 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTLD: Sim-to-real Privileged Tactile Latent Distillation for Dexterous Manipulation
Mar 04, 2026Tactile dexterous manipulation is essential to automating complex household tasks, yet learning effective control policies remains a challenge. While recent work has relied on imitation learning, obtaining high quality demonstrations for multi-fingered hands via robot teleoperation or kinesthetic teaching is prohibitive. Alternatively, with reinforcement we can learn skills in simulation, but fast and realistic simulation of tactile observations is challenging. To bridge this gap, we introduce PTLD: sim-to-real Privileged Tactile Latent Distillation, a novel approach to learning tactile manipulation skills without requiring tactile simulation. Instead of simulating tactile sensors or relying purely on proprioceptive policies to transfer zero-shot sim-to-real, our key idea is to leverage privileged sensors in the real world to collect real-world tactile policy data. This data is then used to distill a robust state estimator that operates on tactile input. We demonstrate from our experiments that PTLD can be used to improve proprioceptive manipulation policies trained in simulation significantly by incorporating tactile sensing. On the benchmark in-hand rotation task, PTLD achieves a 182% improvement over a proprioception only policy. We also show that PTLD enables learning the challenging task of tactile in-hand reorientation where we see a 57% improvement in the number of goals reached over using proprioception alone. Website: https://akashsharma02.github.io/ptld-website/.
riMESA: Consensus ADMM for Real-World Collaborative SLAM
Mar 01, 2026Collaborative Simultaneous Localization and Mapping (C-SLAM) is a fundamental capability for multi-robot teams as it enables downstream tasks like planning and navigation. However, existing C-SLAM back-end algorithms that are required to solve this problem struggle to address the practical realities of real-world deployments (i.e. communication limitations, outlier measurements, and online operation). In this paper we propose Robust Incremental Manifold Edge-based Separable ADMM (riMESA) -- a robust, incremental, and distributed C-SLAM back-end that is resilient to outliers, reliable in the face of limited communication, and can compute accurate state estimates for a multi-robot team in real-time. Through the development of riMESA, we, more broadly, make an argument for the use of Consensus Alternating Direction Method of Multipliers as a theoretical foundation for distributed optimization tasks in robotics like C-SLAM due to its flexibility, accuracy, and fast convergence. We conclude this work with an in-depth evaluation of riMESA on a variety of C-SLAM problem scenarios and communication network conditions using both synthetic and real-world C-SLAM data. These experiments demonstrate that riMESA is able to generalize across conditions, produce accurate state estimates, operate in real-time, and outperform the accuracy of prior works by a factor >7x on real-world datasets.
Tactile Beyond Pixels: Multisensory Touch Representations for Robot Manipulation
Jun 17, 2025We present Sparsh-X, the first multisensory touch representations across four tactile modalities: image, audio, motion, and pressure. Trained on ~1M contact-rich interactions collected with the Digit 360 sensor, Sparsh-X captures complementary touch signals at diverse temporal and spatial scales. By leveraging self-supervised learning, Sparsh-X fuses these modalities into a unified representation that captures physical properties useful for robot manipulation tasks. We study how to effectively integrate real-world touch representations for both imitation learning and tactile adaptation of sim-trained policies, showing that Sparsh-X boosts policy success rates by 63% over an end-to-end model using tactile images and improves robustness by 90% in recovering object states from touch. Finally, we benchmark Sparsh-X ability to make inferences about physical properties, such as object-action identification, material-quantity estimation, and force estimation. Sparsh-X improves accuracy in characterizing physical properties by 48% compared to end-to-end approaches, demonstrating the advantages of multisensory pretraining for capturing features essential for dexterous manipulation.
Self-supervised perception for tactile skin covered dexterous hands
May 16, 2025We present Sparsh-skin, a pre-trained encoder for magnetic skin sensors distributed across the fingertips, phalanges, and palm of a dexterous robot hand. Magnetic tactile skins offer a flexible form factor for hand-wide coverage with fast response times, in contrast to vision-based tactile sensors that are restricted to the fingertips and limited by bandwidth. Full hand tactile perception is crucial for robot dexterity. However, a lack of general-purpose models, challenges with interpreting magnetic flux and calibration have limited the adoption of these sensors. Sparsh-skin, given a history of kinematic and tactile sensing across a hand, outputs a latent tactile embedding that can be used in any downstream task. The encoder is self-supervised via self-distillation on a variety of unlabeled hand-object interactions using an Allegro hand sensorized with Xela uSkin. In experiments across several benchmark tasks, from state estimation to policy learning, we find that pretrained Sparsh-skin representations are both sample efficient in learning downstream tasks and improve task performance by over 41% compared to prior work and over 56% compared to end-to-end learning.
