 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaP: Hierarchical Policies for Web Actions using LLMs
Oct 05, 2023



Large language models (LLMs) have demonstrated remarkable capabilities in performing a range of instruction following tasks in few and zero-shot settings. However, teaching LLMs to perform tasks on the web presents fundamental challenges -- combinatorially large open-world tasks and variations across web interfaces. We tackle these challenges by leveraging LLMs to decompose web tasks into a collection of sub-tasks, each of which can be solved by a low-level, closed-loop policy. These policies constitute a shared grammar across tasks, i.e., new web tasks can be expressed as a composition of these policies. We propose a novel framework, Hierarchical Policies for Web Actions using LLMs (HeaP), that learns a set of hierarchical LLM prompts from demonstrations for planning high-level tasks and executing them via a sequence of low-level policies. We evaluate HeaP against a range of baselines on a suite of web tasks, including MiniWoB++, WebArena, a mock airline CRM, as well as live website interactions, and show that it is able to outperform prior works using orders of magnitude less data.
Learning to Win by Reading Manuals in a Monte-Carlo Framework
Jan 18, 2014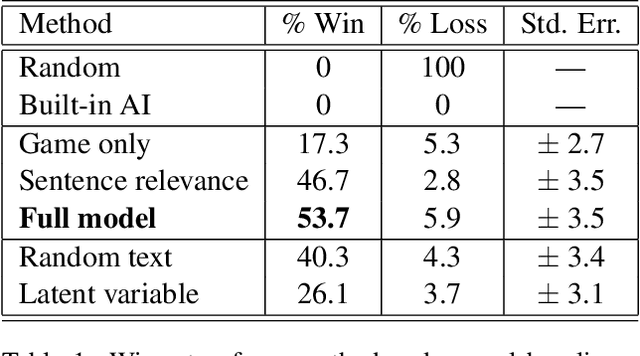
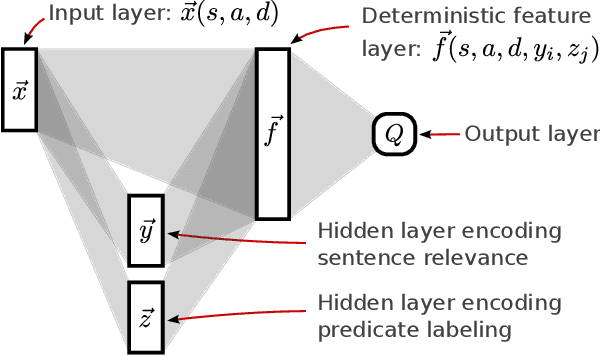
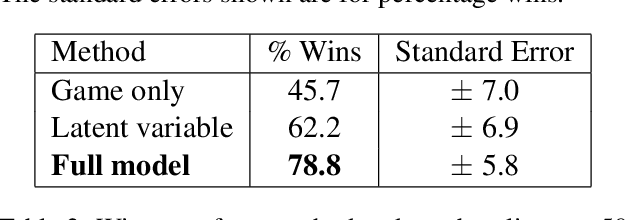

Domain knowledge is crucial for effective performance in autonomous control systems. Typically, human effort is required to encode this knowledge into a control algorithm. In this paper, we present an approach to language grounding which automatically interprets text in the context of a complex control application, such as a game, and uses domain knowledge extracted from the text to improve control performance. Both text analysis and control strategies are learned jointly using only a feedback signal inherent to the application. To effectively leverage textual information, our method automatically extracts the text segment most relevant to the current game state, and labels it with a task-centric predicate structure. This labeled text is then used to bias an action selection policy for the game, guiding it towards promising regions of the action space. We encode our model for text analysis and game playing in a multi-layer neural network, representing linguistic decisions via latent variables in the hidden layers, and game action quality via the output layer. Operating within the Monte-Carlo Search framework, we estimate model parameters using feedback from simulated games. We apply our approach to the complex strategy game Civilization II using the official game manual as the text guide. Our results show that a linguistically-informed game-playing agent significantly outperforms its language-unaware counterpart, yielding a 34% absolute improvement and winning over 65% of games when playing against the built-in AI of Civilization.
Content Modeling Using Latent Permutations
Jan 15, 2014
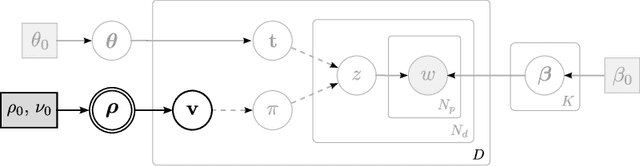
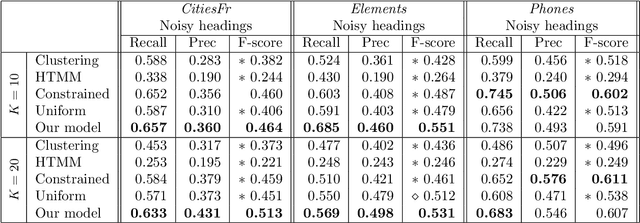
We present a novel Bayesian topic model for learning discourse-level document structure. Our model leverages insights from discourse theory to constrain latent topic assignments in a way that reflects the underlying organization of document topics. We propose a global model in which both topic selection and ordering are biased to be similar across a collection of related documents. We show that this space of orderings can be effectively represented using a distribution over permutations called the Generalized Mallows Model. We apply our method to three complementary discourse-level tasks: cross-document alignment, document segmentation, and information ordering. Our experiments show that incorporating our permutation-based model in these applications yields substantial improvements in performance over previously proposed methods.
Learning Document-Level Semantic Properties from Free-Text Annotations
Jan 15, 2014



This paper presents a new method for inferring the semantic properties of documents by leveraging free-text keyphrase annotations. Such annotations are becoming increasingly abundant due to the recent dramatic growth in semi-structured, user-generated online content. One especially relevant domain is product reviews, which are often annotated by their authors with pros/cons keyphrases such as a real bargain or good value. These annotations are representative of the underlying semantic properties; however, unlike expert annotations, they are noisy: lay authors may use different labels to denote the same property, and some labels may be missing. To learn using such noisy annotations, we find a hidden paraphrase structure which clusters the keyphrases. The paraphrase structure is linked with a latent topic model of the review texts, enabling the system to predict the properties of unannotated documents and to effectively aggregate the semantic properties of multiple reviews. Our approach is implemented as a hierarchical Bayesian model with joint inference. We find that joint inference increases the robustness of the keyphrase clustering and encourages the latent topics to correlate with semantically meaningful properties. Multiple evaluations demonstrate that our model substantially outperforms alternative approaches for summarizing single and multiple documents into a set of semantically salient keyphrases.