 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter than Your Teacher: LLM Agents that learn from Privileged AI Feedback
Oct 07, 2024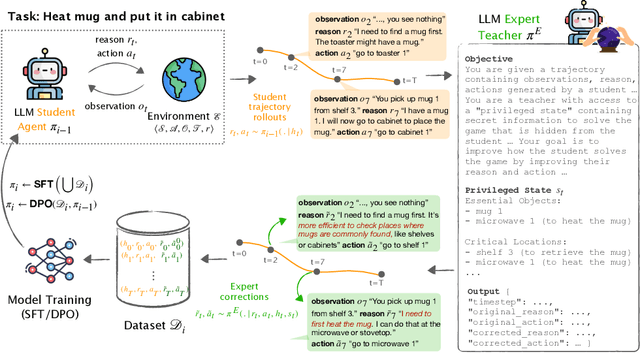


While large language models (LLMs) show impressive decision-making abilities, current methods lack a mechanism for automatic self-improvement from errors during task execution. We propose LEAP, an iterative fine-tuning framework that continually improves LLM agents using feedback from AI expert teachers. Our key insight is to equip the expert teachers with a privileged state -- information that is available during training but hidden at test time. This allows even weak experts to provide precise guidance, significantly improving the student agent's performance without access to privileged information at test time. We evaluate LEAP on diverse decision-making benchmarks, including text-based games (ALFWorld), web navigation (WebShop), and interactive coding (Intercode Bash). Our experiments show that LEAP (1) outperforms behavior cloning and ReAct baselines (2) enables weak student models (e.g., Llama3-8B) to exceed the performance of strong teacher models (GPT4-o), and (3) allows weak models to self-improve using privileged versions of themselves. We also provide a theoretical analysis showing that LEAP's success hinges on balancing privileged information with the student's realizability, which we empirically validate. Our code is available at https://leap-llm.github.io
Workflow-Guided Response Generation for Task-Oriented Dialogue
Nov 14, 2023


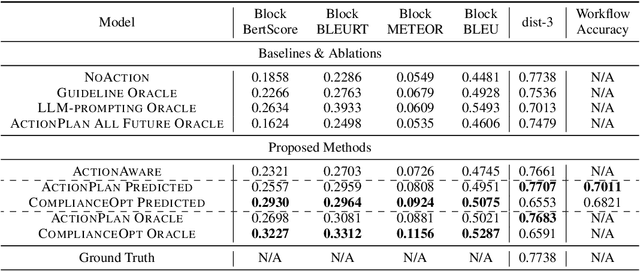
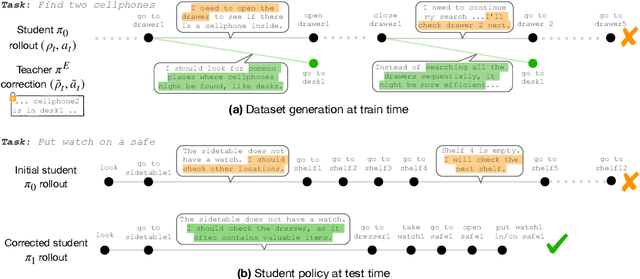
Task-oriented dialogue (TOD) systems aim to achieve specific goals through interactive dialogue. Such tasks usually involve following specific workflows, i.e. executing a sequence of actions in a particular order. While prior work has focused on supervised learning methods to condition on past actions, they do not explicitly optimize for compliance to a desired workflow. In this paper, we propose a novel framework based on reinforcement learning (RL) to generate dialogue responses that are aligned with a given workflow. Our framework consists of ComplianceScorer, a metric designed to evaluate how well a generated response executes the specified action, combined with an RL opimization process that utilizes an interactive sampling technique. We evaluate our approach on two TOD datasets, Action-Based Conversations Dataset (ABCD) (Chen et al., 2021a) and MultiWOZ 2.2 (Zang et al., 2020) on a range of automated and human evaluation metrics. Our findings indicate that our RL-based framework outperforms baselines and is effective at enerating responses that both comply with the intended workflows while being expressed in a natural and fluent manner.