Acoustic Neural 3D Reconstruction Under Pose Drift
Mar 11, 2025We consider the problem of optimizing neural implicit surfaces for 3D reconstruction using acoustic images collected with drifting sensor poses. The accuracy of current state-of-the-art 3D acoustic modeling algorithms is highly dependent on accurate pose estimation; small errors in sensor pose can lead to severe reconstruction artifacts. In this paper, we propose an algorithm that jointly optimizes the neural scene representation and sonar poses. Our algorithm does so by parameterizing the 6DoF poses as learnable parameters and backpropagating gradients through the neural renderer and implicit representation. We validated our algorithm on both real and simulated datasets. It produces high-fidelity 3D reconstructions even under significant pose drift.
Your Learned Constraint is Secretly a Backward Reachable Tube
Jan 26, 2025Inverse Constraint Learning (ICL) is the problem of inferring constraints from safe (i.e., constraint-satisfying) demonstrations. The hope is that these inferred constraints can then be used downstream to search for safe policies for new tasks and, potentially, under different dynamics. Our paper explores the question of what mathematical entity ICL recovers. Somewhat surprisingly, we show that both in theory and in practice, ICL recovers the set of states where failure is inevitable, rather than the set of states where failure has already happened. In the language of safe control, this means we recover a backwards reachable tube (BRT) rather than a failure set. In contrast to the failure set, the BRT depends on the dynamics of the data collection system. We discuss the implications of the dynamics-conditionedness of the recovered constraint on both the sample-efficiency of policy search and the transferability of learned constraints.
NormalFlow: Fast, Robust, and Accurate Contact-based Object 6DoF Pose Tracking with Vision-based Tactile Sensors
Dec 12, 2024Tactile sensing is crucial for robots aiming to achieve human-level dexterity. Among tactile-dependent skills, tactile-based object tracking serves as the cornerstone for many tasks, including manipulation, in-hand manipulation, and 3D reconstruction. In this work, we introduce NormalFlow, a fast, robust, and real-time tactile-based 6DoF tracking algorithm. Leveraging the precise surface normal estimation of vision-based tactile sensors, NormalFlow determines object movements by minimizing discrepancies between the tactile-derived surface normals. Our results show that NormalFlow consistently outperforms competitive baselines and can track low-texture objects like table surfaces. For long-horizon tracking, we demonstrate when rolling the sensor around a bead for 360 degrees, NormalFlow maintains a rotational tracking error of 2.5 degrees. Additionally, we present state-of-the-art tactile-based 3D reconstruction results, showcasing the high accuracy of NormalFlow. We believe NormalFlow unlocks new possibilities for high-precision perception and manipulation tasks that involve interacting with objects using hands. The video demo, code, and dataset are available on our website: https://joehjhuang.github.io/normalflow.
* 8 pages, published in 2024 RA-L, website link: https://joehjhuang.github.io/normalflow
Sparsh: Self-supervised touch representations for vision-based tactile sensing
