 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-Raptor: An Agentic System for Semi-Structured Table QA
Feb 03, 2026Semi-structured table question answering (QA) is a challenging task that requires (1) precise extraction of cell contents and positions and (2) accurate recovery of key implicit logical structures, hierarchical relationships, and semantic associations encoded in table layouts. In practice, such tables are often interpreted manually by human experts, which is labor-intensive and time-consuming. However, automating this process remains difficult. Existing Text-to-SQL methods typically require converting semi-structured tables into structured formats, inevitably leading to information loss, while approaches like Text-to-Code and multimodal LLM-based QA struggle with complex layouts and often yield inaccurate answers. To address these limitations, we present ST-Raptor, an agentic system for semi-structured table QA. ST-Raptor offers an interactive analysis environment that combines visual editing, tree-based structural modeling, and agent-driven query resolution to support accurate and user-friendly table understanding. Experimental results on both benchmark and real-world datasets demonstrate that ST-Raptor outperforms existing methods in both accuracy and usability. The code is available at https://github.com/weAIDB/ST-Raptor, and a demonstration video is available at https://youtu.be/9GDR-94Cau4.
ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
Aug 25, 2025
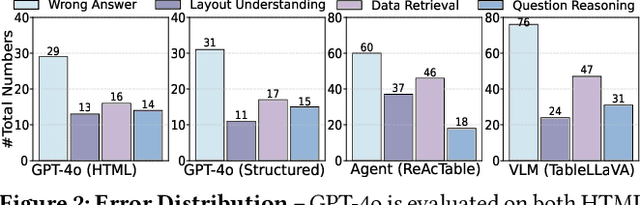
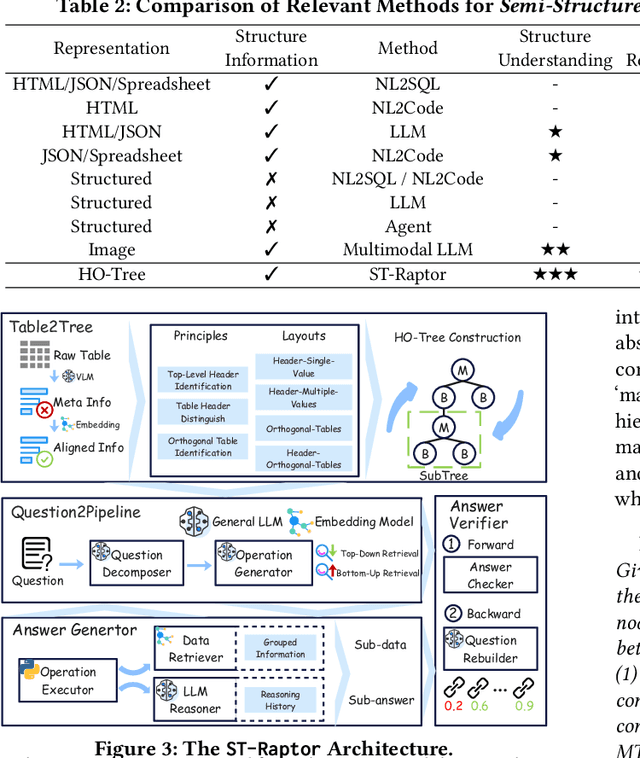

Semi-structured tables, widely used in real-world applications (e.g., financial reports, medical records, transactional orders), often involve flexible and complex layouts (e.g., hierarchical headers and merged cells). These tables generally rely on human analysts to interpret table layouts and answer relevant natural language questions, which is costly and inefficient. To automate the procedure, existing methods face significant challenges. First, methods like NL2SQL require converting semi-structured tables into structured ones, which often causes substantial information loss. Second, methods like NL2Code and multi-modal LLM QA struggle to understand the complex layouts of semi-structured tables and cannot accurately answer corresponding questions. To this end, we propose ST-Raptor, a tree-based framework for semi-structured table question answering using large language models. First, we introduce the Hierarchical Orthogonal Tree (HO-Tree), a structural model that captures complex semi-structured table layouts, along with an effective algorithm for constructing the tree. Second, we define a set of basic tree operations to guide LLMs in executing common QA tasks. Given a user question, ST-Raptor decomposes it into simpler sub-questions, generates corresponding tree operation pipelines, and conducts operation-table alignment for accurate pipeline execution. Third, we incorporate a two-stage verification mechanism: forward validation checks the correctness of execution steps, while backward validation evaluates answer reliability by reconstructing queries from predicted answers. To benchmark the performance, we present SSTQA, a dataset of 764 questions over 102 real-world semi-structured tables. Experiments show that ST-Raptor outperforms nine baselines by up to 20% in answer accuracy. The code is available at https://github.com/weAIDB/ST-Raptor.
