 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Model Selection for Compound AI Systems
Feb 20, 2025Compound AI systems that combine multiple LLM calls, such as self-refine and multi-agent-debate, achieve strong performance on many AI tasks. We address a core question in optimizing compound systems: for each LLM call or module in the system, how should one decide which LLM to use? We show that these LLM choices have a large effect on quality, but the search space is exponential. We propose LLMSelector, an efficient framework for model selection in compound systems, which leverages two key empirical insights: (i) end-to-end performance is often monotonic in how well each module performs, with all other modules held fixed, and (ii) per-module performance can be estimated accurately by an LLM. Building upon these insights, LLMSelector iteratively selects one module and allocates to it the model with the highest module-wise performance, as estimated by an LLM, until no further gain is possible. LLMSelector is applicable to any compound system with a bounded number of modules, and its number of API calls scales linearly with the number of modules, achieving high-quality model allocation both empirically and theoretically. Experiments with popular compound systems such as multi-agent debate and self-refine using LLMs such as GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 show that LLMSelector confers 5%-70% accuracy gains compared to using the same LLM for all modules.
BARE: Combining Base and Instruction-Tuned Language Models for Better Synthetic Data Generation
Feb 03, 2025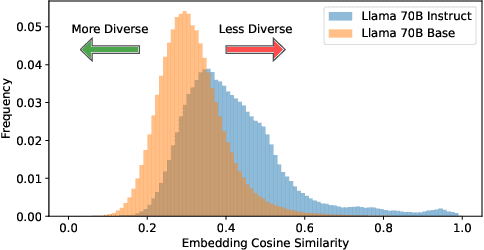

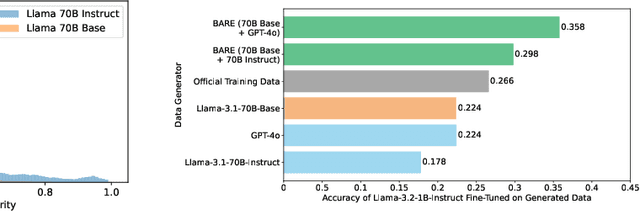

As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. A common assumption about synthetic data is that sampling from instruct-tuned models is sufficient; however, these models struggle to produce diverse outputs-a key requirement for generalization. Despite various prompting methods, in this work we show that achieving meaningful diversity from instruct-tuned models remains challenging. In contrast, we find base models without post-training exhibit greater diversity, but are less capable at instruction following and hence of lower quality. Leveraging this insight, we propose Base-Refine (BARE), a synthetic data generation method that combines the diversity of base models with the quality of instruct-tuned models through a two-stage process. With minimal few-shot examples and curation, BARE generates diverse and high-quality datasets, improving downstream task performance. We show that fine-tuning with as few as 1,000 BARE-generated samples can reach performance comparable to the best similarly sized models on LiveCodeBench tasks. Furthermore, fine-tuning with BARE-generated data achieves a 101% improvement over instruct-only data on GSM8K and a 18.4% improvement over SOTA methods on RAFT.
