 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Egocentric Visual-Inertial SLAM at City Scale
Sep 30, 2025Precise 6-DoF simultaneous localization and mapping (SLAM) from onboard sensors is critical for wearable devices capturing egocentric data, which exhibits specific challenges, such as a wider diversity of motions and viewpoints, prevalent dynamic visual content, or long sessions affected by time-varying sensor calibration. While recent progress on SLAM has been swift, academic research is still driven by benchmarks that do not reflect these challenges or do not offer sufficiently accurate ground truth poses. In this paper, we introduce a new dataset and benchmark for visual-inertial SLAM with egocentric, multi-modal data. We record hours and kilometers of trajectories through a city center with glasses-like devices equipped with various sensors. We leverage surveying tools to obtain control points as indirect pose annotations that are metric, centimeter-accurate, and available at city scale. This makes it possible to evaluate extreme trajectories that involve walking at night or traveling in a vehicle. We show that state-of-the-art systems developed by academia are not robust to these challenges and we identify components that are responsible for this. In addition, we design tracks with different levels of difficulty to ease in-depth analysis and evaluation of less mature approaches. The dataset and benchmark are available at https://www.lamaria.ethz.ch.
Photoreal Scene Reconstruction from an Egocentric Device
Jun 04, 2025In this paper, we investigate the challenges associated with using egocentric devices to photorealistic reconstruct the scene in high dynamic range. Existing methodologies typically assume using frame-rate 6DoF pose estimated from the device's visual-inertial odometry system, which may neglect crucial details necessary for pixel-accurate reconstruction. This study presents two significant findings. Firstly, in contrast to mainstream work treating RGB camera as global shutter frame-rate camera, we emphasize the importance of employing visual-inertial bundle adjustment (VIBA) to calibrate the precise timestamps and movement of the rolling shutter RGB sensing camera in a high frequency trajectory format, which ensures an accurate calibration of the physical properties of the rolling-shutter camera. Secondly, we incorporate a physical image formation model based into Gaussian Splatting, which effectively addresses the sensor characteristics, including the rolling-shutter effect of RGB cameras and the dynamic ranges measured by sensors. Our proposed formulation is applicable to the widely-used variants of Gaussian Splats representation. We conduct a comprehensive evaluation of our pipeline using the open-source Project Aria device under diverse indoor and outdoor lighting conditions, and further validate it on a Meta Quest3 device. Across all experiments, we observe a consistent visual enhancement of +1 dB in PSNR by incorporating VIBA, with an additional +1 dB achieved through our proposed image formation model. Our complete implementation, evaluation datasets, and recording profile are available at http://www.projectaria.com/photoreal-reconstruction/
Decentralization and Acceleration Enables Large-Scale Bundle Adjustment
May 15, 2023



Scaling to arbitrarily large bundle adjustment problems requires data and compute to be distributed across multiple devices. Centralized methods in prior works are only able to solve small or medium size problems due to overhead in computation and communication. In this paper, we present a fully decentralized method that alleviates computation and communication bottlenecks to solve arbitrarily large bundle adjustment problems. We achieve this by reformulating the reprojection error and deriving a novel surrogate function that decouples optimization variables from different devices. This function makes it possible to use majorization minimization techniques and reduces bundle adjustment to independent optimization subproblems that can be solved in parallel. We further apply Nesterov's acceleration and adaptive restart to improve convergence while maintaining its theoretical guarantees. Despite limited peer-to-peer communication, our method has provable convergence to first-order critical points under mild conditions. On extensive benchmarks with public datasets, our method converges much faster than decentralized baselines with similar memory usage and communication load. Compared to centralized baselines using a single device, our method, while being decentralized, yields more accurate solutions with significant speedups of up to 953.7x over Ceres and 174.6x over DeepLM. Code: https://github.com/facebookresearch/DABA.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022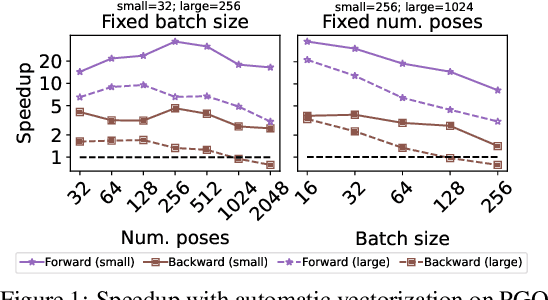
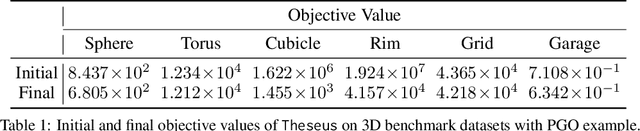
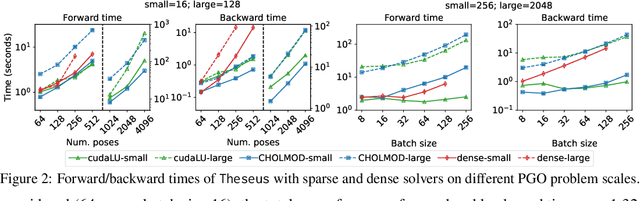
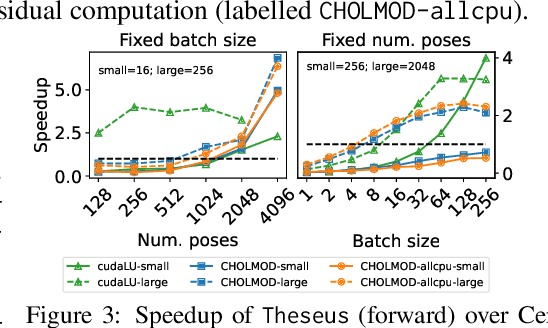
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai