 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARE: Combining Base and Instruction-Tuned Language Models for Better Synthetic Data Generation
Feb 03, 2025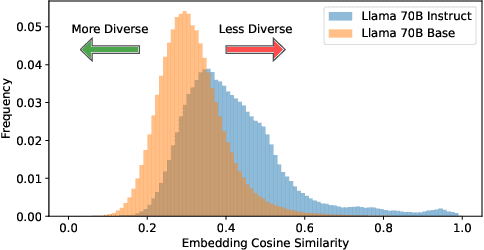

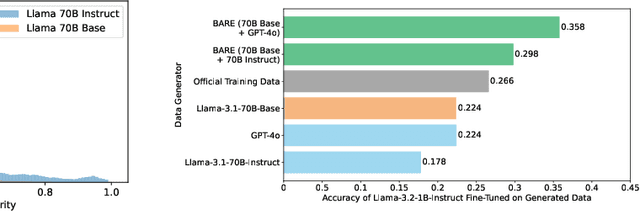

As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. A common assumption about synthetic data is that sampling from instruct-tuned models is sufficient; however, these models struggle to produce diverse outputs-a key requirement for generalization. Despite various prompting methods, in this work we show that achieving meaningful diversity from instruct-tuned models remains challenging. In contrast, we find base models without post-training exhibit greater diversity, but are less capable at instruction following and hence of lower quality. Leveraging this insight, we propose Base-Refine (BARE), a synthetic data generation method that combines the diversity of base models with the quality of instruct-tuned models through a two-stage process. With minimal few-shot examples and curation, BARE generates diverse and high-quality datasets, improving downstream task performance. We show that fine-tuning with as few as 1,000 BARE-generated samples can reach performance comparable to the best similarly sized models on LiveCodeBench tasks. Furthermore, fine-tuning with BARE-generated data achieves a 101% improvement over instruct-only data on GSM8K and a 18.4% improvement over SOTA methods on RAFT.
Revisiting Prompt Engineering via Declarative Crowdsourcing
Aug 07, 2023Large language models (LLMs) are incredibly powerful at comprehending and generating data in the form of text, but are brittle and error-prone. There has been an advent of toolkits and recipes centered around so-called prompt engineering-the process of asking an LLM to do something via a series of prompts. However, for LLM-powered data processing workflows, in particular, optimizing for quality, while keeping cost bounded, is a tedious, manual process. We put forth a vision for declarative prompt engineering. We view LLMs like crowd workers and leverage ideas from the declarative crowdsourcing literature-including leveraging multiple prompting strategies, ensuring internal consistency, and exploring hybrid-LLM-non-LLM approaches-to make prompt engineering a more principled process. Preliminary case studies on sorting, entity resolution, and imputation demonstrate the promise of our approach