Networks of Networks: Complexity Class Principles Applied to Compound AI Systems Design
Jul 23, 2024
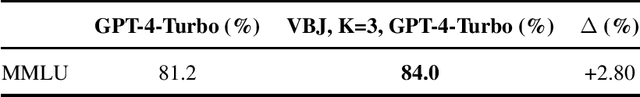
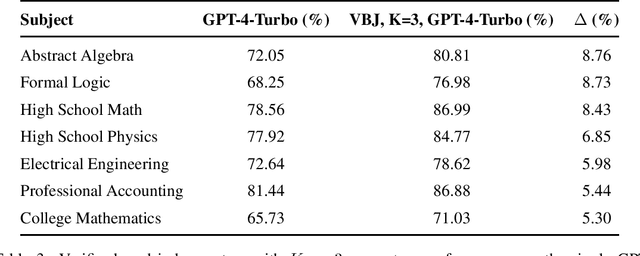

As practitioners seek to surpass the current reliability and quality frontier of monolithic models, Compound AI Systems consisting of many language model inference calls are increasingly employed. In this work, we construct systems, which we call Networks of Networks (NoNs) organized around the distinction between generating a proposed answer and verifying its correctness, a fundamental concept in complexity theory that we show empirically extends to Language Models (LMs). We introduce a verifier-based judge NoN with K generators, an instantiation of "best-of-K" or "judge-based" compound AI systems. Through experiments on synthetic tasks such as prime factorization, and core benchmarks such as the MMLU, we demonstrate notable performance gains. For instance, in factoring products of two 3-digit primes, a simple NoN improves accuracy from 3.7\% to 36.6\%. On MMLU, a verifier-based judge construction with only 3 generators boosts accuracy over individual GPT-4-Turbo calls by 2.8\%. Our analysis reveals that these gains are most pronounced in domains where verification is notably easier than generation--a characterization which we believe subsumes many reasoning and procedural knowledge tasks, but doesn't often hold for factual and declarative knowledge-based settings. For mathematical and formal logic reasoning-based subjects of MMLU, we observe a 5-8\% or higher gain, whilst no gain on others such as geography and religion. We provide key takeaways for ML practitioners, including the importance of considering verification complexity, the impact of witness format on verifiability, and a simple test to determine the potential benefit of this NoN approach for a given problem distribution. This work aims to inform future research and practice in the design of compound AI systems.
Are More LLM Calls All You Need? Towards Scaling Laws of Compound Inference Systems
Mar 04, 2024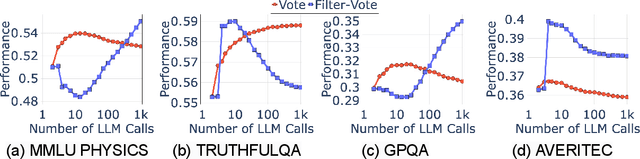
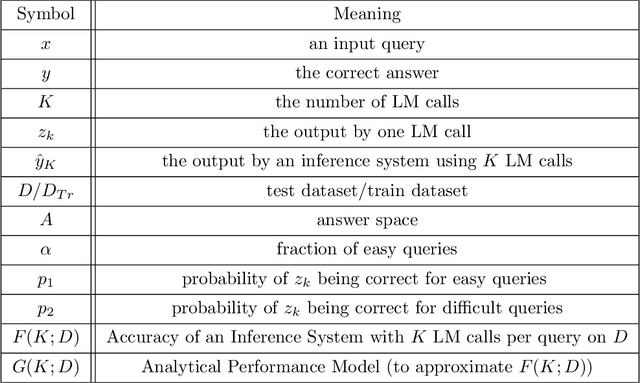
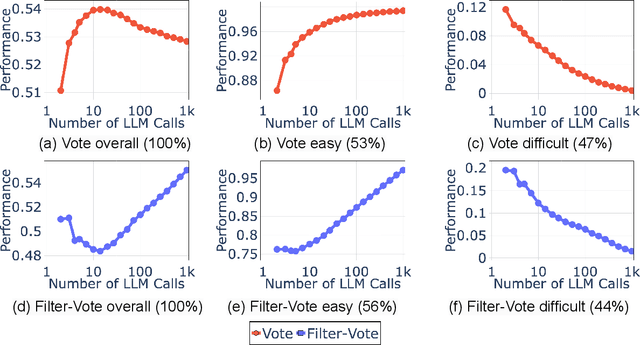
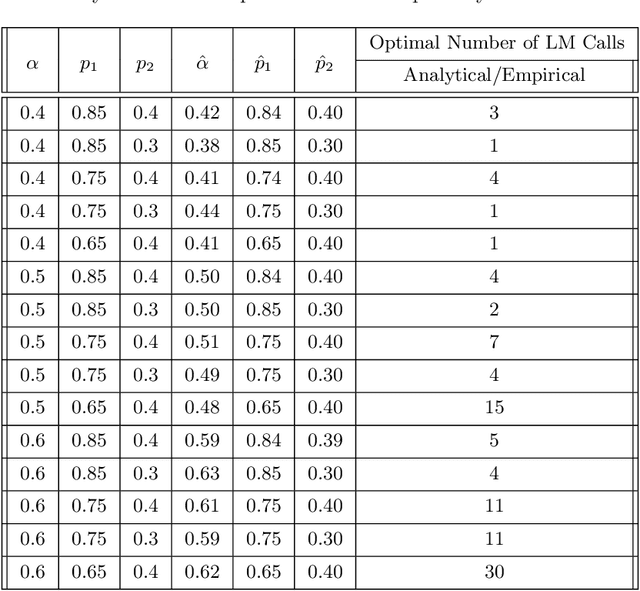
