 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn approach for systematic decomposition of complex llm tasks
Oct 09, 2025Large Language Models (LLMs) suffer from reliability issues on complex tasks, as existing decomposition methods are heuristic and rely on agent or manual decomposition. This work introduces a novel, systematic decomposition framework that we call Analysis of CONstraint-Induced Complexity (ACONIC), which models the task as a constraint problem and leveraging formal complexity measures to guide decomposition. On combinatorial (SATBench) and LLM database querying tasks (Spider), we find that by decomposing the tasks following the measure of complexity, agent can perform considerably better (10-40 percentage point).
A Simple and Fast Way to Handle Semantic Errors in Transactions
Dec 17, 2024
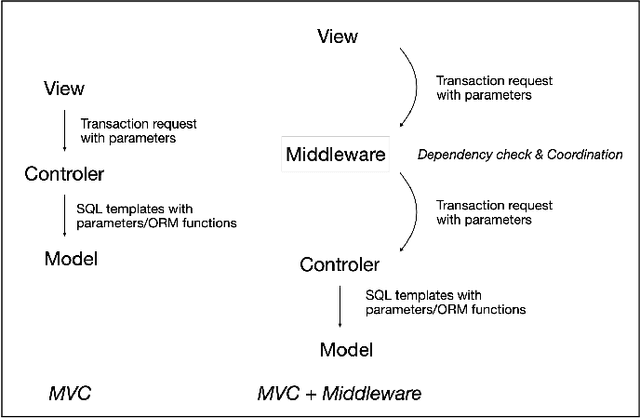

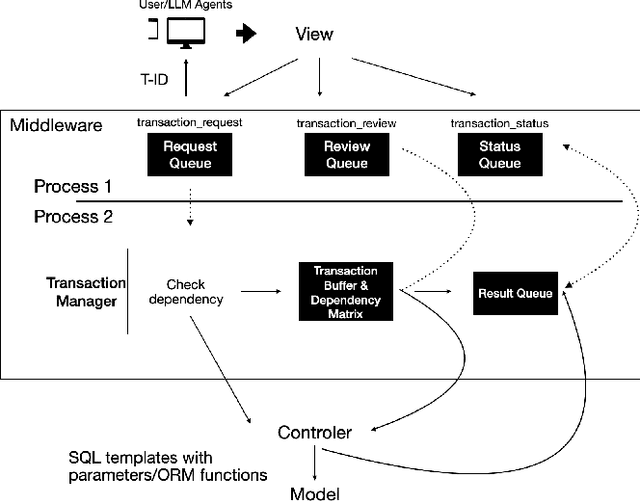
Many computer systems are now being redesigned to incorporate LLM-powered agents, enabling natural language input and more flexible operations. This paper focuses on handling database transactions created by large language models (LLMs). Transactions generated by LLMs may include semantic errors, requiring systems to treat them as long-lived. This allows for human review and, if the transaction is incorrect, removal from the database history. Any removal action must ensure the database's consistency (the "C" in ACID principles) is maintained throughout the process. We propose a novel middleware framework based on Invariant Satisfaction (I-Confluence), which ensures consistency by identifying and coordinating dependencies between long-lived transactions and new transactions. This middleware buffers suspicious or compensating transactions to manage coordination states. Using the TPC-C benchmark, we evaluate how transaction generation frequency, user reviews, and invariant completeness impact system performance. For system researchers, this study establishes an interactive paradigm between LLMs and database systems, providing an "undoing" mechanism for handling incorrect operations while guaranteeing database consistency. For system engineers, this paper offers a middleware design that integrates removable LLM-generated transactions into existing systems with minimal modifications.
DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing
Oct 16, 2024



Analyzing unstructured data, such as complex documents, has been a persistent challenge in data processing. Large Language Models (LLMs) have shown promise in this regard, leading to recent proposals for declarative frameworks for LLM-powered unstructured data processing. However, these frameworks focus on reducing cost when executing user-specified operations using LLMs, rather than improving accuracy, executing most operations as-is. This is problematic for complex tasks and data, where LLM outputs for user-defined operations are often inaccurate, even with optimized prompts. We present DocETL, a system that optimizes complex document processing pipelines, while accounting for LLM shortcomings. DocETL offers a declarative interface for users to define such pipelines and uses an agent-based framework to automatically optimize them, leveraging novel agent-based rewrites (that we call {\em rewrite directives}) and an optimization and evaluation framework that we introduce. We introduce {\em (i)} logical rewriting of pipelines, tailored for LLM-based tasks, {\em (ii)} an agent-guided plan evaluation mechanism that synthesizes and orchestrates task-specific validation prompts, and {\em (iii)} an optimization algorithm that efficiently finds promising plans, considering the time constraints of LLM-based plan generation and evaluation. Our evaluation on three different unstructured document analysis tasks demonstrates that DocETL finds plans with outputs that are $1.34$ to $4.6\times$ higher quality (e.g., more accurate, comprehensive) than well-engineered baselines, addressing a critical gap in existing declarative frameworks for unstructured data analysis. DocETL is open-source at \ttt{docetl.org}, and as of October 2024, has amassed over 800 GitHub Stars, with users spanning a variety of domains.
Flood Event Extraction from News Media to Support Satellite-Based Flood Insurance
Dec 05, 2023Floods cause large losses to property, life, and livelihoods across the world every year, hindering sustainable development. Safety nets to help absorb financial shocks in disasters, such as insurance, are often unavailable in regions of the world most vulnerable to floods, like Bangladesh. Index-based insurance has emerged as an affordable solution, which considers weather data or information from satellites to create a "flood index" that should correlate with the damage insured. However, existing flood event databases are often incomplete, and satellite sensors are not reliable under extreme weather conditions (e.g., because of clouds), which limits the spatial and temporal resolution of current approaches for index-based insurance. In this work, we explore a novel approach for supporting satellite-based flood index insurance by extracting high-resolution spatio-temporal information from news media. First, we publish a dataset consisting of 40,000 news articles covering flood events in Bangladesh by 10 prominent news sources, and inundated area estimates for each division in Bangladesh collected from a satellite radar sensor. Second, we show that keyword-based models are not adequate for this novel application, while context-based classifiers cover complex and implicit flood related patterns. Third, we show that time series extracted from news media have substantial correlation Spearman's rho$=0.70 with satellite estimates of inundated area. Our work demonstrates that news media is a promising source for improving the temporal resolution and expanding the spatial coverage of the available flood damage data.
JoinBoost: Grow Trees Over Normalized Data Using Only SQL
Jul 01, 2023
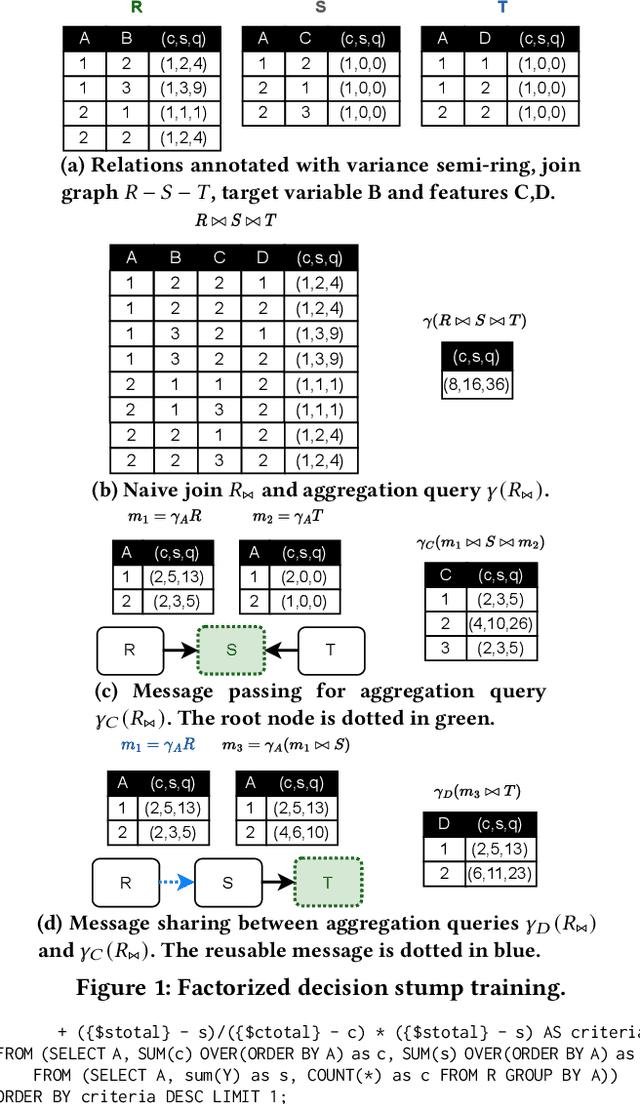
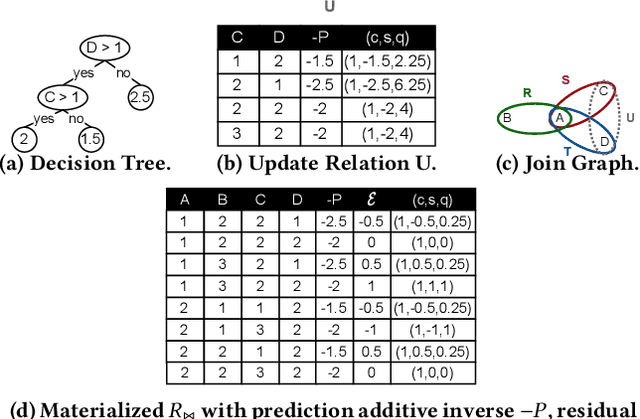

Although dominant for tabular data, ML libraries that train tree models over normalized databases (e.g., LightGBM, XGBoost) require the data to be denormalized as a single table, materialized, and exported. This process is not scalable, slow, and poses security risks. In-DB ML aims to train models within DBMSes to avoid data movement and provide data governance. Rather than modify a DBMS to support In-DB ML, is it possible to offer competitive tree training performance to specialized ML libraries...with only SQL? We present JoinBoost, a Python library that rewrites tree training algorithms over normalized databases into pure SQL. It is portable to any DBMS, offers performance competitive with specialized ML libraries, and scales with the underlying DBMS capabilities. JoinBoost extends prior work from both algorithmic and systems perspectives. Algorithmically, we support factorized gradient boosting, by updating the $Y$ variable to the residual in the non-materialized join result. Although this view update problem is generally ambiguous, we identify addition-to-multiplication preserving, the key property of variance semi-ring to support rmse, the most widely used criterion. System-wise, we identify residual updates as a performance bottleneck. Such overhead can be natively minimized on columnar DBMSes by creating a new column of residual values and adding it as a projection. We validate this with two implementations on DuckDB, with no or minimal modifications to its internals for portability. Our experiment shows that JoinBoost is 3x (1.1x) faster for random forests (gradient boosting) compared to LightGBM, and over an order magnitude faster than state-of-the-art In-DB ML systems. Further, JoinBoost scales well beyond LightGBM in terms of the # features, DB size (TPC-DS SF=1000), and join graph complexity (galaxy schemas).
NL2INTERFACE: Interactive Visualization Interface Generation from Natural Language Queries
Sep 24, 2022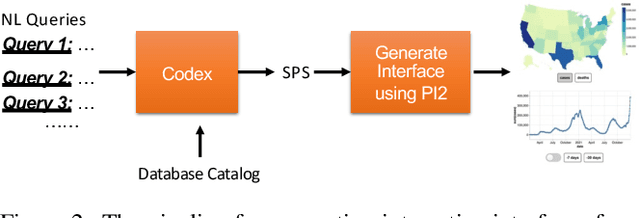
We develop NL2INTERFACE to explore the potential of generating usable interactive multi-visualization interfaces from natural language queries. With NL2INTERFACE, users can directly write natural language queries to automatically generate a fully interactive multi-visualization interface without any extra effort of learning a tool or programming language. Further, users can interact with the interfaces to easily transform the data and quickly see the results in the visualizations.
A Neural Network Solves and Generates Mathematics Problems by Program Synthesis: Calculus, Differential Equations, Linear Algebra, and More
Jan 04, 2022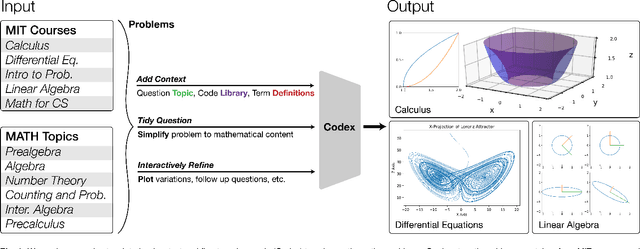
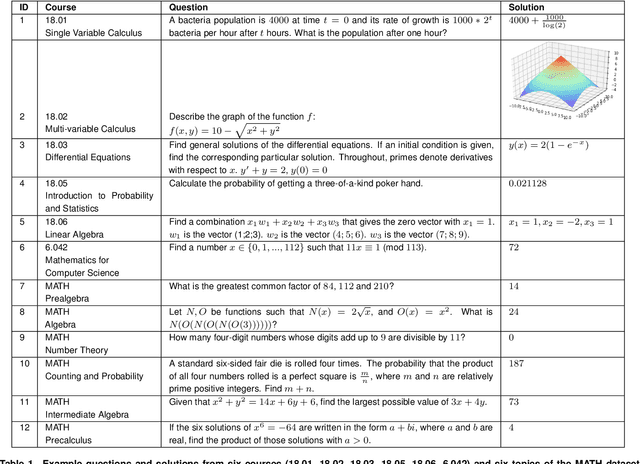
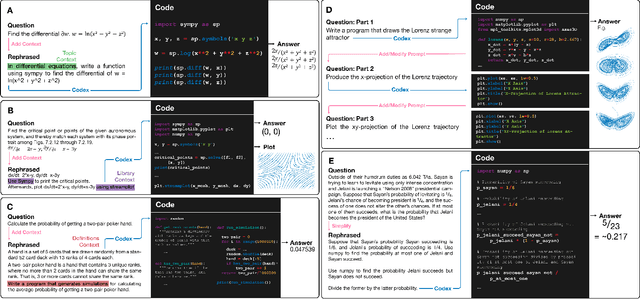
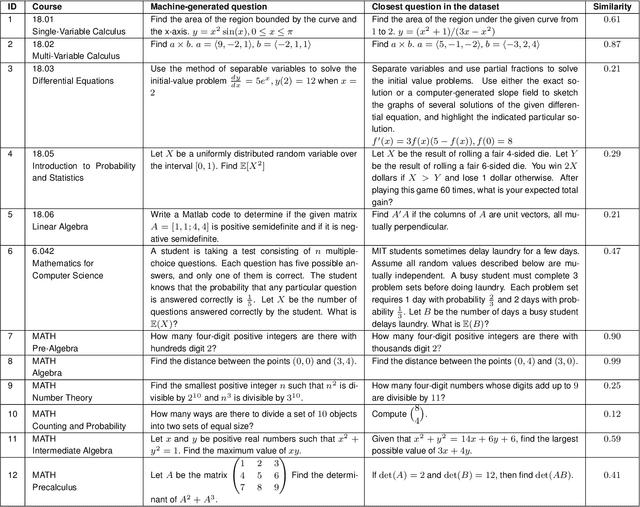
We demonstrate that a neural network pre-trained on text and fine-tuned on code solves Mathematics problems by program synthesis. We turn questions into programming tasks, automatically generate programs, and then execute them, perfectly solving university-level problems from MIT's large Mathematics courses (Single Variable Calculus 18.01, Multivariable Calculus 18.02, Differential Equations 18.03, Introduction to Probability and Statistics 18.05, Linear Algebra 18.06, and Mathematics for Computer Science 6.042), Columbia University's COMS3251 Computational Linear Algebra course, as well as questions from a MATH dataset (on Prealgebra, Algebra, Counting and Probability, Number Theory, and Precalculus), the latest benchmark of advanced mathematics problems specifically designed to assess mathematical reasoning. We explore prompt generation methods that enable Transformers to generate question solving programs for these subjects, including solutions with plots. We generate correct answers for a random sample of questions in each topic. We quantify the gap between the original and transformed questions and perform a survey to evaluate the quality and difficulty of generated questions. This is the first work to automatically solve, grade, and generate university-level Mathematics course questions at scale. This represents a milestone for higher education.
Enabling SQL-based Training Data Debugging for Federated Learning
Aug 26, 2021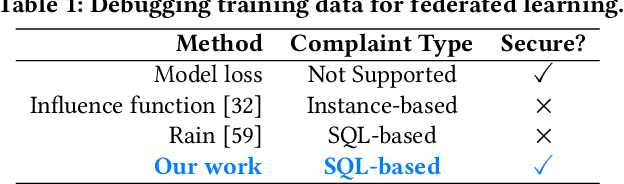
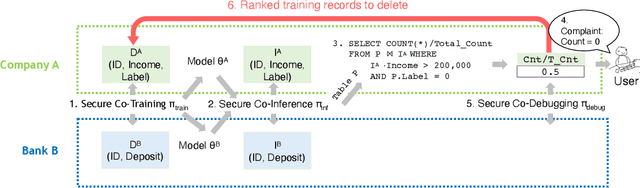


How can we debug a logistical regression model in a federated learning setting when seeing the model behave unexpectedly (e.g., the model rejects all high-income customers' loan applications)? The SQL-based training data debugging framework has proved effective to fix this kind of issue in a non-federated learning setting. Given an unexpected query result over model predictions, this framework automatically removes the label errors from training data such that the unexpected behavior disappears in the retrained model. In this paper, we enable this powerful framework for federated learning. The key challenge is how to develop a security protocol for federated debugging which is proved to be secure, efficient, and accurate. Achieving this goal requires us to investigate how to seamlessly integrate the techniques from multiple fields (Databases, Machine Learning, and Cybersecurity). We first propose FedRain, which extends Rain, the state-of-the-art SQL-based training data debugging framework, to our federated learning setting. We address several technical challenges to make FedRain work and analyze its security guarantee and time complexity. The analysis results show that FedRain falls short in terms of both efficiency and security. To overcome these limitations, we redesign our security protocol and propose Frog, a novel SQL-based training data debugging framework tailored for federated learning. Our theoretical analysis shows that Frog is more secure, more accurate, and more efficient than FedRain. We conduct extensive experiments using several real-world datasets and a case study. The experimental results are consistent with our theoretical analysis and validate the effectiveness of Frog in practice.
Explaining Inference Queries with Bayesian Optimization
Feb 10, 2021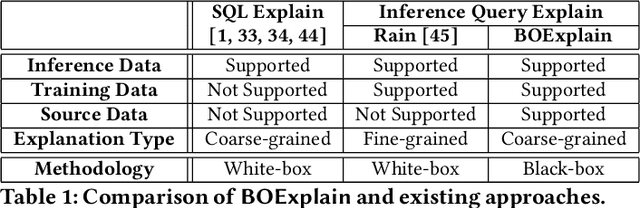
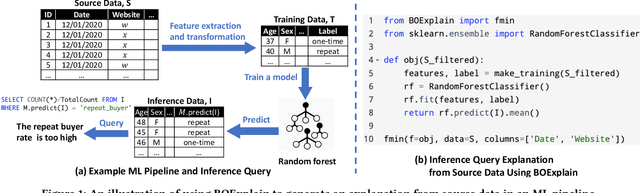
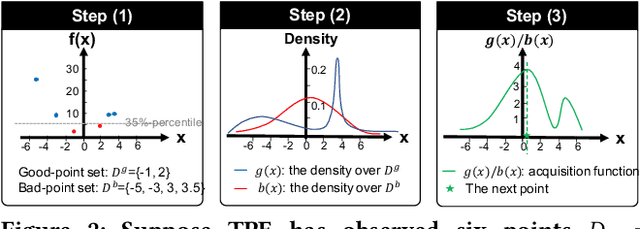
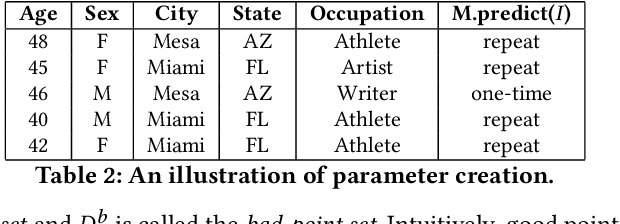
Obtaining an explanation for an SQL query result can enrich the analysis experience, reveal data errors, and provide deeper insight into the data. Inference query explanation seeks to explain unexpected aggregate query results on inference data; such queries are challenging to explain because an explanation may need to be derived from the source, training, or inference data in an ML pipeline. In this paper, we model an objective function as a black-box function and propose BOExplain, a novel framework for explaining inference queries using Bayesian optimization (BO). An explanation is a predicate defining the input tuples that should be removed so that the query result of interest is significantly affected. BO - a technique for finding the global optimum of a black-box function - is used to find the best predicate. We develop two new techniques (individual contribution encoding and warm start) to handle categorical variables. We perform experiments showing that the predicates found by BOExplain have a higher degree of explanation compared to those found by the state-of-the-art query explanation engines. We also show that BOExplain is effective at deriving explanations for inference queries from source and training data on three real-world datasets.
Complaint-driven Training Data Debugging for Query 2.0
Apr 12, 2020As the need for machine learning (ML) increases rapidly across all industry sectors, there is a significant interest among commercial database providers to support "Query 2.0", which integrates model inference into SQL queries. Debugging Query 2.0 is very challenging since an unexpected query result may be caused by the bugs in training data (e.g., wrong labels, corrupted features). In response, we propose Rain, a complaint-driven training data debugging system. Rain allows users to specify complaints over the query's intermediate or final output, and aims to return a minimum set of training examples so that if they were removed, the complaints would be resolved. To the best of our knowledge, we are the first to study this problem. A naive solution requires retraining an exponential number of ML models. We propose two novel heuristic approaches based on influence functions which both require linear retraining steps. We provide an in-depth analytical and empirical analysis of the two approaches and conduct extensive experiments to evaluate their effectiveness using four real-world datasets. Results show that Rain achieves the highest recall@k among all the baselines while still returns results interactively.