 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
Meta-probabilistic Modeling
Jan 08, 2026While probabilistic graphical models can discover latent structure in data, their effectiveness hinges on choosing well-specified models. Identifying such models is challenging in practice, often requiring iterative checking and revision through trial and error. To this end, we propose meta-probabilistic modeling (MPM), a meta-learning algorithm that learns generative model structure directly from multiple related datasets. MPM uses a hierarchical architecture where global model specifications are shared across datasets while local parameters remain dataset-specific. For learning and inference, we propose a tractable VAE-inspired surrogate objective, and optimize it through bi-level optimization: local variables are updated analytically via coordinate ascent, while global parameters are trained with gradient-based methods. We evaluate MPM on object-centric image modeling and sequential text modeling, demonstrating that it adapts generative models to data while recovering meaningful latent representations.
ETR: Outcome-Guided Elastic Trust Regions for Policy Optimization
Jan 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an important paradigm for unlocking reasoning capabilities in large language models, exemplified by the success of OpenAI o1 and DeepSeek-R1. Currently, Group Relative Policy Optimization (GRPO) stands as the dominant algorithm in this domain due to its stable training and critic-free efficiency. However, we argue that GRPO suffers from a structural limitation: it imposes a uniform, static trust region constraint across all samples. This design implicitly assumes signal homogeneity, a premise misaligned with the heterogeneous nature of outcome-driven learning, where advantage magnitudes and variances fluctuate significantly. Consequently, static constraints fail to fully exploit high-quality signals while insufficiently suppressing noise, often precipitating rapid entropy collapse. To address this, we propose \textbf{E}lastic \textbf{T}rust \textbf{R}egions (\textbf{ETR}), a dynamic mechanism that aligns optimization constraints with signal quality. ETR constructs a signal-aware landscape through dual-level elasticity: at the micro level, it scales clipping boundaries based on advantage magnitude to accelerate learning from high-confidence paths; at the macro level, it leverages group variance to implicitly allocate larger update budgets to tasks in the optimal learning zone. Extensive experiments on AIME and MATH benchmarks demonstrate that ETR consistently outperforms GRPO, achieving superior accuracy while effectively mitigating policy entropy degradation to ensure sustained exploration.
Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
Can World Models Benefit VLMs for World Dynamics?
Oct 01, 2025Trained on internet-scale video data, generative world models are increasingly recognized as powerful world simulators that can generate consistent and plausible dynamics over structure, motion, and physics. This raises a natural question: with the advent of strong video foundational models, might they supplant conventional vision encoder paradigms for general-purpose multimodal understanding? While recent studies have begun to explore the potential of world models on common vision tasks, these explorations typically lack a systematic investigation of generic, multimodal tasks. In this work, we strive to investigate the capabilities when world model priors are transferred into Vision-Language Models: we re-purpose a video diffusion model as a generative encoder to perform a single denoising step and treat the resulting latents as a set of visual embedding. We empirically investigate this class of models, which we refer to as World-Language Models (WorldLMs), and we find that generative encoders can capture latents useful for downstream understanding that show distinctions from conventional encoders. Naming our best-performing variant Dynamic Vision Aligner (DyVA), we further discover that this method significantly enhances spatial reasoning abilities and enables single-image models to perform multi-frame reasoning. Through the curation of a suite of visual reasoning tasks, we find DyVA to surpass both open-source and proprietary baselines, achieving state-of-the-art or comparable performance. We attribute these gains to WorldLM's inherited motion-consistency internalization from video pre-training. Finally, we systematically explore extensive model designs to highlight promising directions for future work. We hope our study can pave the way for a new family of VLMs that leverage priors from world models and are on a promising path towards generalist vision learners.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
Path-specific effects for pulse-oximetry guided decisions in critical care
Jun 14, 2025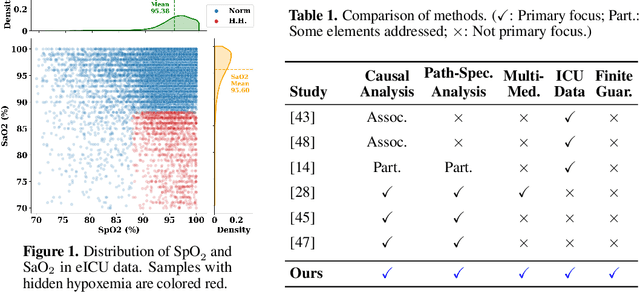
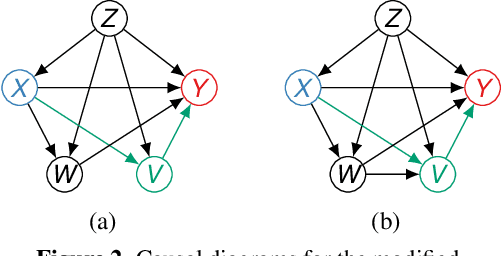