Many recent state-of-the-art results in language tasks were achieved using compound systems that perform multiple Large Language Model (LLM) calls and aggregate their responses. However, there is little understanding of how the number of LLM calls -- e.g., when asking the LLM to answer each question multiple times and taking a consensus -- affects such a compound system's performance. In this paper, we initiate the study of scaling laws of compound inference systems. We analyze, theoretically and empirically, how the number of LLM calls affects the performance of one-layer Voting Inference Systems -- one of the simplest compound systems, which aggregates LLM responses via majority voting. We find empirically that across multiple language tasks, surprisingly, Voting Inference Systems' performance first increases but then decreases as a function of the number of LLM calls. Our theoretical results suggest that this non-monotonicity is due to the diversity of query difficulties within a task: more LLM calls lead to higher performance on "easy" queries, but lower performance on "hard" queries, and non-monotone behavior emerges when a task contains both types of queries. This insight then allows us to compute, from a small number of samples, the number of LLM calls that maximizes system performance, and define a scaling law of Voting Inference Systems. Experiments show that our scaling law can predict the performance of Voting Inference Systems and find the optimal number of LLM calls to make.
Controlling Commercial Cooling Systems Using Reinforcement Learning
Nov 11, 2022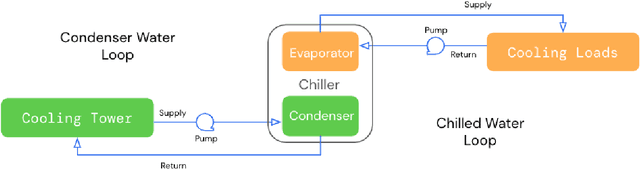
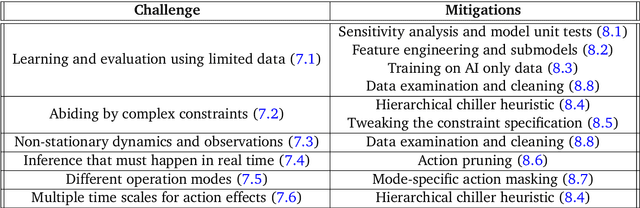
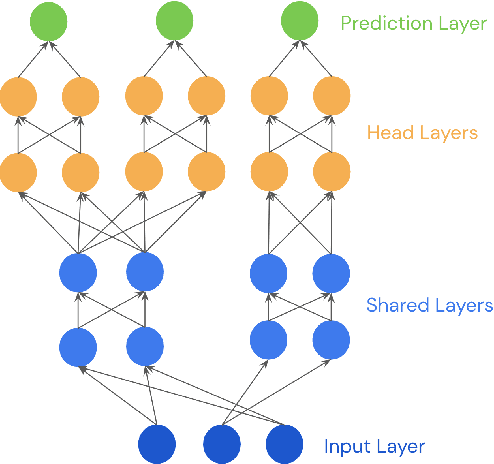
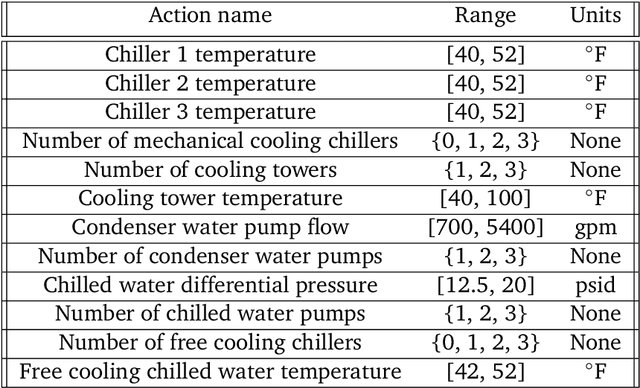
This paper is a technical overview of DeepMind and Google's recent work on reinforcement learning for controlling commercial cooling systems. Building on expertise that began with cooling Google's data centers more efficiently, we recently conducted live experiments on two real-world facilities in partnership with Trane Technologies, a building management system provider. These live experiments had a variety of challenges in areas such as evaluation, learning from offline data, and constraint satisfaction. Our paper describes these challenges in the hope that awareness of them will benefit future applied RL work. We also describe the way we adapted our RL system to deal with these challenges, resulting in energy savings of approximately 9% and 13% respectively at the two live experiment sites.
