 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM 3D Body: Robust Full-Body Human Mesh Recovery
Feb 17, 2026We introduce SAM 3D Body (3DB), a promptable model for single-image full-body 3D human mesh recovery (HMR) that demonstrates state-of-the-art performance, with strong generalization and consistent accuracy in diverse in-the-wild conditions. 3DB estimates the human pose of the body, feet, and hands. It is the first model to use a new parametric mesh representation, Momentum Human Rig (MHR), which decouples skeletal structure and surface shape. 3DB employs an encoder-decoder architecture and supports auxiliary prompts, including 2D keypoints and masks, enabling user-guided inference similar to the SAM family of models. We derive high-quality annotations from a multi-stage annotation pipeline that uses various combinations of manual keypoint annotation, differentiable optimization, multi-view geometry, and dense keypoint detection. Our data engine efficiently selects and processes data to ensure data diversity, collecting unusual poses and rare imaging conditions. We present a new evaluation dataset organized by pose and appearance categories, enabling nuanced analysis of model behavior. Our experiments demonstrate superior generalization and substantial improvements over prior methods in both qualitative user preference studies and traditional quantitative analysis. Both 3DB and MHR are open-source.
Tactile Beyond Pixels: Multisensory Touch Representations for Robot Manipulation
Jun 17, 2025We present Sparsh-X, the first multisensory touch representations across four tactile modalities: image, audio, motion, and pressure. Trained on ~1M contact-rich interactions collected with the Digit 360 sensor, Sparsh-X captures complementary touch signals at diverse temporal and spatial scales. By leveraging self-supervised learning, Sparsh-X fuses these modalities into a unified representation that captures physical properties useful for robot manipulation tasks. We study how to effectively integrate real-world touch representations for both imitation learning and tactile adaptation of sim-trained policies, showing that Sparsh-X boosts policy success rates by 63% over an end-to-end model using tactile images and improves robustness by 90% in recovering object states from touch. Finally, we benchmark Sparsh-X ability to make inferences about physical properties, such as object-action identification, material-quantity estimation, and force estimation. Sparsh-X improves accuracy in characterizing physical properties by 48% compared to end-to-end approaches, demonstrating the advantages of multisensory pretraining for capturing features essential for dexterous manipulation.
Self-supervised perception for tactile skin covered dexterous hands
May 16, 2025We present Sparsh-skin, a pre-trained encoder for magnetic skin sensors distributed across the fingertips, phalanges, and palm of a dexterous robot hand. Magnetic tactile skins offer a flexible form factor for hand-wide coverage with fast response times, in contrast to vision-based tactile sensors that are restricted to the fingertips and limited by bandwidth. Full hand tactile perception is crucial for robot dexterity. However, a lack of general-purpose models, challenges with interpreting magnetic flux and calibration have limited the adoption of these sensors. Sparsh-skin, given a history of kinematic and tactile sensing across a hand, outputs a latent tactile embedding that can be used in any downstream task. The encoder is self-supervised via self-distillation on a variety of unlabeled hand-object interactions using an Allegro hand sensorized with Xela uSkin. In experiments across several benchmark tasks, from state estimation to policy learning, we find that pretrained Sparsh-skin representations are both sample efficient in learning downstream tasks and improve task performance by over 41% compared to prior work and over 56% compared to end-to-end learning.