ChartCards: A Chart-Metadata Generation Framework for Multi-Task Chart Understanding
May 21, 2025The emergence of Multi-modal Large Language Models (MLLMs) presents new opportunities for chart understanding. However, due to the fine-grained nature of these tasks, applying MLLMs typically requires large, high-quality datasets for task-specific fine-tuning, leading to high data collection and training costs. To address this, we propose ChartCards, a unified chart-metadata generation framework for multi-task chart understanding. ChartCards systematically synthesizes various chart information, including data tables, visualization code, visual elements, and multi-dimensional semantic captions. By structuring this information into organized metadata, ChartCards enables a single chart to support multiple downstream tasks, such as text-to-chart retrieval, chart summarization, chart-to-table conversion, chart description, and chart question answering. Using ChartCards, we further construct MetaChart, a large-scale high-quality dataset containing 10,862 data tables, 85K charts, and 170 K high-quality chart captions. We validate the dataset through qualitative crowdsourcing evaluations and quantitative fine-tuning experiments across various chart understanding tasks. Fine-tuning six different models on MetaChart resulted in an average performance improvement of 5% across all tasks. The most notable improvements are seen in text-to-chart retrieval and chart-to-table tasks, with Long-CLIP and Llama 3.2-11B achieving improvements of 17% and 28%, respectively.
Boosting Text-to-Chart Retrieval through Training with Synthesized Semantic Insights
May 15, 2025Charts are crucial for data analysis and decision-making.Text-to-chart retrieval systems have become increasingly important for Business Intelligence (BI), where users need to find relevant charts that match their analytical needs. These needs can be categorized into precise queries that are well-specified and fuzzy queries that are more exploratory -- both require understanding the semantics and context of the charts. However, existing text-to-chart retrieval solutions often fail to capture the semantic content and contextual information of charts, primarily due to the lack of comprehensive metadata (or semantic insights). To address this limitation, we propose a training data development pipeline that automatically synthesizes hierarchical semantic insights for charts, covering visual patterns (visual-oriented), statistical properties (statistics-oriented), and practical applications (task-oriented), which produces 207,498 semantic insights for 69,166 charts. Based on these, we train a CLIP-based model named ChartFinder to learn better representations of charts for text-to-chart retrieval. Our method leverages rich semantic insights during the training phase to develop a model that understands both visual and semantic aspects of charts.To evaluate text-to-chart retrieval performance, we curate the first benchmark, CRBench, for this task with 21,862 charts and 326 text queries from real-world BI applications, with ground-truth labels verified by the crowd workers.Experiments show that ChartFinder significantly outperforms existing methods in text-to-chart retrieval tasks across various settings. For precise queries, ChartFinder achieves up to 66.9% NDCG@10, which is 11.58% higher than state-of-the-art models. In fuzzy query tasks, our method also demonstrates consistent improvements, with an average increase of 5% across nearly all metrics.
BQSched: A Non-intrusive Scheduler for Batch Concurrent Queries via Reinforcement Learning
Apr 27, 2025



Most large enterprises build predefined data pipelines and execute them periodically to process operational data using SQL queries for various tasks. A key issue in minimizing the overall makespan of these pipelines is the efficient scheduling of concurrent queries within the pipelines. Existing tools mainly rely on simple heuristic rules due to the difficulty of expressing the complex features and mutual influences of queries. The latest reinforcement learning (RL) based methods have the potential to capture these patterns from feedback, but it is non-trivial to apply them directly due to the large scheduling space, high sampling cost, and poor sample utilization. Motivated by these challenges, we propose BQSched, a non-intrusive Scheduler for Batch concurrent Queries via reinforcement learning. Specifically, BQSched designs an attention-based state representation to capture the complex query patterns, and proposes IQ-PPO, an auxiliary task-enhanced proximal policy optimization (PPO) algorithm, to fully exploit the rich signals of Individual Query completion in logs. Based on the RL framework above, BQSched further introduces three optimization strategies, including adaptive masking to prune the action space, scheduling gain-based query clustering to deal with large query sets, and an incremental simulator to reduce sampling cost. To our knowledge, BQSched is the first non-intrusive batch query scheduler via RL. Extensive experiments show that BQSched can significantly improve the efficiency and stability of batch query scheduling, while also achieving remarkable scalability and adaptability in both data and queries. For example, across all DBMSs and scales tested, BQSched reduces the overall makespan of batch queries on TPC-DS benchmark by an average of 34% and 13%, compared with the commonly used heuristic strategy and the adapted RL-based scheduler, respectively.