HeaP: Hierarchical Policies for Web Actions using LLMs
Oct 05, 2023



Large language models (LLMs) have demonstrated remarkable capabilities in performing a range of instruction following tasks in few and zero-shot settings. However, teaching LLMs to perform tasks on the web presents fundamental challenges -- combinatorially large open-world tasks and variations across web interfaces. We tackle these challenges by leveraging LLMs to decompose web tasks into a collection of sub-tasks, each of which can be solved by a low-level, closed-loop policy. These policies constitute a shared grammar across tasks, i.e., new web tasks can be expressed as a composition of these policies. We propose a novel framework, Hierarchical Policies for Web Actions using LLMs (HeaP), that learns a set of hierarchical LLM prompts from demonstrations for planning high-level tasks and executing them via a sequence of low-level policies. We evaluate HeaP against a range of baselines on a suite of web tasks, including MiniWoB++, WebArena, a mock airline CRM, as well as live website interactions, and show that it is able to outperform prior works using orders of magnitude less data.
On the Effectiveness of Offline RL for Dialogue Response Generation
Jul 23, 2023



A common training technique for language models is teacher forcing (TF). TF attempts to match human language exactly, even though identical meanings can be expressed in different ways. This motivates use of sequence-level objectives for dialogue response generation. In this paper, we study the efficacy of various offline reinforcement learning (RL) methods to maximize such objectives. We present a comprehensive evaluation across multiple datasets, models, and metrics. Offline RL shows a clear performance improvement over teacher forcing while not inducing training instability or sacrificing practical training budgets.
Theseus: A Library for Differentiable Nonlinear Optimization
Jul 19, 2022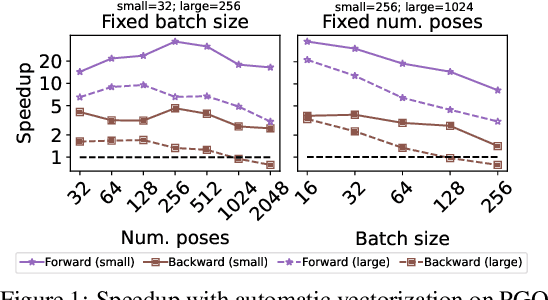
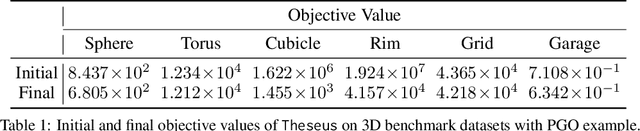
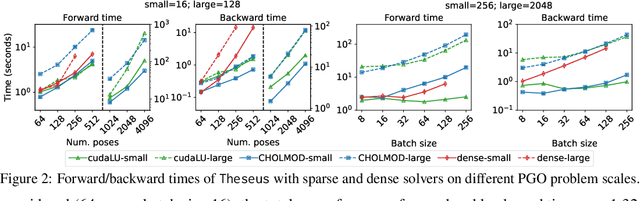
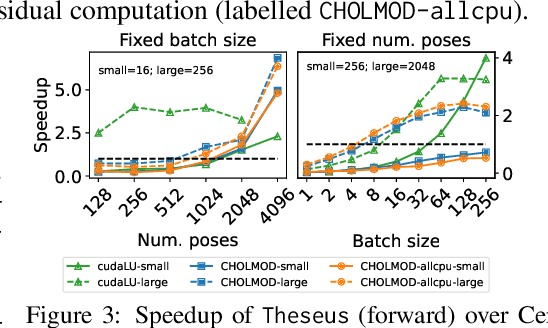
We present Theseus, an efficient application-agnostic open source library for differentiable nonlinear least squares (DNLS) optimization built on PyTorch, providing a common framework for end-to-end structured learning in robotics and vision. Existing DNLS implementations are application specific and do not always incorporate many ingredients important for efficiency. Theseus is application-agnostic, as we illustrate with several example applications that are built using the same underlying differentiable components, such as second-order optimizers, standard costs functions, and Lie groups. For efficiency, Theseus incorporates support for sparse solvers, automatic vectorization, batching, GPU acceleration, and gradient computation with implicit differentiation and direct loss minimization. We do extensive performance evaluation in a set of applications, demonstrating significant efficiency gains and better scalability when these features are incorporated. Project page: https://sites.google.com/view/theseus-ai
PatchGraph: In-hand tactile tracking with learned surface normals
Nov 15, 2021

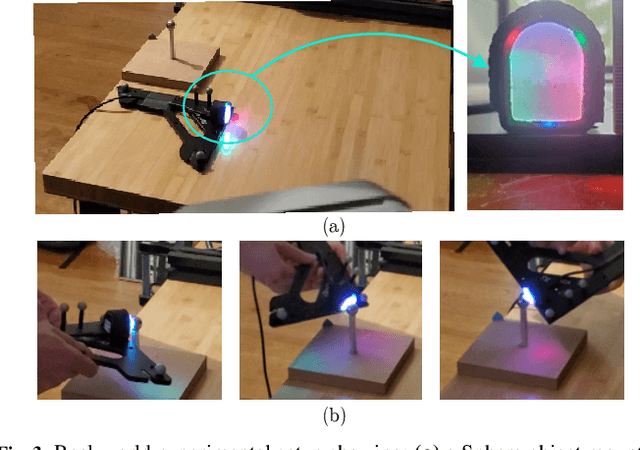
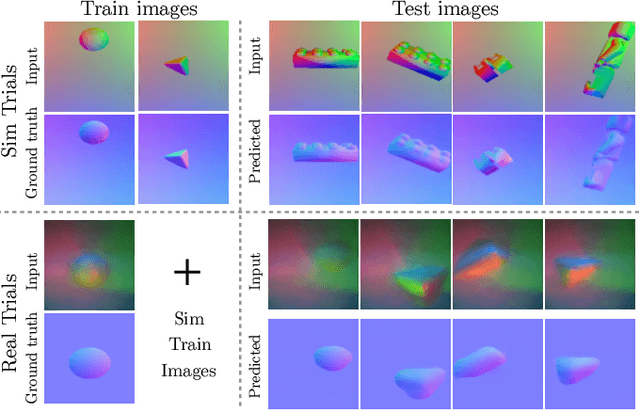
We address the problem of tracking 3D object poses from touch during in-hand manipulations. Specifically, we look at tracking small objects using vision-based tactile sensors that provide high-dimensional tactile image measurements at the point of contact. While prior work has relied on a-priori information about the object being localized, we remove this requirement. Our key insight is that an object is composed of several local surface patches, each informative enough to achieve reliable object tracking. Moreover, we can recover the geometry