Oct 31, 2024In this work, we introduce general purpose touch representations for the increasingly accessible class of vision-based tactile sensors. Such sensors have led to many recent advances in robot manipulation as they markedly complement vision, yet solutions today often rely on task and sensor specific handcrafted perception models. Collecting real data at scale with task centric ground truth labels, like contact forces and slip, is a challenge further compounded by sensors of various form factor differing in aspects like lighting and gel markings. To tackle this we turn to self-supervised learning (SSL) that has demonstrated remarkable performance in computer vision. We present Sparsh, a family of SSL models that can support various vision-based tactile sensors, alleviating the need for custom labels through pre-training on 460k+ tactile images with masking and self-distillation in pixel and latent spaces. We also build TacBench, to facilitate standardized benchmarking across sensors and models, comprising of six tasks ranging from comprehending tactile properties to enabling physical perception and manipulation planning. In evaluations, we find that SSL pre-training for touch representation outperforms task and sensor-specific end-to-end training by 95.1% on average over TacBench, and Sparsh (DINO) and Sparsh (IJEPA) are the most competitive, indicating the merits of learning in latent space for tactile images. Project page: https://sparsh-ssl.github.io/
LiPO: LiDAR Inertial Odometry for ICP Comparison
Oct 10, 2024
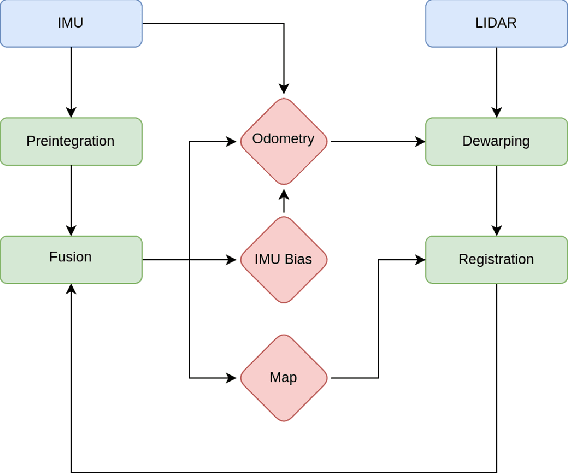
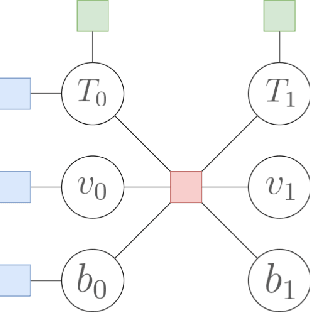
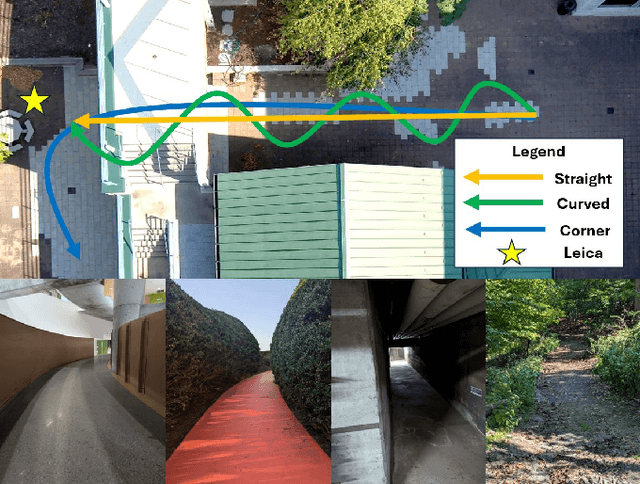
We introduce a LiDAR inertial odometry (LIO) framework, called LiPO, that enables direct comparisons of different iterative closest point (ICP) point cloud registration methods. The two common ICP methods we compare are point-to-point (P2P) and point-to-feature (P2F). In our experience, within the context of LIO, P2F-ICP results in less drift and improved mapping accuracy when robots move aggressively through challenging environments when compared to P2P-ICP. However, P2F-ICP methods require more hand-tuned hyper-parameters that make P2F-ICP less general across all environments and motions. In real-world field robotics applications where robots are used across different environments, more general P2P-ICP methods may be preferred despite increased drift. In this paper, we seek to better quantify the trade-off between P2P-ICP and P2F-ICP to help inform when each method should be used. To explore this trade-off, we use LiPO to directly compare ICP methods and test on relevant benchmark datasets as well as on our custom unpiloted ground vehicle (UGV). We find that overall, P2F-ICP has reduced drift and improved mapping accuracy, but, P2P-ICP is more consistent across all environments and motions with minimal drift increase.
BEVLoc: Cross-View Localization and Matching via Birds-Eye-View Synthesis
Oct 08, 2024



Ground to aerial matching is a crucial and challenging task in outdoor robotics, particularly when GPS is absent or unreliable. Structures like buildings or large dense forests create interference, requiring GNSS replacements for global positioning estimates. The true difficulty lies in reconciling the perspective difference between the ground and air images for acceptable localization. Taking inspiration from the autonomous driving community, we propose a novel framework for synthesizing a birds-eye-view (BEV) scene representation to match and localize against an aerial map in off-road environments. We leverage contrastive learning with domain specific hard negative mining to train a network to learn similar representations between the synthesized BEV and the aerial map. During inference, BEVLoc guides the identification of the most probable locations within the aerial map through a coarse-to-fine matching strategy. Our results demonstrate promising initial outcomes in extremely difficult forest environments with limited semantic diversity. We analyze our model's performance for coarse and fine matching, assessing both the raw matching capability of our model and its performance as a GNSS replacement. Our work delves into off-road map localization while establishing a foundational baseline for future developments in localization. Our code is available at: https://github.com/rpl-cmu/bevloc