 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Software Engineering agent as AI Software Engineer
Jun 17, 2025The growth of Large Language Model (LLM) technology has raised expectations for automated coding. However, software engineering is more than coding and is concerned with activities including maintenance and evolution of a project. In this context, the concept of LLM agents has gained traction, which utilize LLMs as reasoning engines to invoke external tools autonomously. But is an LLM agent the same as an AI software engineer? In this paper, we seek to understand this question by developing a Unified Software Engineering agent or USEagent. Unlike existing work which builds specialized agents for specific software tasks such as testing, debugging, and repair, our goal is to build a unified agent which can orchestrate and handle multiple capabilities. This gives the agent the promise of handling complex scenarios in software development such as fixing an incomplete patch, adding new features, or taking over code written by others. We envision USEagent as the first draft of a future AI Software Engineer which can be a team member in future software development teams involving both AI and humans. To evaluate the efficacy of USEagent, we build a Unified Software Engineering bench (USEbench) comprising of myriad tasks such as coding, testing, and patching. USEbench is a judicious mixture of tasks from existing benchmarks such as SWE-bench, SWT-bench, and REPOCOD. In an evaluation on USEbench consisting of 1,271 repository-level software engineering tasks, USEagent shows improved efficacy compared to existing general agents such as OpenHands CodeActAgent. There exist gaps in the capabilities of USEagent for certain coding tasks, which provides hints on further developing the AI Software Engineer of the future.
The SWE-Bench Illusion: When State-of-the-Art LLMs Remember Instead of Reason
Jun 14, 2025As large language models (LLMs) become increasingly capable and widely adopted, benchmarks play a central role in assessing their practical utility. For example, SWE-Bench Verified has emerged as a critical benchmark for evaluating LLMs' software engineering abilities, particularly their aptitude for resolving real-world GitHub issues. Recent LLMs show impressive performance on SWE-Bench, leading to optimism about their capacity for complex coding tasks. However, current evaluation protocols may overstate these models' true capabilities. It is crucial to distinguish LLMs' generalizable problem-solving ability and other learned artifacts. In this work, we introduce a diagnostic task: file path identification from issue descriptions alone, to probe models' underlying knowledge. We present empirical evidence that performance gains on SWE-Bench-Verified may be partially driven by memorization rather than genuine problem-solving. We show that state-of-the-art models achieve up to 76% accuracy in identifying buggy file paths using only issue descriptions, without access to repository structure. This performance is merely up to 53% on tasks from repositories not included in SWE-Bench, pointing to possible data contamination or memorization. These findings raise concerns about the validity of existing results and underscore the need for more robust, contamination-resistant benchmarks to reliably evaluate LLMs' coding abilities.
Can Language Models Replace Programmers? REPOCOD Says 'Not Yet'
Oct 29, 2024Large language models (LLMs) have shown remarkable ability in code generation with more than 90 pass@1 in solving Python coding problems in HumanEval and MBPP. Such high accuracy leads to the question: can LLMs replace human programmers? Existing manual crafted, simple, or single-line code generation benchmarks cannot answer this question due to their gap with real-world software development. To answer this question, we propose REPOCOD, a code generation benchmark with 980 problems collected from 11 popular real-world projects, with more than 58% of them requiring file-level or repository-level context information. In addition, REPOCOD has the longest average canonical solution length (331.6 tokens) and the highest average cyclomatic complexity (9.00) compared to existing benchmarks. In our evaluations on ten LLMs, none of the models can achieve more than 30 pass@1 on REPOCOD, disclosing the necessity of building stronger LLMs that can help developers in real-world software development.