of this local patch online by extracting local surface normal information embedded in each tactile image. We propose a novel two-stage approach. First, we learn a mapping from tactile images to surface normals using an image translation network. Second, we use these surface normals within a factor graph to both reconstruct a local patch map and use it to infer 3D object poses. We demonstrate reliable object tracking for over 100 contact sequences across unique shapes with four objects in simulation and two objects in the real-world. Supplementary video: https://youtu.be/JwNTC9_nh8M
LEO: Learning Energy-based Models in Graph Optimization
Aug 04, 2021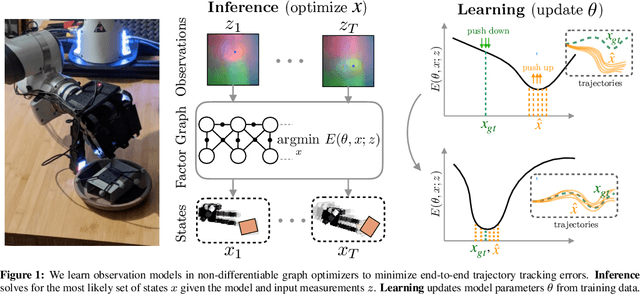
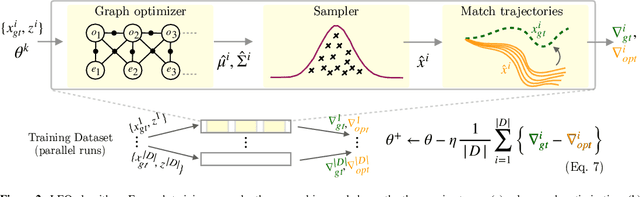
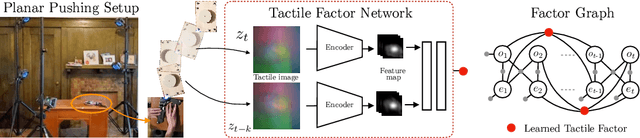
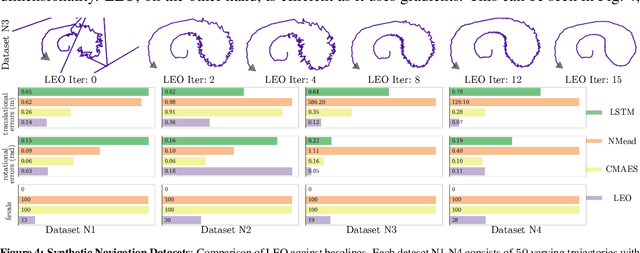
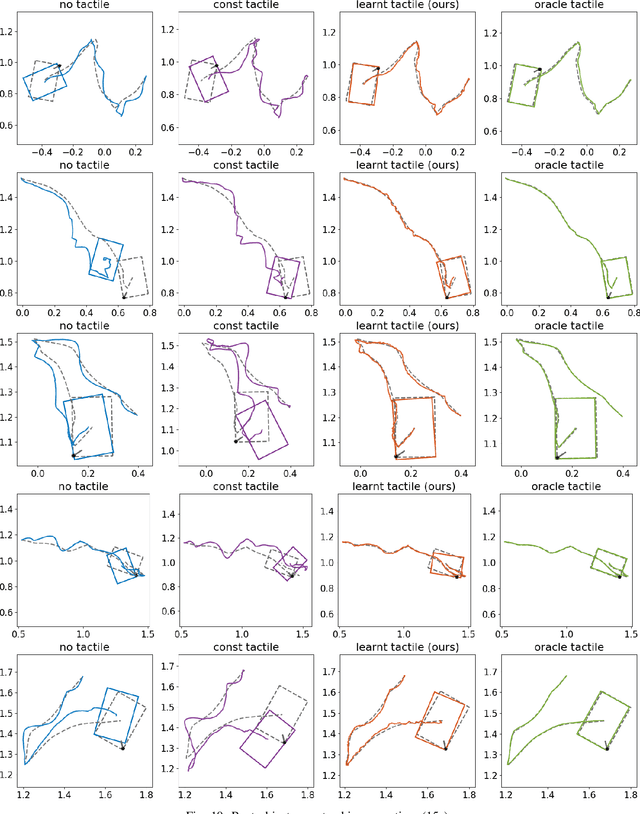
We address the problem of learning observation models end-to-end for estimation. Robots operating in partially observable environments must infer latent states from multiple sensory inputs using observation models that capture the joint distribution between latent states and observations. This inference problem can be formulated as an objective over a graph that optimizes for the most likely sequence of states using all previous measurements. Prior work uses observation models that are either known a-priori or trained on surrogate losses independent of the graph optimizer. In this paper, we propose a method to directly optimize end-to-end tracking performance by learning observation models with the graph optimizer in the loop. This direct approach may appear, however, to require the inference algorithm to be fully differentiable, which many state-of-the-art graph optimizers are not. Our key insight is to instead formulate the problem as that of energy-based learning. We propose a novel approach, LEO, for learning observation models end-to-end with