Sparsh: Self-supervised touch representations for vision-based tactile sensing
Oct 31, 2024In this work, we introduce general purpose touch representations for the increasingly accessible class of vision-based tactile sensors. Such sensors have led to many recent advances in robot manipulation as they markedly complement vision, yet solutions today often rely on task and sensor specific handcrafted perception models. Collecting real data at scale with task centric ground truth labels, like contact forces and slip, is a challenge further compounded by sensors of various form factor differing in aspects like lighting and gel markings. To tackle this we turn to self-supervised learning (SSL) that has demonstrated remarkable performance in computer vision. We present Sparsh, a family of SSL models that can support various vision-based tactile sensors, alleviating the need for custom labels through pre-training on 460k+ tactile images with masking and self-distillation in pixel and latent spaces. We also build TacBench, to facilitate standardized benchmarking across sensors and models, comprising of six tasks ranging from comprehending tactile properties to enabling physical perception and manipulation planning. In evaluations, we find that SSL pre-training for touch representation outperforms task and sensor-specific end-to-end training by 95.1% on average over TacBench, and Sparsh (DINO) and Sparsh (IJEPA) are the most competitive, indicating the merits of learning in latent space for tactile images. Project page: https://sparsh-ssl.github.io/
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation
Dec 20, 2023To achieve human-level dexterity, robots must infer spatial awareness from multimodal sensing to reason over contact interactions. During in-hand manipulation of novel objects, such spatial awareness involves estimating the object's pose and shape. The status quo for in-hand perception primarily employs vision, and restricts to tracking a priori known objects. Moreover, visual occlusion of objects in-hand is imminent during manipulation, preventing current systems to push beyond tasks without occlusion. We combine vision and touch sensing on a multi-fingered hand to estimate an object's pose and shape during in-hand manipulation. Our method, NeuralFeels, encodes object geometry by learning a neural field online and jointly tracks it by optimizing a pose graph problem. We study multimodal in-hand perception in simulation and the real-world, interacting with different objects via a proprioception-driven policy. Our experiments show final reconstruction F-scores of $81$% and average pose drifts of $4.7\,\text{mm}$, further reduced to $2.3\,\text{mm}$ with known CAD models. Additionally, we observe that under heavy visual occlusion we can achieve up to $94$% improvements in tracking compared to vision-only methods. Our results demonstrate that touch, at the very least, refines and, at the very best, disambiguates visual estimates during in-hand manipulation. We release our evaluation dataset of 70 experiments, FeelSight, as a step towards benchmarking in this domain. Our neural representation driven by multimodal sensing can serve as a perception backbone towards advancing robot dexterity. Videos can be found on our project website https://suddhu.github.io/neural-feels/
Decentralization and Acceleration Enables Large-Scale Bundle Adjustment
May 15, 2023



