 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROMPTEVALS: A Dataset of Assertions and Guardrails for Custom Production Large Language Model Pipelines
Apr 20, 2025Large language models (LLMs) are increasingly deployed in specialized production data processing pipelines across diverse domains -- such as finance, marketing, and e-commerce. However, when running them in production across many inputs, they often fail to follow instructions or meet developer expectations. To improve reliability in these applications, creating assertions or guardrails for LLM outputs to run alongside the pipelines is essential. Yet, determining the right set of assertions that capture developer requirements for a task is challenging. In this paper, we introduce PROMPTEVALS, a dataset of 2087 LLM pipeline prompts with 12623 corresponding assertion criteria, sourced from developers using our open-source LLM pipeline tools. This dataset is 5x larger than previous collections. Using a hold-out test split of PROMPTEVALS as a benchmark, we evaluated closed- and open-source models in generating relevant assertions. Notably, our fine-tuned Mistral and Llama 3 models outperform GPT-4o by 20.93% on average, offering both reduced latency and improved performance. We believe our dataset can spur further research in LLM reliability, alignment, and prompt engineering.
RAG Without the Lag: Interactive Debugging for Retrieval-Augmented Generation Pipelines
Apr 18, 2025Retrieval-augmented generation (RAG) pipelines have become the de-facto approach for building AI assistants with access to external, domain-specific knowledge. Given a user query, RAG pipelines typically first retrieve (R) relevant information from external sources, before invoking a Large Language Model (LLM), augmented (A) with this information, to generate (G) responses. Modern RAG pipelines frequently chain multiple retrieval and generation components, in any order. However, developing effective RAG pipelines is challenging because retrieval and generation components are intertwined, making it hard to identify which component(s) cause errors in the eventual output. The parameters with the greatest impact on output quality often require hours of pre-processing after each change, creating prohibitively slow feedback cycles. To address these challenges, we present RAGGY, a developer tool that combines a Python library of composable RAG primitives with an interactive interface for real-time debugging. We contribute the design and implementation of RAGGY, insights into expert debugging patterns through a qualitative study with 12 engineers, and design implications for future RAG tools that better align with developers' natural workflows.
LLM-Powered Proactive Data Systems
Feb 18, 2025With the power of LLMs, we now have the ability to query data that was previously impossible to query, including text, images, and video. However, despite this enormous potential, most present-day data systems that leverage LLMs are reactive, reflecting our community's desire to map LLMs to known abstractions. Most data systems treat LLMs as an opaque black box that operates on user inputs and data as is, optimizing them much like any other approximate, expensive UDFs, in conjunction with other relational operators. Such data systems do as they are told, but fail to understand and leverage what the LLM is being asked to do (i.e. the underlying operations, which may be error-prone), the data the LLM is operating on (e.g., long, complex documents), or what the user really needs. They don't take advantage of the characteristics of the operations and/or the data at hand, or ensure correctness of results when there are imprecisions and ambiguities. We argue that data systems instead need to be proactive: they need to be given more agency -- armed with the power of LLMs -- to understand and rework the user inputs and the data and to make decisions on how the operations and the data should be represented and processed. By allowing the data system to parse, rewrite, and decompose user inputs and data, or to interact with the user in ways that go beyond the standard single-shot query-result paradigm, the data system is able to address user needs more efficiently and effectively. These new capabilities lead to a rich design space where the data system takes more initiative: they are empowered to perform optimization based on the transformation operations, data characteristics, and user intent. We discuss various successful examples of how this framework has been and can be applied in real-world tasks, and present future directions for this ambitious research agenda.
DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing
Oct 16, 2024



Analyzing unstructured data, such as complex documents, has been a persistent challenge in data processing. Large Language Models (LLMs) have shown promise in this regard, leading to recent proposals for declarative frameworks for LLM-powered unstructured data processing. However, these frameworks focus on reducing cost when executing user-specified operations using LLMs, rather than improving accuracy, executing most operations as-is. This is problematic for complex tasks and data, where LLM outputs for user-defined operations are often inaccurate, even with optimized prompts. We present DocETL, a system that optimizes complex document processing pipelines, while accounting for LLM shortcomings. DocETL offers a declarative interface for users to define such pipelines and uses an agent-based framework to automatically optimize them, leveraging novel agent-based rewrites (that we call {\em rewrite directives}) and an optimization and evaluation framework that we introduce. We introduce {\em (i)} logical rewriting of pipelines, tailored for LLM-based tasks, {\em (ii)} an agent-guided plan evaluation mechanism that synthesizes and orchestrates task-specific validation prompts, and {\em (iii)} an optimization algorithm that efficiently finds promising plans, considering the time constraints of LLM-based plan generation and evaluation. Our evaluation on three different unstructured document analysis tasks demonstrates that DocETL finds plans with outputs that are $1.34$ to $4.6\times$ higher quality (e.g., more accurate, comprehensive) than well-engineered baselines, addressing a critical gap in existing declarative frameworks for unstructured data analysis. DocETL is open-source at \ttt{docetl.org}, and as of October 2024, has amassed over 800 GitHub Stars, with users spanning a variety of domains.
Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
Apr 18, 2024



Due to the cumbersome nature of human evaluation and limitations of code-based evaluation, Large Language Models (LLMs) are increasingly being used to assist humans in evaluating LLM outputs. Yet LLM-generated evaluators simply inherit all the problems of the LLMs they evaluate, requiring further human validation. We present a mixed-initiative approach to ``validate the validators'' -- aligning LLM-generated evaluation functions (be it prompts or code) with human requirements. Our interface, EvalGen, provides automated assistance to users in generating evaluation criteria and implementing assertions. While generating candidate implementations (Python functions, LLM grader prompts), EvalGen asks humans to grade a subset of LLM outputs; this feedback is used to select implementations that better align with user grades. A qualitative study finds overall support for EvalGen but underscores the subjectivity and iterative process of alignment. In particular, we identify a phenomenon we dub \emph{criteria drift}: users need criteria to grade outputs, but grading outputs helps users define criteria. What is more, some criteria appears \emph{dependent} on the specific LLM outputs observed (rather than independent criteria that can be defined \emph{a priori}), raising serious questions for approaches that assume the independence of evaluation from observation of model outputs. We present our interface and implementation details, a comparison of our algorithm with a baseline approach, and implications for the design of future LLM evaluation assistants.
Revisiting Prompt Engineering via Declarative Crowdsourcing
Aug 07, 2023Large language models (LLMs) are incredibly powerful at comprehending and generating data in the form of text, but are brittle and error-prone. There has been an advent of toolkits and recipes centered around so-called prompt engineering-the process of asking an LLM to do something via a series of prompts. However, for LLM-powered data processing workflows, in particular, optimizing for quality, while keeping cost bounded, is a tedious, manual process. We put forth a vision for declarative prompt engineering. We view LLMs like crowd workers and leverage ideas from the declarative crowdsourcing literature-including leveraging multiple prompting strategies, ensuring internal consistency, and exploring hybrid-LLM-non-LLM approaches-to make prompt engineering a more principled process. Preliminary case studies on sorting, entity resolution, and imputation demonstrate the promise of our approach
Operationalizing Machine Learning: An Interview Study
Sep 16, 2022
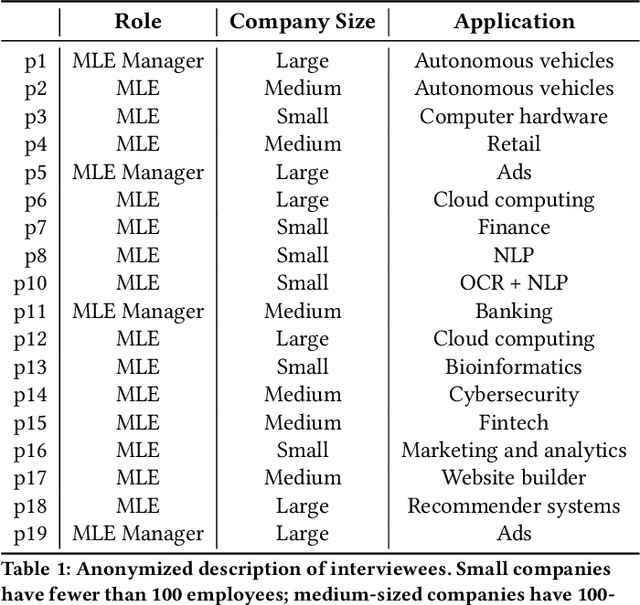
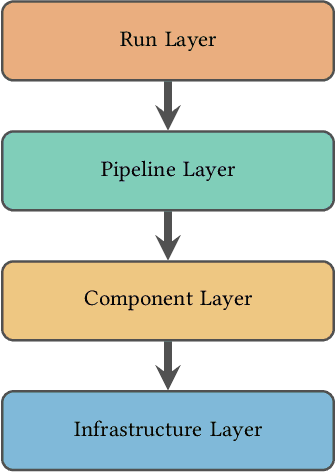
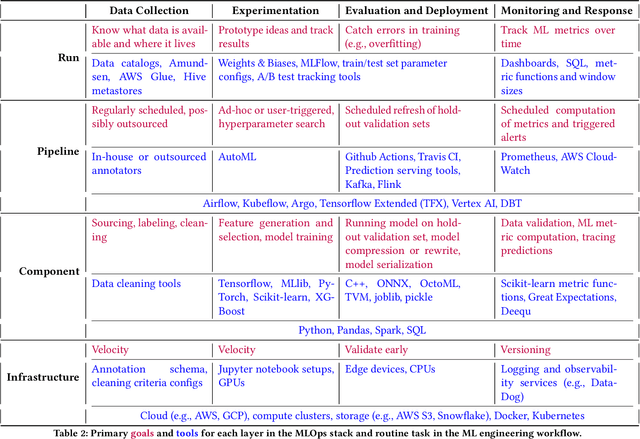
Organizations rely on machine learning engineers (MLEs) to operationalize ML, i.e., deploy and maintain ML pipelines in production. The process of operationalizing ML, or MLOps, consists of a continual loop of (i) data collection and labeling, (ii) experimentation to improve ML performance, (iii) evaluation throughout a multi-staged deployment process, and (iv) monitoring of performance drops in production. When considered together, these responsibilities seem staggering -- how does anyone do MLOps, what are the unaddressed challenges, and what are the implications for tool builders? We conducted semi-structured ethnographic interviews with 18 MLEs working across many applications, including chatbots, autonomous vehicles, and finance. Our interviews expose three variables that govern success for a production ML deployment: Velocity, Validation, and Versioning. We summarize common practices for successful ML experimentation, deployment, and sustaining production performance. Finally, we discuss interviewees' pain points and anti-patterns, with implications for tool design.
Rethinking Streaming Machine Learning Evaluation
May 23, 2022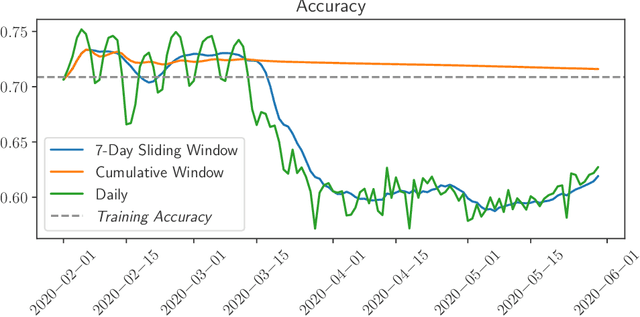
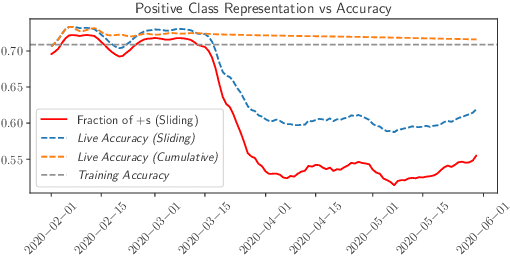
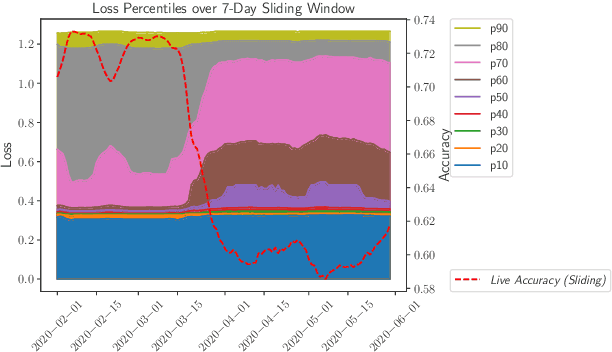
While most work on evaluating machine learning (ML) models focuses on computing accuracy on batches of data, tracking accuracy alone in a streaming setting (i.e., unbounded, timestamp-ordered datasets) fails to appropriately identify when models are performing unexpectedly. In this position paper, we discuss how the nature of streaming ML problems introduces new real-world challenges (e.g., delayed arrival of labels) and recommend additional metrics to assess streaming ML performance.
Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Nov 03, 2020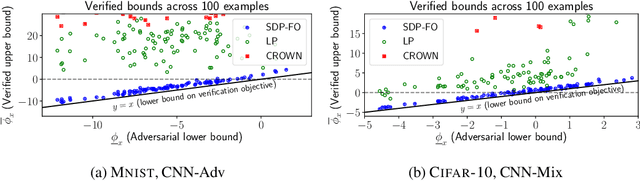
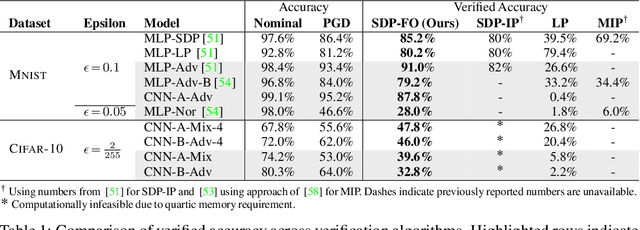
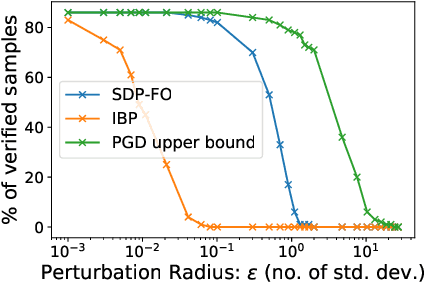

Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
Optimal Transfer Learning Model for Binary Classification of Funduscopic Images through Simple Heuristics
Feb 20, 2020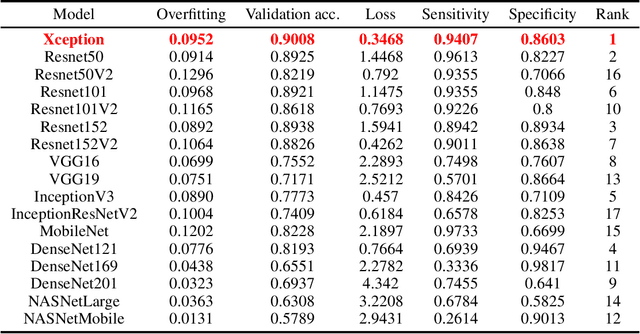
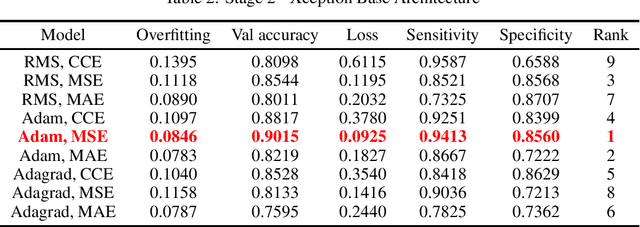
Deep learning models have the capacity to fundamentally revolutionize medical imaging analysis, and they have particularly interesting applications in computer-aided diagnosis. We attempt to use deep learning neural networks to diagnose funduscopic images, visual representations of the interior of the eye. Recently, a few robust deep learning approaches have performed binary classification to infer the presence of a specific ocular disease, such as glaucoma or diabetic retinopathy. In an effort to broaden the applications of computer-aided ocular disease diagnosis, we propose a unifying model for disease classification: low-cost inference of a fundus image to determine whether it is healthy or diseased. To achieve this, we use transfer learning techniques, which retain the more overarching capabilities of a pre-trained base architecture but can adapt to another dataset. For comparisons, we then develop a custom heuristic equation and evaluation metric ranking system to determine the optimal base architecture and hyperparameters. The Xception base architecture, Adam optimizer, and mean squared error loss function perform best, achieving 90% accuracy, 94% sensitivity, and 86% specificity. For additional ease of use, we contain the model in a web interface whose file chooser can access the local filesystem, allowing for use on any internet-connected device: mobile, PC, or otherwise.