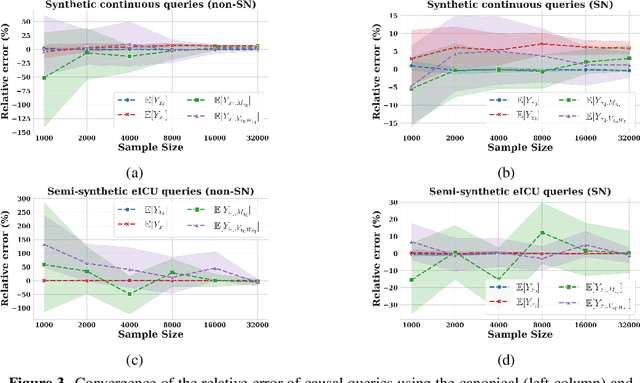
Identifying and measuring biases associated with sensitive attributes is a crucial consideration in healthcare to prevent treatment disparities. One prominent issue is inaccurate pulse oximeter readings, which tend to overestimate oxygen saturation for dark-skinned patients and misrepresent supplemental oxygen needs. Most existing research has revealed statistical disparities linking device errors to patient outcomes in intensive care units (ICUs) without causal formalization. In contrast, this study causally investigates how racial discrepancies in oximetry measurements affect invasive ventilation in ICU settings. We employ a causal inference-based approach using path-specific effects to isolate the impact of bias by race on clinical decision-making. To estimate these effects, we leverage a doubly robust estimator, propose its self-normalized variant for improved sample efficiency, and provide novel finite-sample guarantees. Our methodology is validated on semi-synthetic data and applied to two large real-world health datasets: MIMIC-IV and eICU. Contrary to prior work, our analysis reveals minimal impact of racial discrepancies on invasive ventilation rates. However, path-specific effects mediated by oxygen saturation disparity are more pronounced on ventilation duration, and the severity differs by dataset. Our work provides a novel and practical pipeline for investigating potential disparities in the ICU and, more crucially, highlights the necessity of causal methods to robustly assess fairness in decision-making.
OAM-Assisted Self-Healing Is Directional, Proportional and Persistent
Apr 02, 2025In this paper we demonstrate the postulated mechanism of self-healing specifically due to orbital-angular-momentum (OAM) in radio vortex beams having equal beam-widths. In previous work we experimentally demonstrated self-healing effects in OAM beams at 28 GHz and postulated a theoretical mechanism to account for them. In this work we further characterize the OAM self-healing mechanism theoretically and confirm those characteristics with systematic and controlled experimental measurements on a 28 GHz outdoor link. Specifically, we find that the OAM self-healing mechanism is an additional self-healing mechanism in structured electromagnetic beams which is directional with respect to the displacement of an obstruction relative to the beam axis. We also confirm our previous findings that the amount of OAM self-healing is proportional to the OAM order, and additionally find that it persists beyond the focusing region into the far field. As such, OAM-assisted self-healing brings an advantage over other so-called non-diffracting beams both in terms of the minimum distance for onset of self-healing and the amount of self-healing obtainable. We relate our findings by extending theoretical models in the literature and develop a unifying electromagnetic analysis to account for self-healing of OAM-bearing non-diffracting beams more rigorously.
Acoustic Neural 3D Reconstruction Under Pose Drift
Mar 11, 2025We consider the problem of optimizing neural implicit surfaces for 3D reconstruction using acoustic images collected with drifting sensor poses. The accuracy of current state-of-the-art 3D acoustic modeling algorithms is highly dependent on accurate pose estimation; small errors in sensor pose can lead to severe reconstruction artifacts. In this paper, we propose an algorithm that jointly optimizes the neural scene representation and sonar poses. Our algorithm does so by parameterizing the 6DoF poses as learnable parameters and backpropagating gradients through the neural renderer and implicit representation. We validated our algorithm on both real and simulated datasets. It produces high-fidelity 3D reconstructions even under significant pose drift.
MedicalNarratives: Connecting Medical Vision and Language with Localized Narratives
Jan 07, 2025



We propose MedicalNarratives, a dataset curated from medical pedagogical videos similar in nature to data collected in Think-Aloud studies and inspired by Localized Narratives, which collects grounded image-text data by curating instructors' speech and mouse cursor movements synchronized in time. MedicalNarratives enables pretraining of both semantic and dense objectives, alleviating the need to train medical semantic and dense tasks disparately due to the lack of reasonably sized datasets. Our dataset contains 4.7M image-text pairs from videos and articles, with 1M samples containing dense annotations in the form of traces and bounding boxes. To evaluate the utility of MedicalNarratives, we train GenMedClip based on the CLIP architecture using our dataset spanning 12 medical domains and demonstrate that it outperforms previous state-of-the-art models on a newly constructed medical imaging benchmark that comprehensively evaluates performance across all modalities. Data, demo, code and models available at https://medical-narratives.github.io