Laser: Latent Set Representations for 3D Generative Modeling
Jan 13, 2023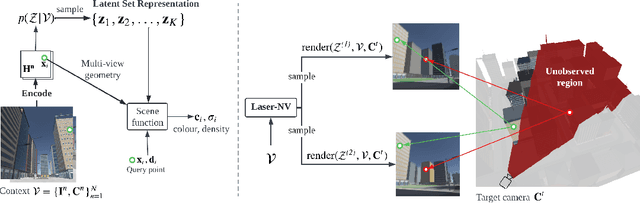
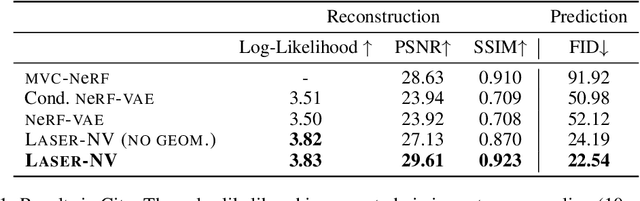


NeRF provides unparalleled fidelity of novel view synthesis: rendering a 3D scene from an arbitrary viewpoint. NeRF requires training on a large number of views that fully cover a scene, which limits its applicability. While these issues can be addressed by learning a prior over scenes in various forms, previous approaches have been either applied to overly simple scenes or struggling to render unobserved parts. We introduce Laser-NV: a generative model which achieves high modelling capacity, and which is based on a set-valued latent representation modelled by normalizing flows. Similarly to previous amortized approaches, Laser-NV learns structure from multiple scenes and is capable of fast, feed-forward inference from few views. To encourage higher rendering fidelity and consistency with observed views, Laser-NV further incorporates a geometry-informed attention mechanism over the observed views. Laser-NV further produces diverse and plausible completions of occluded parts of a scene while remaining consistent with observations. Laser-NV shows state-of-the-art novel-view synthesis quality when evaluated on ShapeNet and on a novel simulated City dataset, which features high uncertainty in the unobserved regions of the scene.
Large-Scale Retrieval for Reinforcement Learning
Jun 10, 2022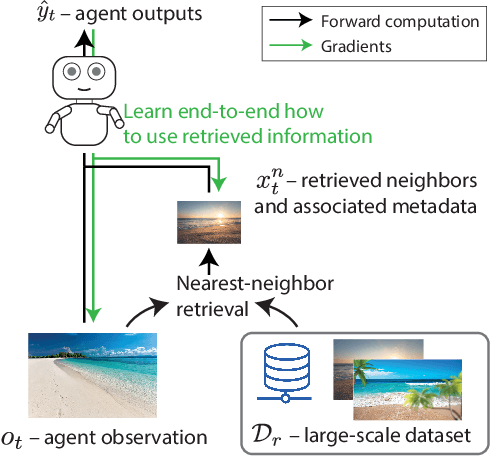
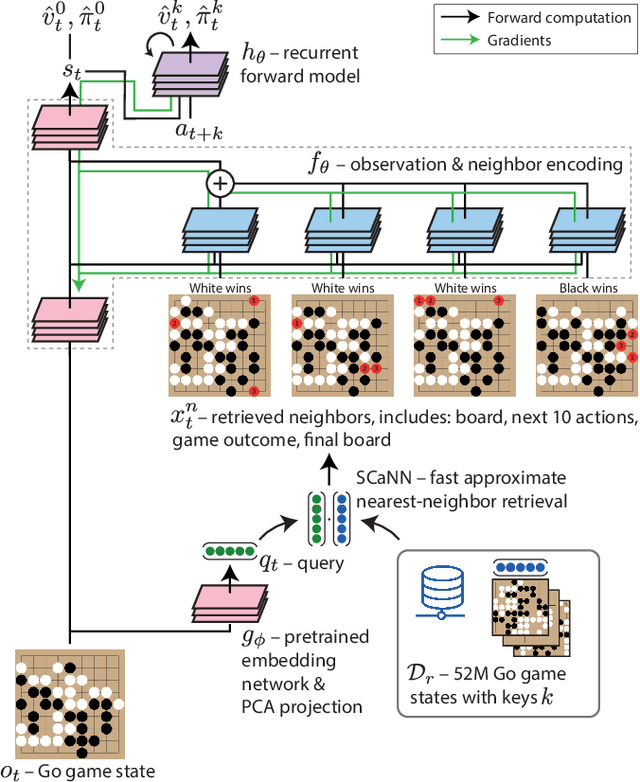
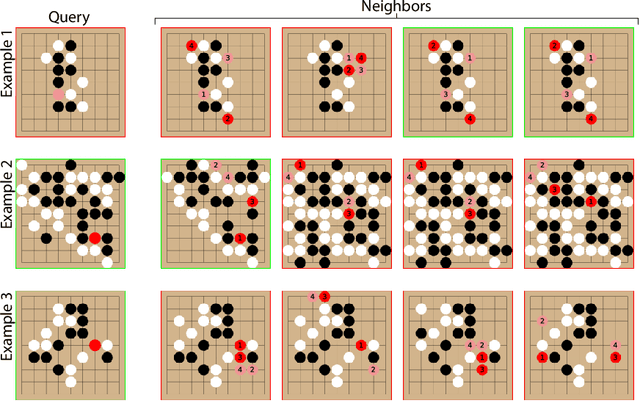
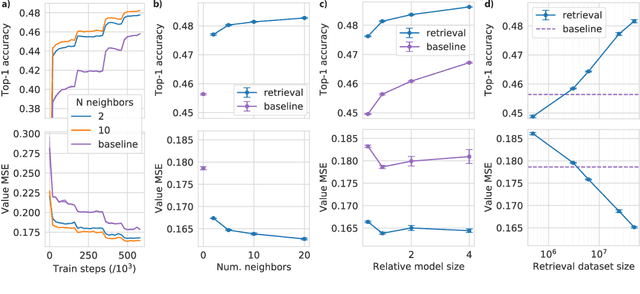
Effective decision making involves flexibly relating past experiences and relevant contextual information to a novel situation. In deep reinforcement learning, the dominant paradigm is for an agent to amortise information that helps decision-making into its network weights via gradient descent on training losses. Here, we pursue an alternative approach in which agents can utilise large-scale context-sensitive database lookups to support their parametric computations. This allows agents to directly learn in an end-to-end manner to utilise relevant information to inform their outputs. In addition, new information can be attended to by the agent, without retraining, by simply augmenting the retrieval dataset. We study this approach in Go, a challenging game for which the vast combinatorial state space privileges generalisation over direct matching to past experiences. We leverage fast, approximate nearest neighbor techniques in order to retrieve relevant data from a set of tens of millions of expert demonstration states. Attending to this information provides a significant boost to prediction accuracy and game-play performance over simply using these demonstrations as training trajectories, providing a compelling demonstration of the value of large-scale retrieval in reinforcement learning agents.
Procedural Generalization by Planning with Self-Supervised World Models
Nov 02, 2021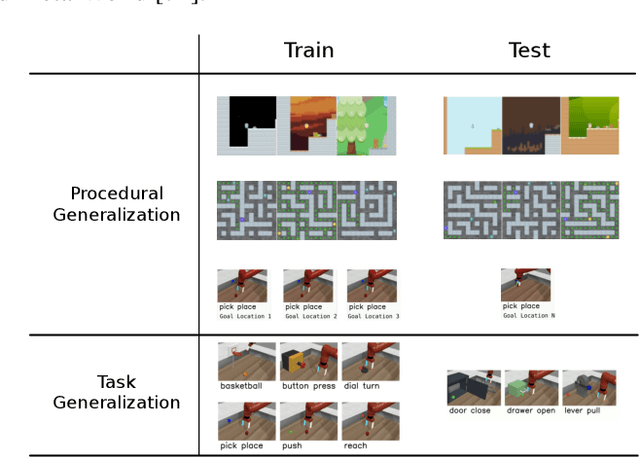
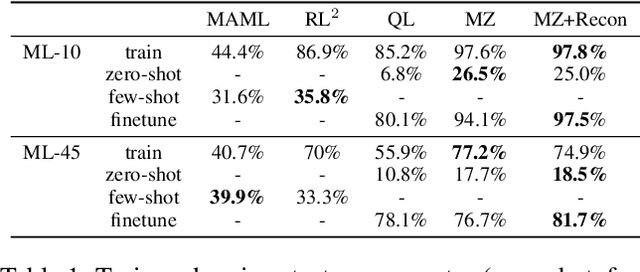
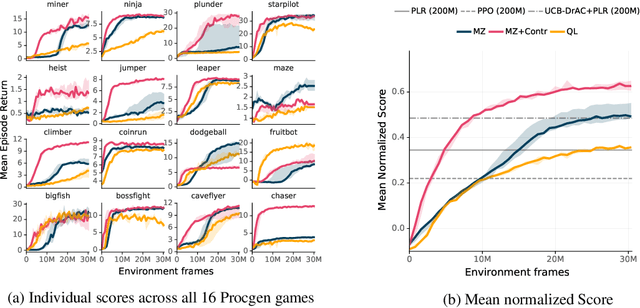
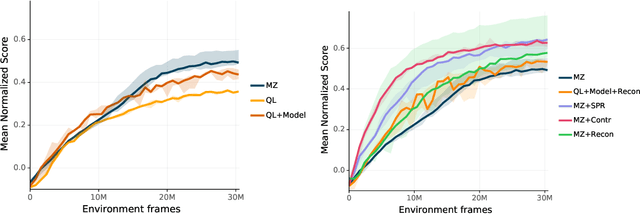
One of the key promises of model-based reinforcement learning is the ability to generalize using an internal model of the world to make predictions in novel environments and tasks. However, the generalization ability of model-based agents is not well understood because existing work has focused on model-free agents when benchmarking generalization. Here, we explicitly measure the generalization ability of model-based agents in comparison to their model-free counterparts. We focus our analysis on MuZero (Schrittwieser et al., 2020), a powerful model-based agent, and evaluate its performance on both procedural and task generalization. We identify three factors of procedural generalization -- planning, self-supervised representation learning, and procedural data diversity -- and show that by combining these techniques, we achieve state-of-the art generalization performance and data efficiency on Procgen (Cobbe et al., 2019). However, we find that these factors do not always provide the same benefits for the task generalization benchmarks in Meta-World (Yu et al., 2019), indicating that transfer remains a challenge and may require different approaches than procedural generalization. Overall, we suggest that building generalizable agents requires moving beyond the single-task, model-free paradigm and towards self-supervised model-based agents that are trained in rich, procedural, multi-task environments.
Neural Recursive Belief States in Multi-Agent Reinforcement Learning
Feb 03, 2021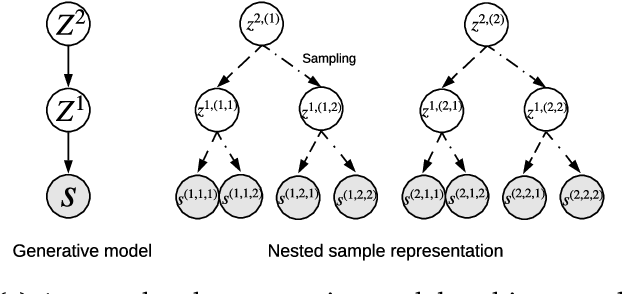
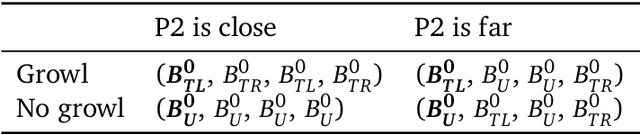
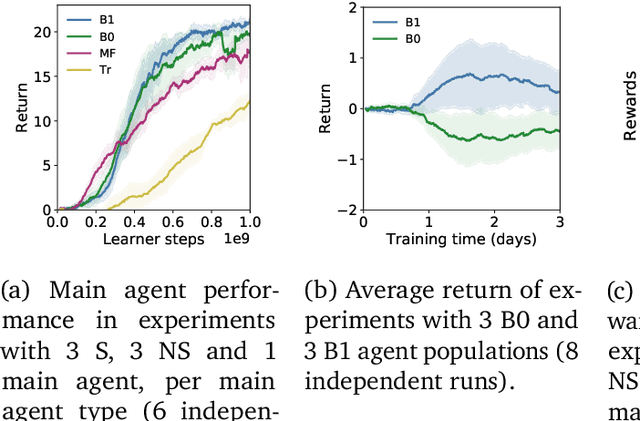
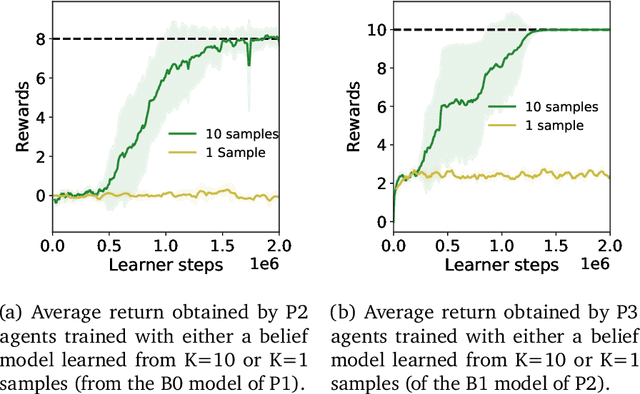
In multi-agent reinforcement learning, the problem of learning to act is particularly difficult because the policies of co-players may be heavily conditioned on information only observed by them. On the other hand, humans readily form beliefs about the knowledge possessed by their peers and leverage beliefs to inform decision-making. Such abilities underlie individual success in a wide range of Markov games, from bluffing in Poker to conditional