xDiT: an Inference Engine for Diffusion Transformers (DiTs) with Massive Parallelism
Nov 04, 2024



Diffusion models are pivotal for generating high-quality images and videos. Inspired by the success of OpenAI's Sora, the backbone of diffusion models is evolving from U-Net to Transformer, known as Diffusion Transformers (DiTs). However, generating high-quality content necessitates longer sequence lengths, exponentially increasing the computation required for the attention mechanism, and escalating DiTs inference latency. Parallel inference is essential for real-time DiTs deployments, but relying on a single parallel method is impractical due to poor scalability at large scales. This paper introduces xDiT, a comprehensive parallel inference engine for DiTs. After thoroughly investigating existing DiTs parallel approaches, xDiT chooses Sequence Parallel (SP) and PipeFusion, a novel Patch-level Pipeline Parallel method, as intra-image parallel strategies, alongside CFG parallel for inter-image parallelism. xDiT can flexibly combine these parallel approaches in a hybrid manner, offering a robust and scalable solution. Experimental results on two 8xL40 GPUs (PCIe) nodes interconnected by Ethernet and an 8xA100 (NVLink) node showcase xDiT's exceptional scalability across five state-of-the-art DiTs. Notably, we are the first to demonstrate DiTs scalability on Ethernet-connected GPU clusters. xDiT is available at https://github.com/xdit-project/xDiT.
LATTE: Improving Latex Recognition for Tables and Formulae with Iterative Refinement
Sep 21, 2024



Portable Document Format (PDF) files are dominantly used for storing and disseminating scientific research, legal documents, and tax information. LaTeX is a popular application for creating PDF documents. Despite its advantages, LaTeX is not WYSWYG -- what you see is what you get, i.e., the LaTeX source and rendered PDF images look drastically different, especially for formulae and tables. This gap makes it hard to modify or export LaTeX sources for formulae and tables from PDF images, and existing work is still limited. First, prior work generates LaTeX sources in a single iteration and struggles with complex LaTeX formulae. Second, existing work mainly recognizes and extracts LaTeX sources for formulae; and is incapable or ineffective for tables. This paper proposes LATTE, the first iterative refinement framework for LaTeX recognition. Specifically, we propose delta-view as feedback, which compares and pinpoints the differences between a pair of rendered images of the extracted LaTeX source and the expected correct image. Such delta-view feedback enables our fault localization model to localize the faulty parts of the incorrect recognition more accurately and enables our LaTeX refinement model to repair the incorrect extraction more accurately. LATTE improves the LaTeX source extraction accuracy of both LaTeX formulae and tables, outperforming existing techniques as well as GPT-4V by at least 7.07% of exact match, with a success refinement rate of 46.08% (formula) and 25.51% (table).
PipeFusion: Displaced Patch Pipeline Parallelism for Inference of Diffusion Transformer Models
May 23, 2024This paper introduces PipeFusion, a novel approach that harnesses multi-GPU parallelism to address the high computational and latency challenges of generating high-resolution images with diffusion transformers (DiT) models. PipeFusion splits images into patches and distributes the network layers across multiple devices. It employs a pipeline parallel manner to orchestrate communication and computations. By leveraging the high similarity between the input from adjacent diffusion steps, PipeFusion eliminates the waiting time in the pipeline by reusing the one-step stale feature maps to provide context for the current step. Our experiments demonstrate that it can generate higher image resolution where existing DiT parallel approaches meet OOM. PipeFusion significantly reduces the required communication bandwidth, enabling DiT inference to be hosted on GPUs connected via PCIe rather than the more costly NVLink infrastructure, which substantially lowers the overall operational expenses for serving DiT models. Our code is publicly available at https://github.com/PipeFusion/PipeFusion.