Scaling to arbitrarily large bundle adjustment problems requires data and compute to be distributed across multiple devices. Centralized methods in prior works are only able to solve small or medium size problems due to overhead in computation and communication. In this paper, we present a fully decentralized method that alleviates computation and communication bottlenecks to solve arbitrarily large bundle adjustment problems. We achieve this by reformulating the reprojection error and deriving a novel surrogate function that decouples optimization variables from different devices. This function makes it possible to use majorization minimization techniques and reduces bundle adjustment to independent optimization subproblems that can be solved in parallel. We further apply Nesterov's acceleration and adaptive restart to improve convergence while maintaining its theoretical guarantees. Despite limited peer-to-peer communication, our method has provable convergence to first-order critical points under mild conditions. On extensive benchmarks with public datasets, our method converges much faster than decentralized baselines with similar memory usage and communication load. Compared to centralized baselines using a single device, our method, while being decentralized, yields more accurate solutions with significant speedups of up to 953.7x over Ceres and 174.6x over DeepLM. Code: https://github.com/facebookresearch/DABA.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022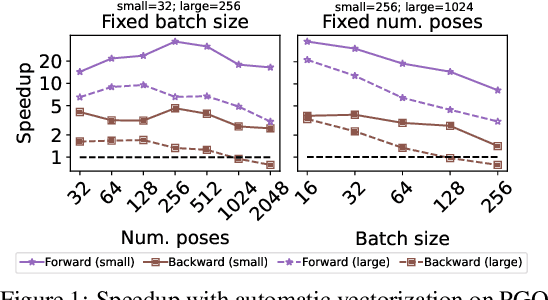
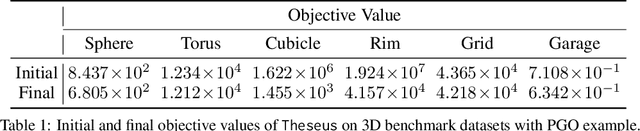
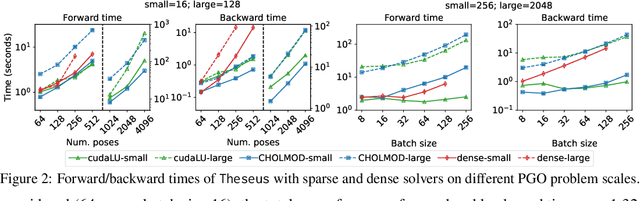
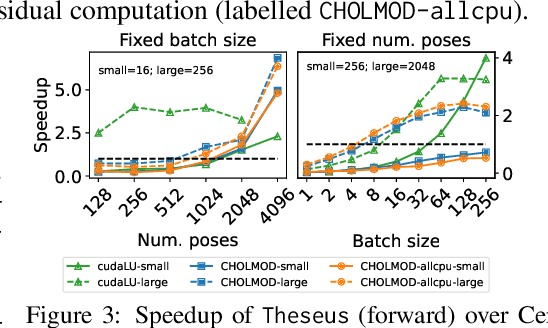
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai
Majorization Minimization Methods for Distributed Pose Graph Optimization
Aug 03, 2021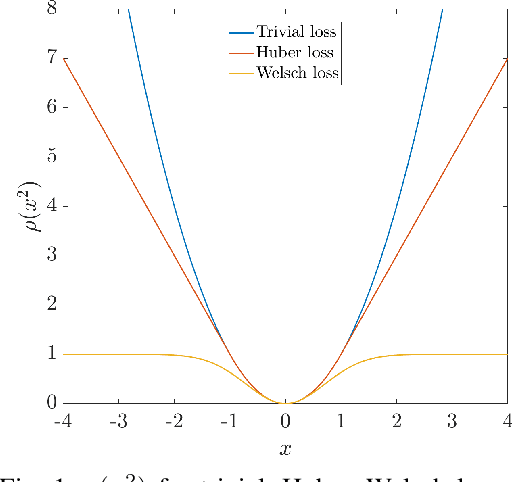
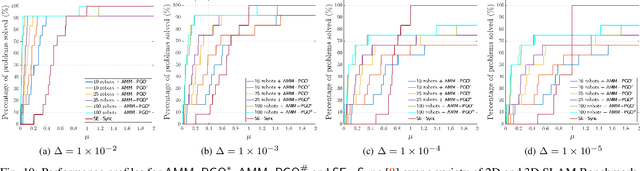
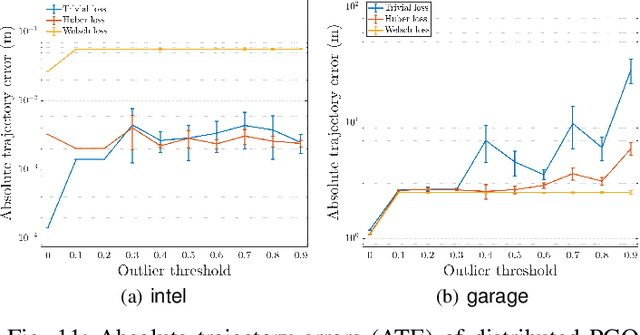

We consider the problem of distributed pose graph optimization (PGO) that has important applications in multi-robot simultaneous localization and mapping (SLAM). We propose the majorization minimization (MM) method for distributed PGO ($\mathsf{MM\!\!-\!\!PGO}$) that applies to a broad class of robust loss kernels. The $\mathsf{MM\!\!-\!\!PGO}$ method is guaranteed to converge to first-order critical points under mild conditions. Furthermore, noting that the $\mathsf{MM\!\!-\!\!PGO}$ method is reminiscent of proximal methods, we leverage Nesterov's method and adopt adaptive restarts to accelerate convergence. The resulting accelerated MM methods for distributed PGO -- both with a master node in the network ($\mathsf{AMM\!\!-\!\!PGO}^*$) and without ($\mathsf{AMM\!\!-\!\!PGO}^{\#}$) -- have faster convergence in contrast to the $\mathsf{MM\!\!-\!\!PGO}$ method without sacrificing theoretical guarantees. In particular, the $\mathsf{AMM\!\!-\!\!PGO}^{\#}$ method, which needs no master node and is fully decentralized, features a novel adaptive restart scheme and has a rate of convergence comparable to that of the $\mathsf{AMM\!\!-\!\!PGO}^*$ method using a master node to aggregate information from all the other nodes. The efficacy of this work is validated through extensive applications to 2D and 3D SLAM benchmark datasets and comprehensive comparisons against existing state-of-the-art methods, indicating that our MM methods converge faster and result in better solutions to distributed PGO.
Revitalizing Optimization for 3D Human Pose and Shape Estimation: A Sparse Constrained Formulation
May 28, 2021
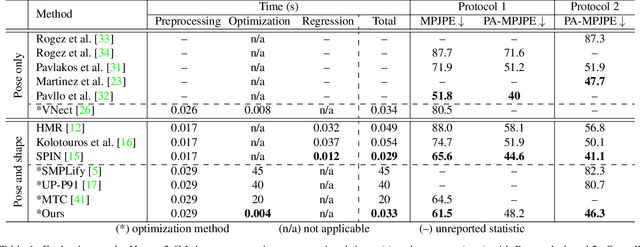

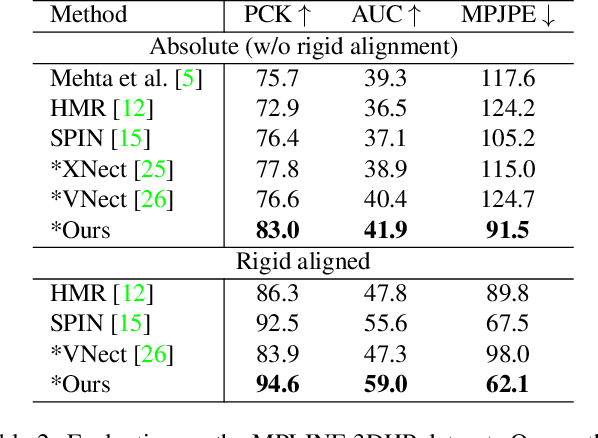
We propose a novel sparse constrained formulation and from it derive a real-time optimization method for 3D human pose and shape estimation. Our optimization method is orders of magnitude faster (avg. 4 ms convergence) than existing optimization methods, while being mathematically equivalent to their dense unconstrained formulation. We achieve this by exploiting the underlying sparsity and constraints of our formulation to efficiently compute the Gauss-Newton direction. We show that this computation scales linearly with the number of joints of a complex 3D human model, in contrast to prior work where it scales cubically due to their dense unconstrained formulation. Based on our optimization method, we present a real-time motion capture framework that estimates 3D human poses and shapes from a single image at over 30 FPS. In benchmarks against state-of-the-art methods on multiple public datasets, our frame-work outperforms other optimization methods and achieves competitive accuracy against regression methods.
Generalized Proximal Methods for Pose Graph Optimization
Dec 04, 2020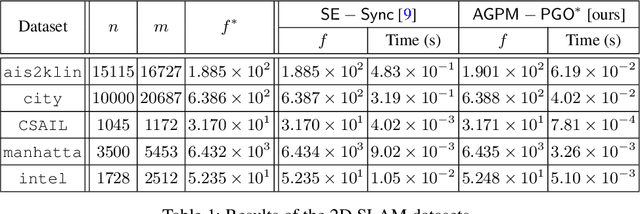
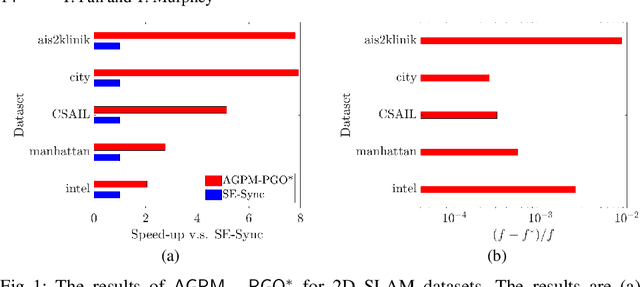
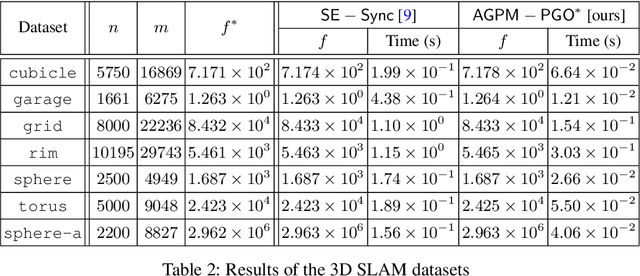
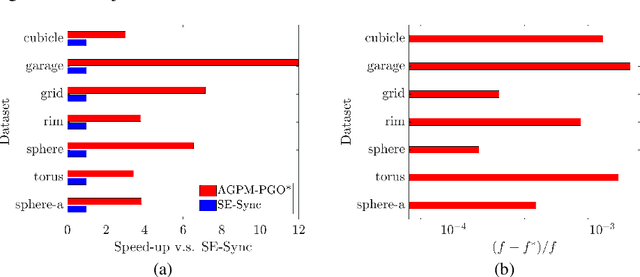
In this paper, we generalize proximal methods that were originally designed for convex optimization on normed vector space to non-convex pose graph optimization (PGO) on special Euclidean groups, and show that our proposed generalized proximal methods for PGO converge to first-order critical points. Furthermore, we propose methods that significantly accelerate the rates of convergence almost without loss of any theoretical guarantees. In addition, our proposed methods can be easily distributed and parallelized with no compromise of efficiency. The efficacy of this work is validated through implementation on simultaneous localization and mapping (SLAM) and distributed 3D sensor network localization, which indicate that our proposed methods are a lot faster than existing techniques to converge to sufficient accuracy for practical use.
* 29 pages