 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Estimation of Shortest-Path Distance Distributions to Samples in Graphs
Feb 21, 2025
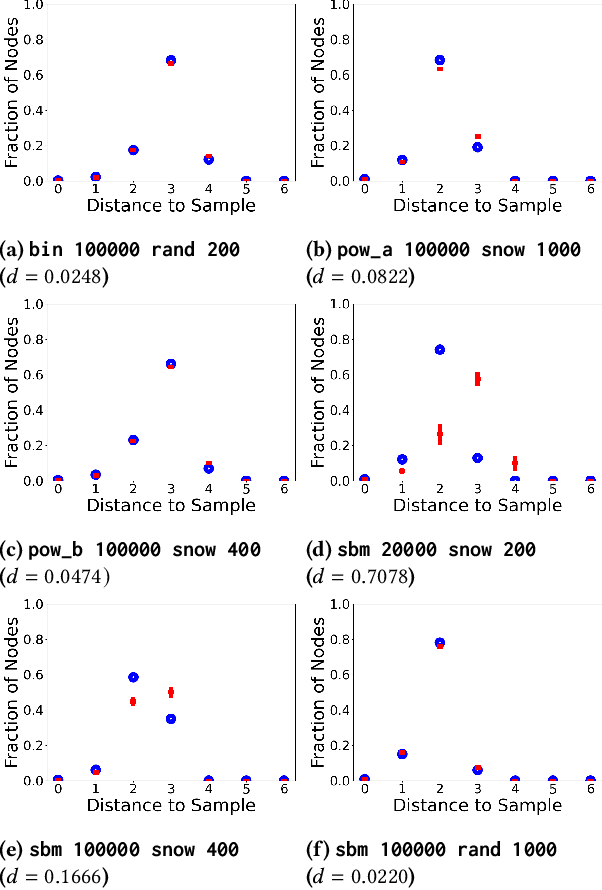
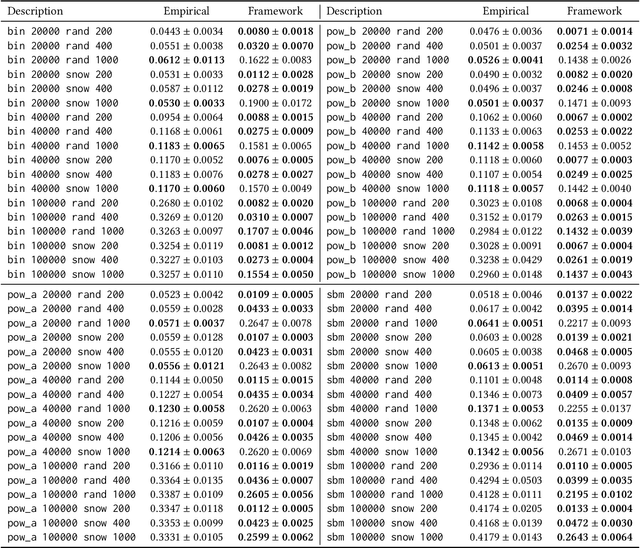
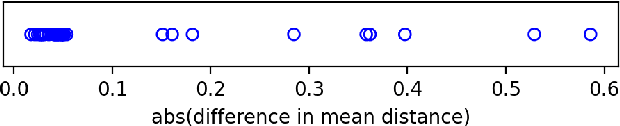
As large graph datasets become increasingly common across many fields, sampling is often needed to reduce the graphs into manageable sizes. This procedure raises critical questions about representativeness as no sample can capture the properties of the original graph perfectly, and different parts of the graph are not evenly affected by the loss. Recent work has shown that the distances from the non-sampled nodes to the sampled nodes can be a quantitative indicator of bias and fairness in graph machine learning. However, to our knowledge, there is no method for evaluating how a sampling method affects the distribution of shortest-path distances without actually performing the sampling and shortest-path calculation. In this paper, we present an accurate and efficient framework for estimating the distribution of shortest-path distances to the sample, applicable to a wide range of sampling methods and graph structures. Our framework is faster than empirical methods and only requires the specification of degree distributions. We also extend our framework to handle graphs with community structures. While this introduces a decrease in accuracy, we demonstrate that our framework remains highly accurate on downstream comparison-based tasks. Code is publicly available at https://github.com/az1326/shortest_paths.
BARE: Combining Base and Instruction-Tuned Language Models for Better Synthetic Data Generation
Feb 03, 2025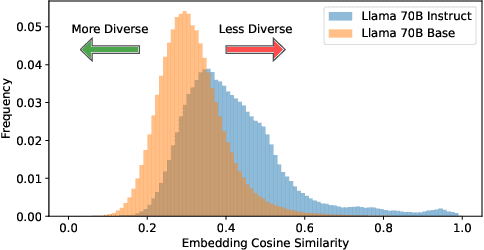

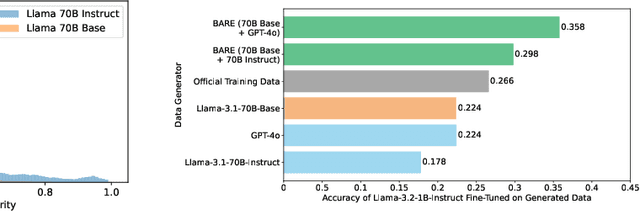

As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. A common assumption about synthetic data is that sampling from instruct-tuned models is sufficient; however, these models struggle to produce diverse outputs-a key requirement for generalization. Despite various prompting methods, in this work we show that achieving meaningful diversity from instruct-tuned models remains challenging. In contrast, we find base models without post-training exhibit greater diversity, but are less capable at instruction following and hence of lower quality. Leveraging this insight, we propose Base-Refine (BARE), a synthetic data generation method that combines the diversity of base models with the quality of instruct-tuned models through a two-stage process. With minimal few-shot examples and curation, BARE generates diverse and high-quality datasets, improving downstream task performance. We show that fine-tuning with as few as 1,000 BARE-generated samples can reach performance comparable to the best similarly sized models on LiveCodeBench tasks. Furthermore, fine-tuning with BARE-generated data achieves a 101% improvement over instruct-only data on GSM8K and a 18.4% improvement over SOTA methods on RAFT.
Accelerating Retrieval-Augmented Language Model Serving with Speculation
Jan 25, 2024Retrieval-augmented language models (RaLM) have demonstrated the potential to solve knowledge-intensive natural language processing (NLP) tasks by combining a non-parametric knowledge base with a parametric language model. Instead of fine-tuning a fully parametric model, RaLM excels at its low-cost adaptation to the latest data and better source attribution mechanisms. Among various RaLM approaches, iterative RaLM delivers a better generation quality due to a more frequent interaction between the retriever and the language model. Despite the benefits, iterative RaLM usually encounters high overheads due to the frequent retrieval step. To this end, we propose RaLMSpec, a speculation-inspired framework that provides generic speed-up over iterative RaLM while preserving the same model outputs through speculative retrieval and batched verification. By further incorporating prefetching, optimal speculation stride scheduler, and asynchronous verification, RaLMSpec can automatically exploit the acceleration potential to the fullest. For naive iterative RaLM serving, extensive evaluations over three language models on four downstream QA datasets demonstrate that RaLMSpec can achieve a speed-up ratio of 1.75-2.39x, 1.04-1.39x, and 1.31-1.77x when the retriever is an exact dense retriever, approximate dense retriever, and sparse retriever respectively compared with the baseline. For KNN-LM serving, RaLMSpec can achieve a speed-up ratio up to 7.59x and 2.45x when the retriever is an exact dense retriever and approximate dense retriever, respectively, compared with the baseline.
TreeScope: An Agricultural Robotics Dataset for LiDAR-Based Mapping of Trees in Forests and Orchards
Oct 03, 2023

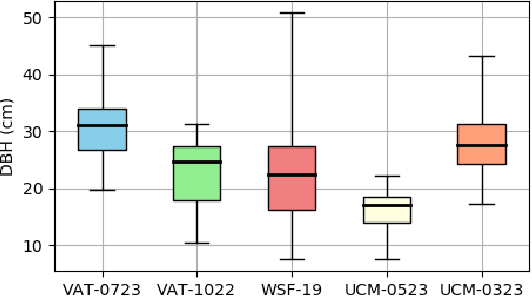

Data collection for forestry, timber, and agriculture currently relies on manual techniques which are labor-intensive and time-consuming. We seek to demonstrate that robotics offers improvements over these techniques and accelerate agricultural research, beginning with semantic segmentation and diameter estimation of trees in forests and orchards. We present TreeScope v1.0, the first robotics dataset for precision agriculture and forestry addressing the counting and mapping of trees in forestry and orchards. TreeScope provides LiDAR data from agricultural environments collected with robotics platforms, such as UAV and mobile robot platforms carried by vehicles and human operators. In the first release of this dataset, we provide ground-truth data with over 1,800 manually annotated semantic labels for tree stems and field-measured tree diameters. We share benchmark scripts for these tasks that researchers may use to evaluate the accuracy of their algorithms. Finally, we run our open-source diameter estimation and off-the-shelf semantic segmentation algorithms and share our baseline results.