cooperation in the Prisoner's Dilemma, to convention-building in Bridge. Classical methods are usually not applicable to complex domains due to the intractable nature of hierarchical beliefs (i.e. beliefs of other agents' beliefs). We propose a scalable method to approximate these belief structures using recursive deep generative models, and to use the belief models to obtain representations useful to acting in complex tasks. Our agents trained with belief models outperform model-free baselines with equivalent representational capacity using common training paradigms. We also show that higher-order belief models outperform agents with lower-order models.
Counterfactual Credit Assignment in Model-Free Reinforcement Learning
Nov 18, 2020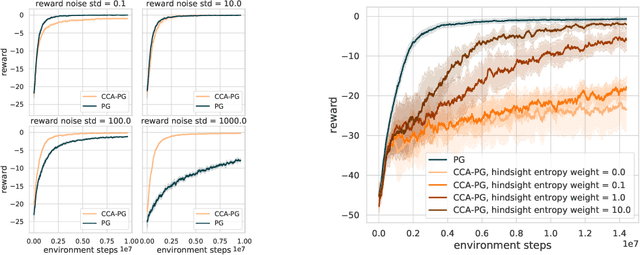
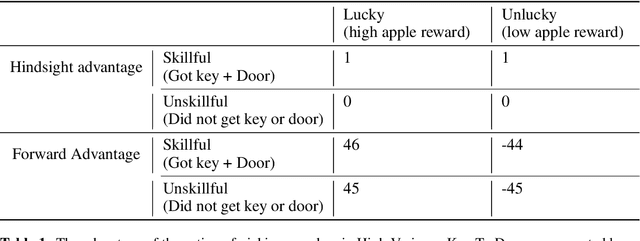

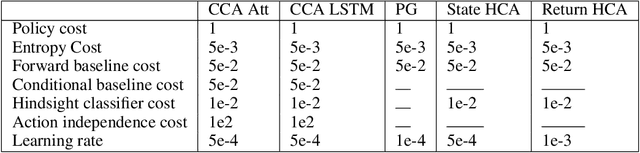
Credit assignment in reinforcement learning is the problem of measuring an action influence on future rewards. In particular, this requires separating skill from luck, ie. disentangling the effect of an action on rewards from that of external factors and subsequent actions. To achieve this, we adapt the notion of counterfactuals from causality theory to a model-free RL setup. The key idea is to condition value functions on future events, by learning to extract relevant information from a trajectory. We then propose to use these as future-conditional baselines and critics in policy gradient algorithms and we develop a valid, practical variant with provably lower variance, while achieving unbiasedness by constraining the hindsight information not to contain information about the agent actions. We demonstrate the efficacy and validity of our algorithm on a number of illustrative problems.