WAFFLE: Multi-Modal Model for Automated Front-End Development
Oct 24, 2024


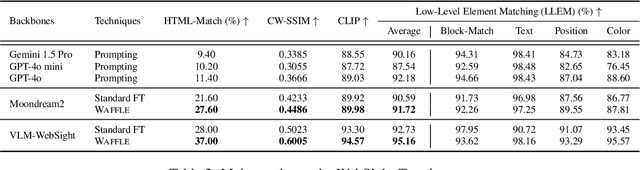
Web development involves turning UI designs into functional webpages, which can be difficult for both beginners and experienced developers due to the complexity of HTML's hierarchical structures and styles. While Large Language Models (LLMs) have shown promise in generating source code, two major challenges persist in UI-to-HTML code generation: (1) effectively representing HTML's hierarchical structure for LLMs, and (2) bridging the gap between the visual nature of UI designs and the text-based format of HTML code. To tackle these challenges, we introduce Waffle, a new fine-tuning strategy that uses a structure-aware attention mechanism to improve LLMs' understanding of HTML's structure and a contrastive fine-tuning approach to align LLMs' understanding of UI images and HTML code. Models fine-tuned with Waffle show up to 9.00 pp (percentage point) higher HTML match, 0.0982 higher CW-SSIM, 32.99 higher CLIP, and 27.12 pp higher LLEM on our new benchmark WebSight-Test and an existing benchmark Design2Code, outperforming current fine-tuning methods.
LATTE: Improving Latex Recognition for Tables and Formulae with Iterative Refinement
Sep 21, 2024



Portable Document Format (PDF) files are dominantly used for storing and disseminating scientific research, legal documents, and tax information. LaTeX is a popular application for creating PDF documents. Despite its advantages, LaTeX is not WYSWYG -- what you see is what you get, i.e., the LaTeX source and rendered PDF images look drastically different, especially for formulae and tables. This gap makes it hard to modify or export LaTeX sources for formulae and tables from PDF images, and existing work is still limited. First, prior work generates LaTeX sources in a single iteration and struggles with complex LaTeX formulae. Second, existing work mainly recognizes and extracts LaTeX sources for formulae; and is incapable or ineffective for tables. This paper proposes LATTE, the first iterative refinement framework for LaTeX recognition. Specifically, we propose delta-view as feedback, which compares and pinpoints the differences between a pair of rendered images of the extracted LaTeX source and the expected correct image. Such delta-view feedback enables our fault localization model to localize the faulty parts of the incorrect recognition more accurately and enables our LaTeX refinement model to repair the incorrect extraction more accurately. LATTE improves the LaTeX source extraction accuracy of both LaTeX formulae and tables, outperforming existing techniques as well as GPT-4V by at least 7.07% of exact match, with a success refinement rate of 46.08% (formula) and 25.51% (table).
CaBaGe: Data-Free Model Extraction using ClAss BAlanced Generator Ensemble
Sep 16, 2024Machine Learning as a Service (MLaaS) is often provided as a pay-per-query, black-box system to clients. Such a black-box approach not only hinders open replication, validation, and interpretation of model results, but also makes it harder for white-hat researchers to identify vulnerabilities in the MLaaS systems. Model extraction is a promising technique to address these challenges by reverse-engineering black-box models. Since training data is typically unavailable for MLaaS models, this paper focuses on the realistic version of it: data-free model extraction. We propose a data-free model extraction approach, CaBaGe, to achieve higher model extraction accuracy with a small number of queries. Our innovations include (1) a novel experience replay for focusing on difficult training samples; (2) an ensemble of generators for steadily producing diverse synthetic data; and (3) a selective filtering process for querying the victim model with harder, more balanced samples. In addition, we create a more realistic setting, for the first time, where the attacker has no knowledge of the number of classes in the victim training data, and create a solution to learn the number of classes on the fly. Our evaluation shows that CaBaGe outperforms existing techniques on seven datasets -- MNIST, FMNIST, SVHN, CIFAR-10, CIFAR-100, ImageNet-subset, and Tiny ImageNet -- with an accuracy improvement of the extracted models by up to 43.13%. Furthermore, the number of queries required to extract a clone model matching the final accuracy of prior work is reduced by up to 75.7%.