CleanAgent: Automating Data Standardization with LLM-based Agents
Mar 13, 2024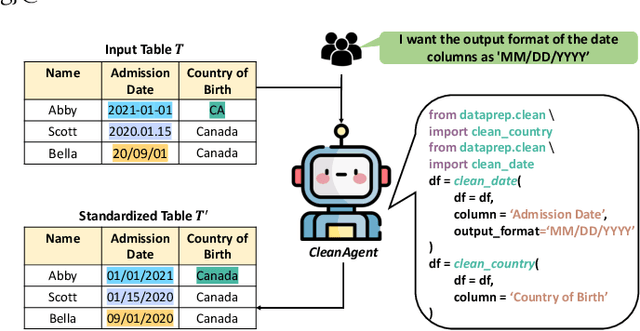
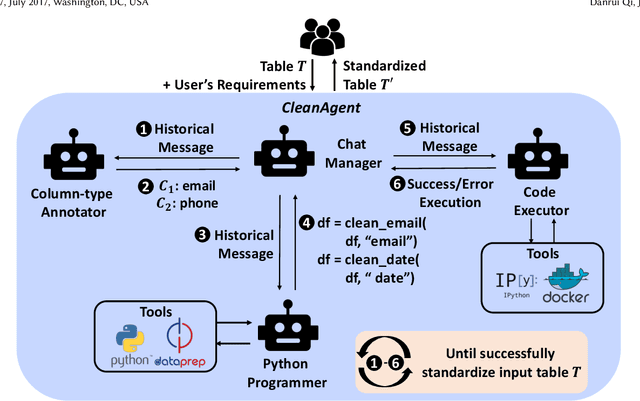
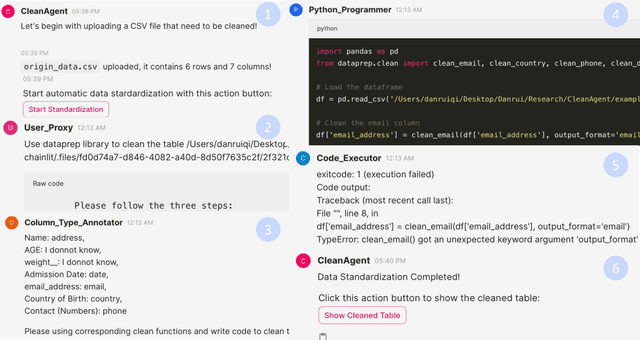
Data standardization is a crucial part in data science life cycle. While tools like Pandas offer robust functionalities, their complexity and the manual effort required for customizing code to diverse column types pose significant challenges. Although large language models (LLMs) like ChatGPT have shown promise in automating this process through natural language understanding and code generation, it still demands expert-level programming knowledge and continuous interaction for prompt refinement. To solve these challenges, our key idea is to propose a Python library with declarative, unified APIs for standardizing column types, simplifying the code generation of LLM with concise API calls. We first propose Dataprep.Clean which is written as a component of the Dataprep Library, offers a significant reduction in complexity by enabling the standardization of specific column types with a single line of code. Then we introduce the CleanAgent framework integrating Dataprep.Clean and LLM-based agents to automate the data standardization process. With CleanAgent, data scientists need only provide their requirements once, allowing for a hands-free, automatic standardization process.
FeatAug: Automatic Feature Augmentation From One-to-Many Relationship Tables
Mar 11, 2024Feature augmentation from one-to-many relationship tables is a critical but challenging problem in ML model development. To augment good features, data scientists need to come up with SQL queries manually, which is time-consuming. Featuretools [1] is a widely used tool by the data science community to automatically augment the training data by extracting new features from relevant tables. It represents each feature as a group-by aggregation SQL query on relevant tables and can automatically generate these SQL queries. However, it does not include predicates in these queries, which significantly limits its application in many real-world scenarios. To overcome this limitation, we propose FEATAUG, a new feature augmentation framework that automatically extracts predicate-aware SQL queries from one-to-many relationship tables. This extension is not trivial because considering predicates will exponentially increase the number of candidate queries. As a result, the original Featuretools framework, which materializes all candidate queries, will not work and needs to be redesigned. We formally define the problem and model it as a hyperparameter optimization problem. We discuss how the Bayesian Optimization can be applied here and propose a novel warm-up strategy to optimize it. To make our algorithm more practical, we also study how to identify promising attribute combinations for predicates. We show that how the beam search idea can partially solve the problem and propose several techniques to further optimize it. Our experiments on four real-world datasets demonstrate that FeatAug extracts more effective features compared to Featuretools and other baselines. The code is open-sourced at https://github.com/sfu-db/FeatAug