On the role of planning in model-based deep reinforcement learning
Nov 08, 2020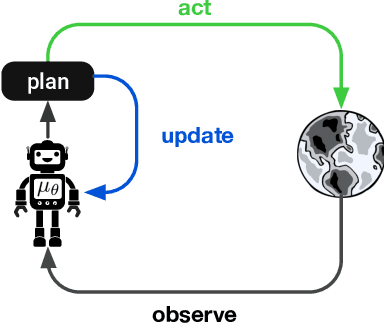

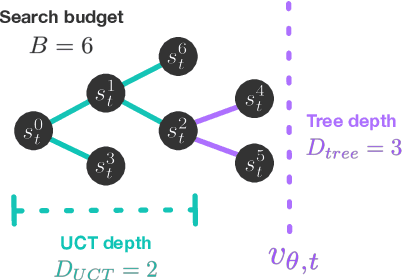
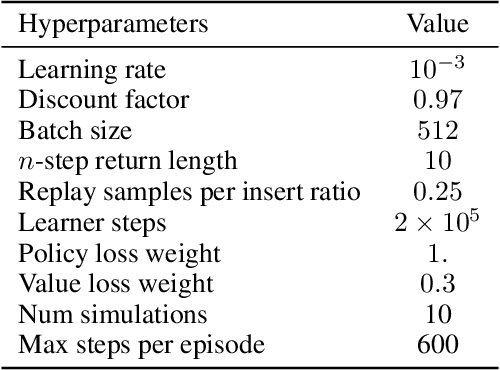
Model-based planning is often thought to be necessary for deep, careful reasoning and generalization in artificial agents. While recent successes of model-based reinforcement learning (MBRL) with deep function approximation have strengthened this hypothesis, the resulting diversity of model-based methods has also made it difficult to track which components drive success and why. In this paper, we seek to disentangle the contributions of recent methods by focusing on three questions: (1) How does planning benefit MBRL agents? (2) Within planning, what choices drive performance? (3) To what extent does planning improve generalization? To answer these questions, we study the performance of MuZero (Schrittwieser et al., 2019), a state-of-the-art MBRL algorithm, under a number of interventions and ablations and across a wide range of environments including control tasks, Atari, and 9x9 Go. Our results suggest the following: (1) The primary benefit of planning is in driving policy learning. (2) Using shallow trees with simple Monte-Carlo rollouts is as performant as more complex methods, except in the most difficult reasoning tasks. (3) Planning alone is insufficient to drive strong generalization. These results indicate where and how to utilize planning in reinforcement learning settings, and highlight a number of open questions for future MBRL research.
Physically Embedded Planning Problems: New Challenges for Reinforcement Learning
Sep 11, 2020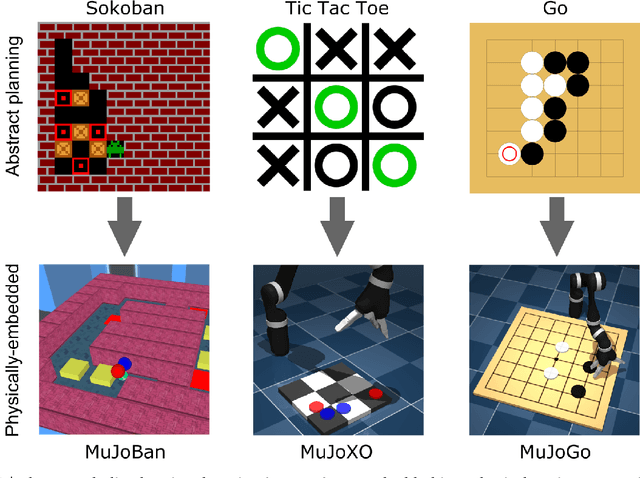


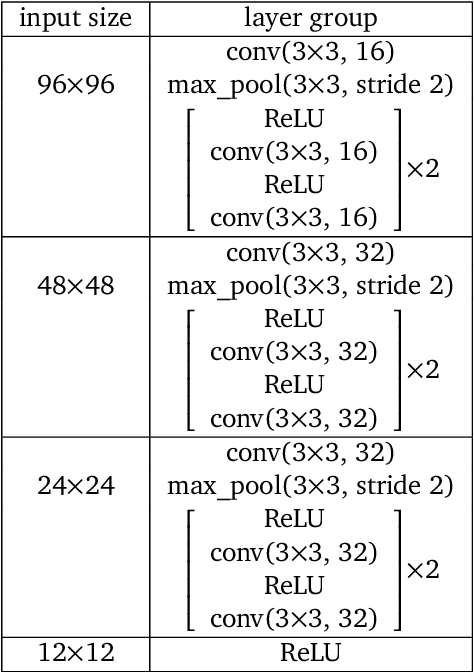
Recent work in deep reinforcement learning (RL) has produced algorithms capable of mastering challenging games such as Go, chess, or shogi. In these works the RL agent directly observes the natural state of the game and controls that state directly with its actions. However, when humans play such games, they do not just reason about the moves but also interact with their physical environment. They understand the state of the game by looking at the physical board in front of them and modify it by manipulating pieces using touch and fine-grained motor control. Mastering complicated physical systems with abstract goals is a central challenge for artificial intelligence, but it remains out of reach for existing RL algorithms. To encourage progress towards this goal we introduce a set of physically embedded planning problems and make them publicly available. We embed challenging symbolic tasks (Sokoban, tic-tac-toe, and Go) in a physics engine to produce a set of tasks that require perception, reasoning, and motor control over long time horizons. Although existing RL algorithms can tackle the symbolic versions of these tasks, we find that they struggle to master even the simplest of their physically embedded counterparts. As a first step towards characterizing the space of solution to these tasks, we introduce a strong baseline that uses a pre-trained expert game player to provide hints in the abstract space to an RL agent's policy while training it on the full sensorimotor control task. The resulting agent solves many of the tasks, underlining the need for methods that bridge the gap between abstract planning and embodied control.
Value-driven Hindsight Modelling
Feb 19, 2020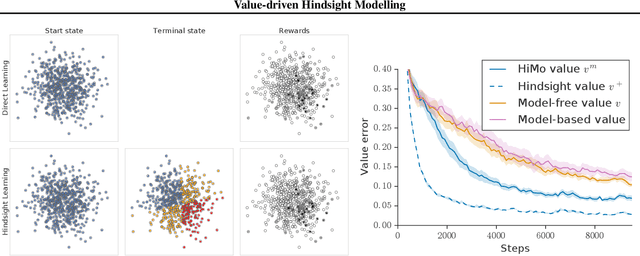
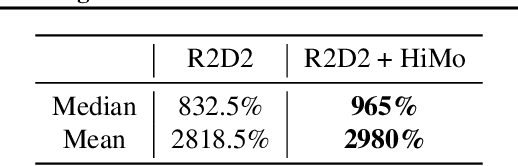
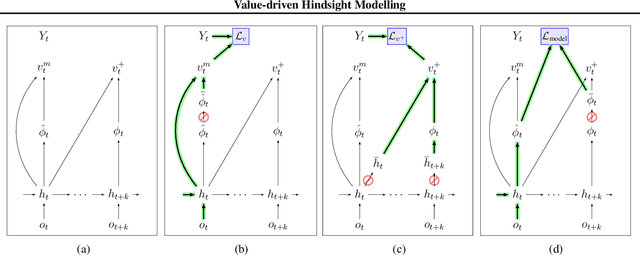

Value estimation is a critical component of the reinforcement learning (RL) paradigm. The question of how to effectively learn predictors for value from data is one of the major problems studied by the RL community, and different approaches exploit structure in the problem domain in different ways. Model learning can make use of the rich transition structure present in sequences of observations, but this approach is usually not sensitive to the reward function. In contrast, model-free methods directly leverage the quantity of interest from the future but have to compose with a potentially weak scalar signal (an estimate of the return). In this paper we develop an approach for representation learning in RL that sits in between these two extremes: we propose to learn what to model in a way that can directly help value prediction. To this end we determine which features of the future trajectory provide useful information to predict the associated return. This provides us with tractable prediction targets that are directly relevant for a task, and can thus accelerate learning of the value function. The idea can be understood as reasoning, in hindsight, about which aspects of the future observations could help past value prediction. We show how this can help dramatically even in simple policy evaluation settings. We then test our approach at scale in challenging domains, including on 57 Atari 2600 games.