non-differentiable graph optimizers. LEO alternates between sampling trajectories from the graph posterior and updating the model to match these samples to ground truth trajectories. We propose a way to generate such samples efficiently using incremental Gauss-Newton solvers. We compare LEO against baselines on datasets drawn from two distinct tasks: navigation and real-world planar pushing. We show that LEO is able to learn complex observation models with lower errors and fewer samples. Supplementary video: https://youtu.be/qWcH9CBXs5c
CMU-GPR Dataset: Ground Penetrating Radar Dataset for Robot Localization and Mapping
Jul 15, 2021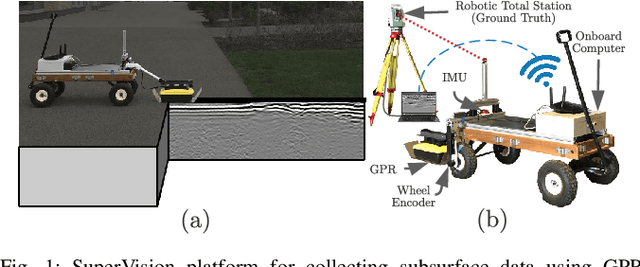
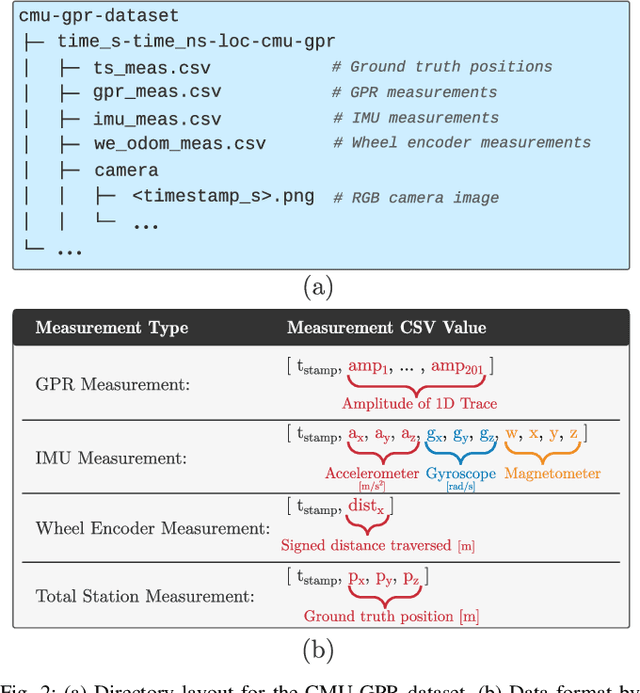
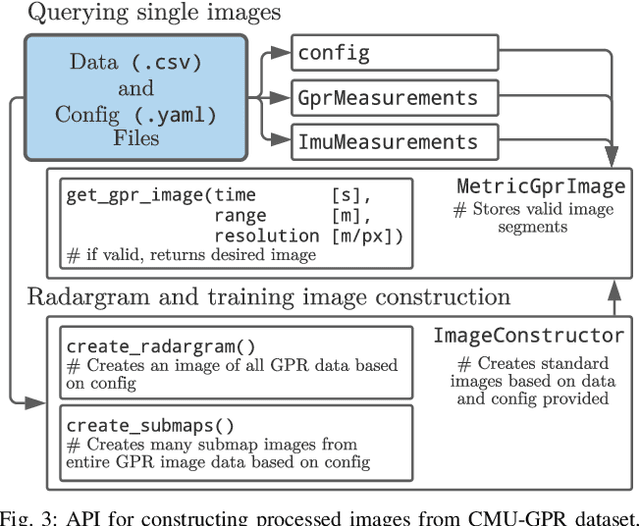
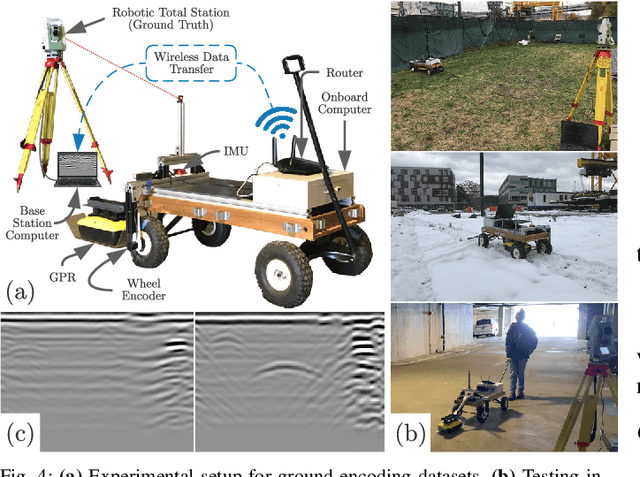
There has been exciting recent progress in using radar as a sensor for robot navigation due to its increased robustness to varying environmental conditions. However, within these different radar perception systems, ground penetrating radar (GPR) remains under-explored. By measuring structures beneath the ground, GPR can provide stable features that are less variant to ambient weather, scene, and lighting changes, making it a compelling choice for long-term spatio-temporal mapping. In this work, we present the CMU-GPR dataset--an open-source ground penetrating radar dataset for research in subsurface-aided perception for robot navigation. In total, the dataset contains 15 distinct trajectory sequences in 3 GPS-denied, indoor environments. Measurements from a GPR, wheel encoder, RGB camera, and inertial measurement unit were collected with ground truth positions from a robotic total station. In addition to the dataset, we also provide utility code to convert raw GPR data into processed images. This paper describes our recording platform, the data format, utility scripts, and proposed methods for using this data.
Ground Encoding: Learned Factor Graph-based Models for Localizing Ground Penetrating Radar
Mar 29, 2021
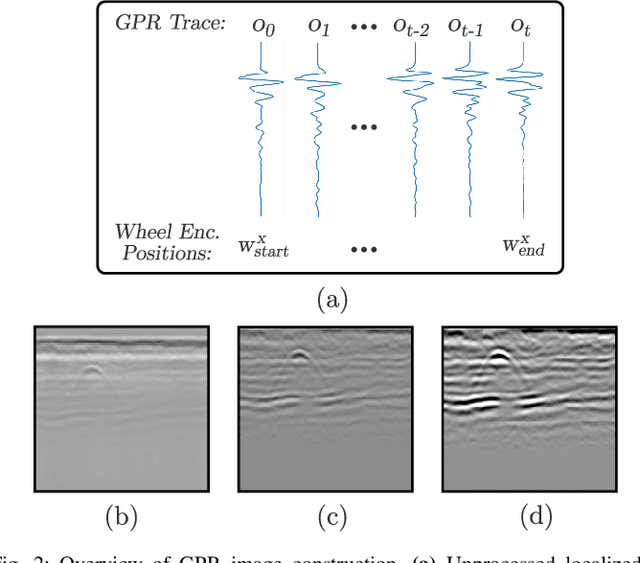

We address the problem of robot localization using ground penetrating radar (GPR) sensors. Current approaches for localization with GPR sensors require a priori maps of the system's environment as well as access to approximate global positioning (GPS) during operation. In this paper, we propose a novel, real-time GPR-based localization system for unknown and GPS-denied environments. We model the localization problem as an inference over a factor graph. Our approach combines 1D single-channel GPR measurements to form 2D image submaps. To use these GPR images in the graph, we need sensor models that can map noisy, high-dimensional image measurements into the state space. These are challenging to obtain a priori since image generation has a complex dependency on subsurface composition and radar physics, which itself varies with sensors and variations in subsurface electromagnetic properties. Our key idea is to instead learn relative sensor models directly from GPR data that map non-sequential GPR image pairs to relative robot motion. These models are incorporated as factors within the factor graph with relative motion predictions correcting for accumulated drift in the position estimates. We demonstrate our approach over datasets collected across multiple locations using a custom designed experimental rig. We show reliable, real-time localization using only GPR and odometry measurements for varying trajectories in three distinct GPS-denied environments. For our supplementary video, see https://youtu.be/HXXgdTJzqyw.