Semi-analytical Industrial Cooling System Model for Reinforcement Learning
Jul 26, 2022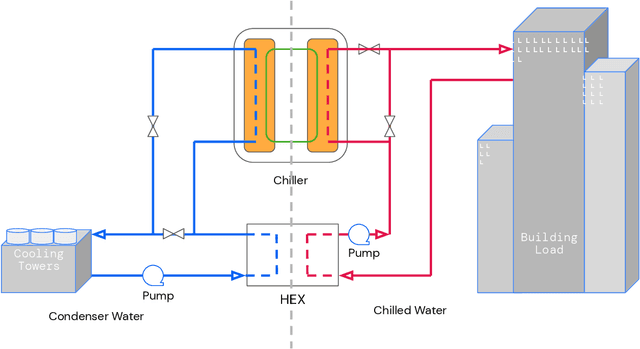
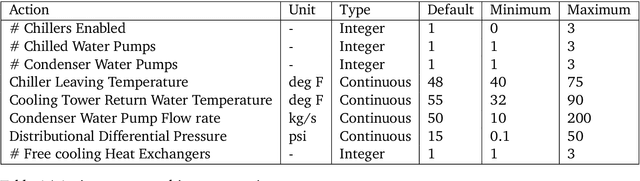
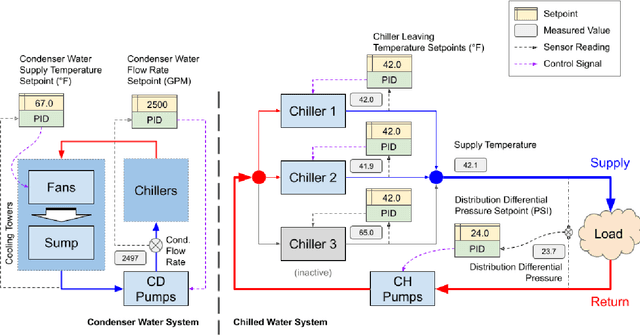
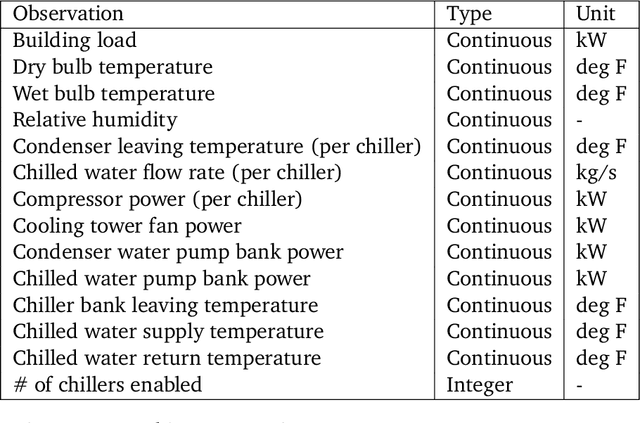
We present a hybrid industrial cooling system model that embeds analytical solutions within a multi-physics simulation. This model is designed for reinforcement learning (RL) applications and balances simplicity with simulation fidelity and interpretability. The model's fidelity is evaluated against real world data from a large scale cooling system. This is followed by a case study illustrating how the model can be used for RL research. For this, we develop an industrial task suite that allows specifying different problem settings and levels of complexity, and use it to evaluate the performance of different RL algorithms.
Decentralized Training of Foundation Models in Heterogeneous Environments
Jun 02, 2022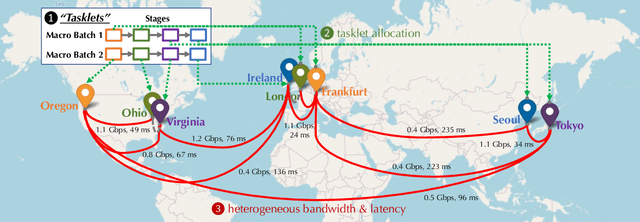
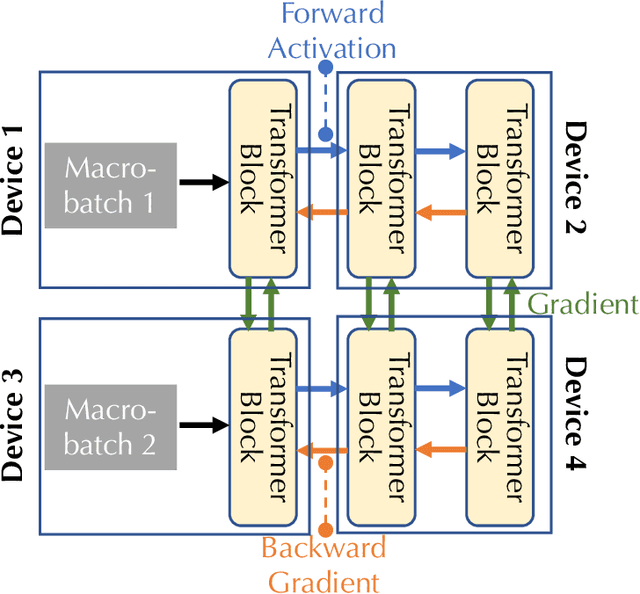
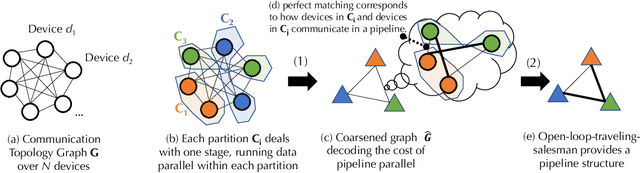

Training foundation models, such as GPT-3 and PaLM, can be extremely expensive, often involving tens of thousands of GPUs running continuously for months. These models are typically trained in specialized clusters featuring fast, homogeneous interconnects and using carefully designed software systems that support both data parallelism and model/pipeline parallelism. Such dedicated clusters can be costly and difficult to obtain. Can we instead leverage the much greater amount of decentralized, heterogeneous, and lower-bandwidth interconnected compute? Previous works examining the heterogeneous, decentralized setting focus on relatively small models that can be trained in a purely data parallel manner. State-of-the-art schemes for model parallel foundation model training, such as Megatron, only consider the homogeneous data center setting. In this paper, we present the first study of training large foundation models with model parallelism in a decentralized regime over a heterogeneous network. Our key technical contribution is a scheduling algorithm that allocates different computational "tasklets" in the training of foundation models to a group of decentralized GPU devices connected by a slow heterogeneous network. We provide a formal cost model and further propose an efficient evolutionary algorithm to find the optimal allocation strategy. We conduct extensive experiments that represent different scenarios for learning over geo-distributed devices simulated using real-world network measurements. In the most extreme case, across 8 different cities spanning 3 continents, our approach is 4.8X faster than prior state-of-the-art training systems (Megatron).
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
An Ode to an ODE
Jun 23, 2020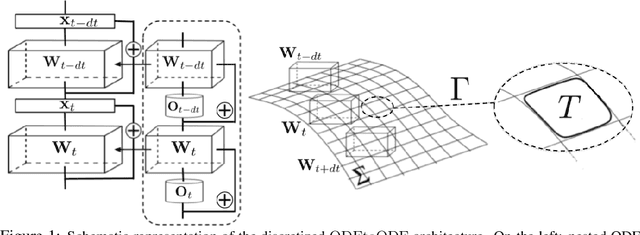

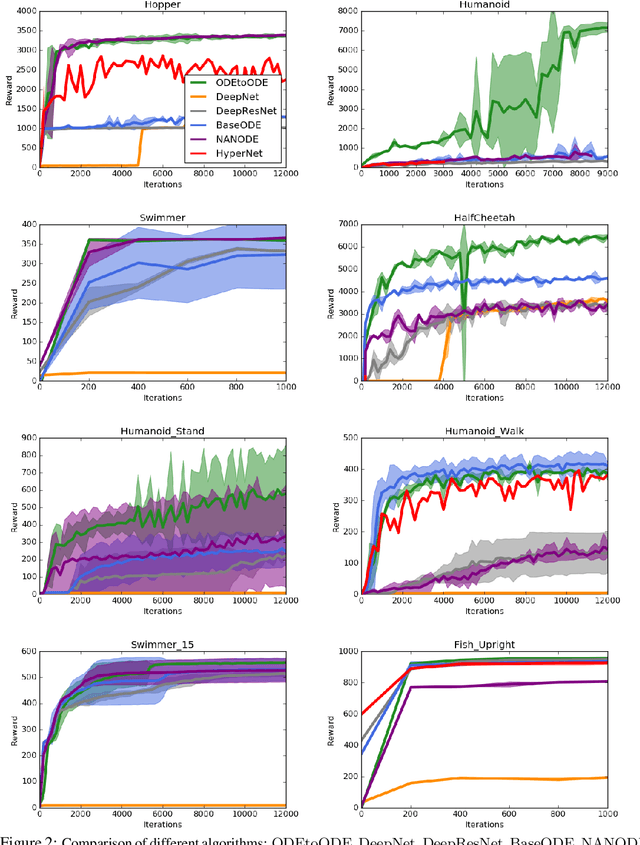
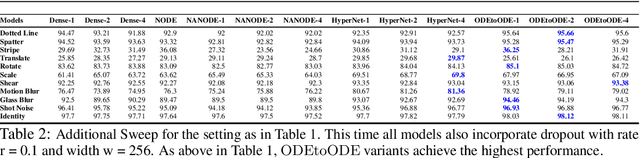
We present a new paradigm for Neural ODE algorithms, called ODEtoODE, where time-dependent parameters of the main flow evolve according to a matrix flow on the orthogonal group O(d). This nested system of two flows, where the parameter-flow is constrained to lie on the compact manifold, provides stability and effectiveness of training and provably solves the gradient vanishing-explosion problem which is intrinsically related to training deep neural network architectures such as Neural ODEs. Consequently, it leads to better downstream models, as we show on the example of training reinforcement learning policies with evolution strategies, and in the supervised learning setting, by comparing with previous SOTA baselines. We provide strong convergence results for our proposed mechanism that are independent of the depth of the network, supporting our empirical studies. Our results show an intriguing connection between the theory of deep neural networks and the field of matrix flows on compact manifolds.
Time Dependence in Non-Autonomous Neural ODEs
May 06, 2020


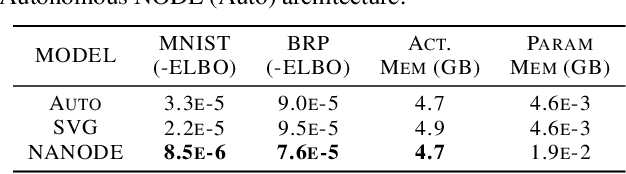
Neural Ordinary Differential Equations (ODEs) are elegant reinterpretations of deep networks where continuous time can replace the discrete notion of depth, ODE solvers perform forward propagation, and the adjoint method enables efficient, constant memory backpropagation. Neural ODEs are universal approximators only when they are non-autonomous, that is, the dynamics depends explicitly on time. We propose a novel family of Neural ODEs with time-varying weights, where time-dependence is non-parametric, and the smoothness of weight trajectories can be explicitly controlled to allow a tradeoff between expressiveness and efficiency. Using this enhanced expressiveness, we outperform previous Neural ODE variants in both speed and representational capacity, ultimately outperforming standard ResNet and CNN models on select image classification and video prediction tasks.