 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPFData: Large-scale datasets for AC optimal power flow with topological perturbations
Jun 11, 2024

Solving the AC optimal power flow problem (AC-OPF) is critical to the efficient and safe planning and operation of power grids. Small efficiency improvements in this domain have the potential to lead to billions of dollars of cost savings, and significant reductions in emissions from fossil fuel generators. Recent work on data-driven solution methods for AC-OPF shows the potential for large speed improvements compared to traditional solvers; however, no large-scale open datasets for this problem exist. We present the largest readily-available collection of solved AC-OPF problems to date. This collection is orders of magnitude larger than existing readily-available datasets, allowing training of high-capacity data-driven models. Uniquely, it includes topological perturbations - a critical requirement for usage in realistic power grid operations. We hope this resource will spur the community to scale research to larger grid sizes with variable topology.
CANOS: A Fast and Scalable Neural AC-OPF Solver Robust To N-1 Perturbations
Mar 26, 2024Optimal Power Flow (OPF) refers to a wide range of related optimization problems with the goal of operating power systems efficiently and securely. In the simplest setting, OPF determines how much power to generate in order to minimize costs while meeting demand for power and satisfying physical and operational constraints. In even the simplest case, power grid operators use approximations of the AC-OPF problem because solving the exact problem is prohibitively slow with state-of-the-art solvers. These approximations sacrifice accuracy and operational feasibility in favor of speed. This trade-off leads to costly "uplift payments" and increased carbon emissions, especially for large power grids. In the present work, we train a deep learning system (CANOS) to predict near-optimal solutions (within 1% of the true AC-OPF cost) without compromising speed (running in as little as 33--65 ms). Importantly, CANOS scales to realistic grid sizes with promising empirical results on grids containing as many as 10,000 buses. Finally, because CANOS is a Graph Neural Network, it is robust to changes in topology. We show that CANOS is accurate across N-1 topological perturbations of a base grid typically used in security-constrained analysis. This paves the way for more efficient optimization of more complex OPF problems which alter grid connectivity such as unit commitment, topology optimization and security-constrained OPF.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022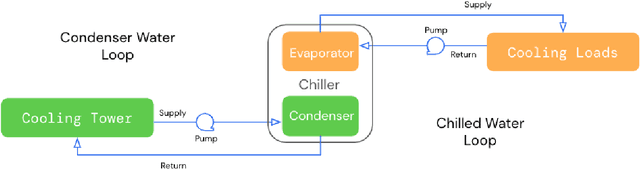