Learning Tactile Models for Factor Graph-based State Estimation
Dec 07, 2020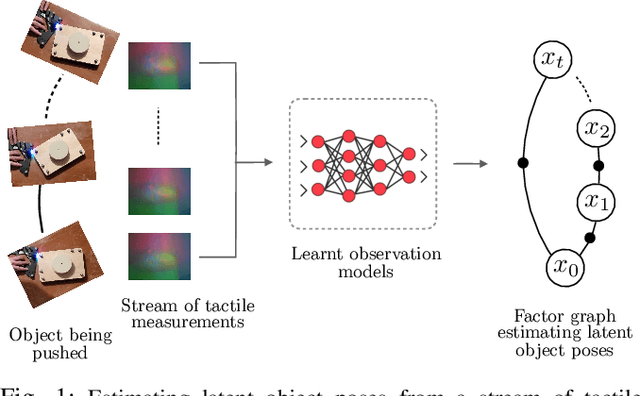
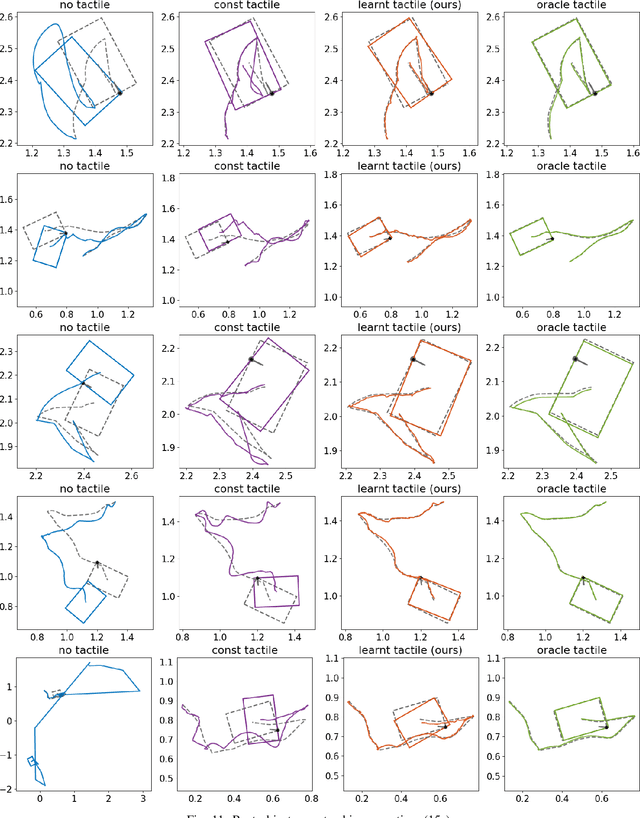
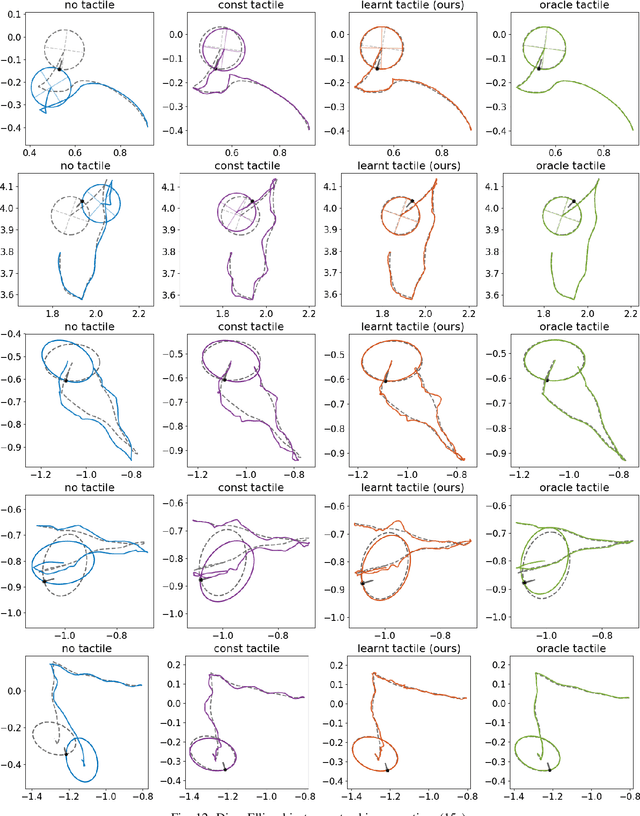
We address the problem of estimating object pose from touch during manipulation under occlusion. Vision-based tactile sensors provide rich, local measurements at the point of contact. A single such measurement, however, contains limited information and multiple measurements are needed to infer latent object state. We solve this inference problem using a factor graph. In order to incorporate tactile measurements in the graph, we need local observation models that can map high-dimensional tactile images onto a low-dimensional state space. Prior work has used low-dimensional force measurements or hand-designed functions to interpret tactile measurements. These methods, however, can be brittle and difficult to scale across objects and sensors. Our key insight is to directly learn tactile observation models that predict the relative pose of the sensor given a pair of tactile images. These relative poses can then be incorporated as factors within a factor graph. We propose a two-stage approach: first we learn local tactile observation models supervised with ground truth data, and then integrate these models along with physics and geometric factors within a factor graph optimizer. We demonstrate reliable object tracking using only tactile feedback for over 150 real-world planar pushing sequences with varying trajectories across three object shapes. Supplementary video: https://youtu.be/gp5fuIZTXMA