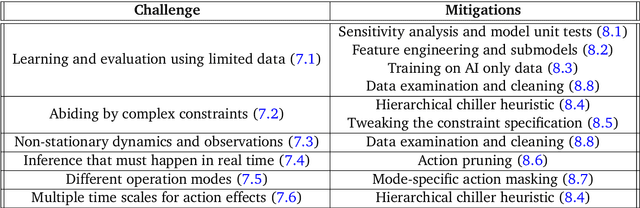
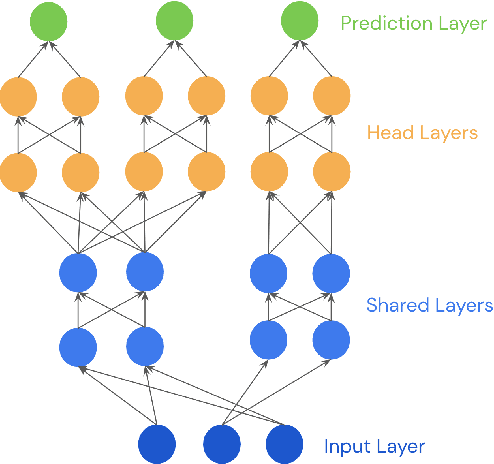
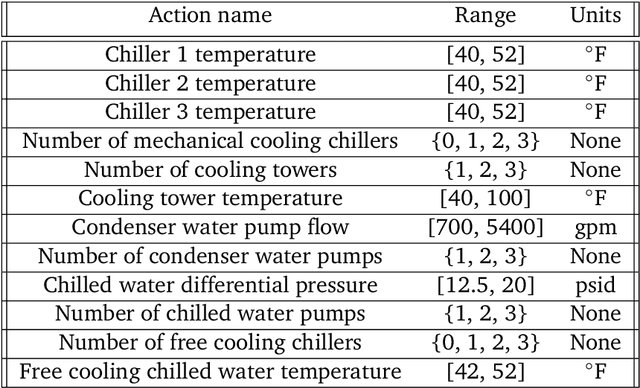
This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
Semi-analytical Industrial Cooling System Model for Reinforcement Learning
Jul 26, 2022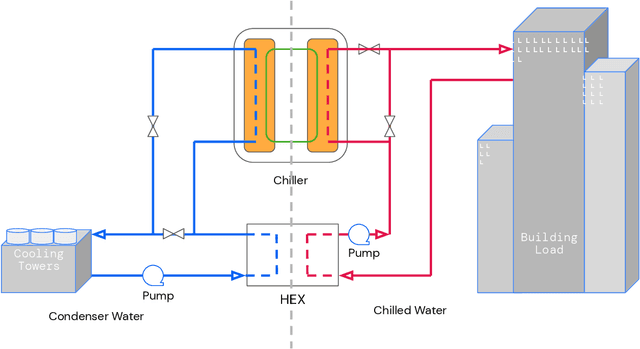
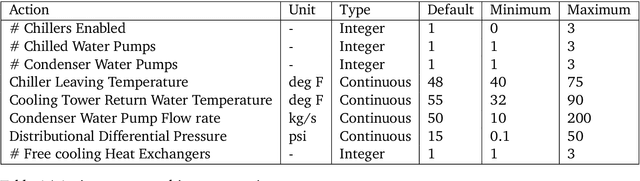
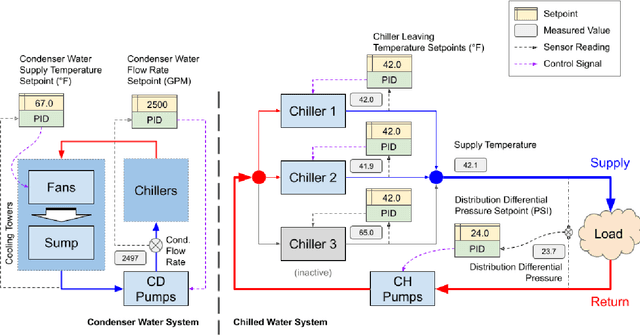
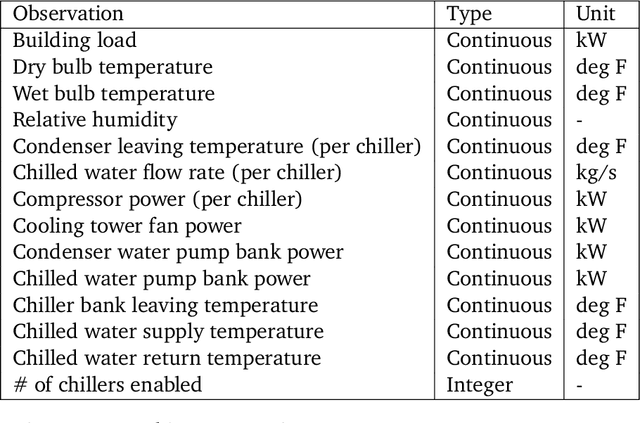
We present a hybrid industrial cooling system model that embeds analytical solutions within a multi-physics simulation. This model is designed for reinforcement learning (RL) applications and balances simplicity with simulation fidelity and interpretability. The model's fidelity is evaluated against real world data from a large scale cooling system. This is followed by a case study illustrating how the model can be used for RL research. For this, we develop an industrial task suite that allows specifying different problem settings and levels of complexity, and use it to evaluate the performance of different RL algorithms.
On the role of planning in model-based deep reinforcement learning
Nov 08, 2020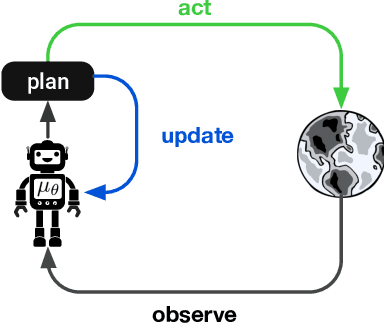

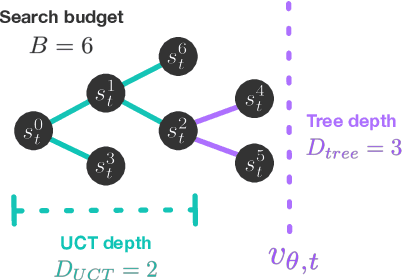
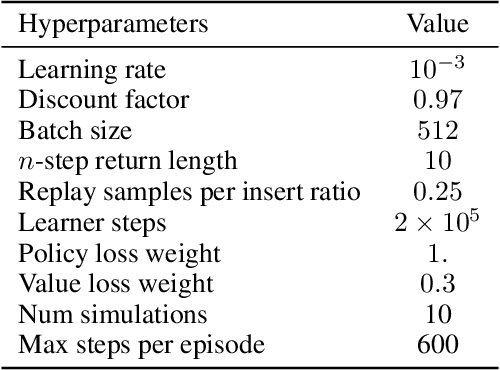
Model-based planning is often thought to be necessary for deep, careful reasoning and generalization in artificial agents. While recent successes of model-based reinforcement learning (MBRL) with deep function approximation have strengthened this hypothesis, the resulting diversity of model-based methods has also made it difficult to track which components drive success and why. In this paper, we seek to disentangle the contributions of recent methods by focusing on three questions: (1) How does planning benefit MBRL agents? (2) Within planning, what choices drive performance? (3) To what extent does planning improve generalization? To answer these questions, we study the performance of MuZero (Schrittwieser et al., 2019), a state-of-the-art MBRL algorithm, under a number of interventions and ablations and across a wide range of environments including control tasks, Atari, and 9x9 Go. Our results suggest the following: (1) The primary benefit of planning is in driving policy learning. (2) Using shallow trees with simple Monte-Carlo rollouts is as performant as more complex methods, except in the most difficult reasoning tasks. (3) Planning alone is insufficient to drive strong generalization. These results indicate where and how to utilize planning in reinforcement learning settings, and highlight a number of open questions for future MBRL research.