 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Modeling Using Latent Permutations
Jan 15, 2014
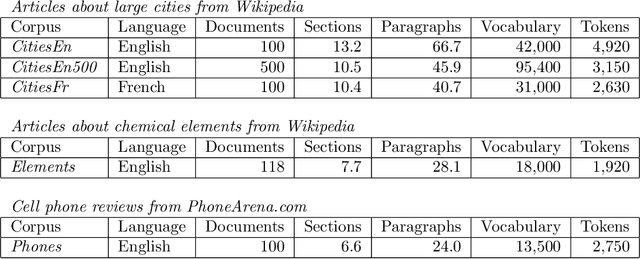
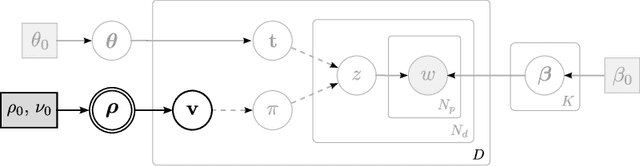
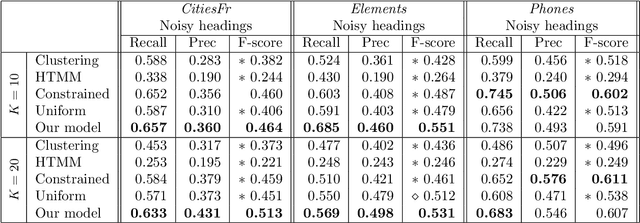
We present a novel Bayesian topic model for learning discourse-level document structure. Our model leverages insights from discourse theory to constrain latent topic assignments in a way that reflects the underlying organization of document topics. We propose a global model in which both topic selection and ordering are biased to be similar across a collection of related documents. We show that this space of orderings can be effectively represented using a distribution over permutations called the Generalized Mallows Model. We apply our method to three complementary discourse-level tasks: cross-document alignment, document segmentation, and information ordering. Our experiments show that incorporating our permutation-based model in these applications yields substantial improvements in performance over previously proposed methods.
Learning Document-Level Semantic Properties from Free-Text Annotations
Jan 15, 2014



This paper presents a new method for inferring the semantic properties of documents by leveraging free-text keyphrase annotations. Such annotations are becoming increasingly abundant due to the recent dramatic growth in semi-structured, user-generated online content. One especially relevant domain is product reviews, which are often annotated by their authors with pros/cons keyphrases such as a real bargain or good value. These annotations are representative of the underlying semantic properties; however, unlike expert annotations, they are noisy: lay authors may use different labels to denote the same property, and some labels may be missing. To learn using such noisy annotations, we find a hidden paraphrase structure which clusters the keyphrases. The paraphrase structure is linked with a latent topic model of the review texts, enabling the system to predict the properties of unannotated documents and to effectively aggregate the semantic properties of multiple reviews. Our approach is implemented as a hierarchical Bayesian model with joint inference. We find that joint inference increases the robustness of the keyphrase clustering and encourages the latent topics to correlate with semantically meaningful properties. Multiple evaluations demonstrate that our model substantially outperforms alternative approaches for summarizing single and multiple documents into a set of semantically salient keyphrases.
Dirichlet Process Mixtures of Generalized Mallows Models
Mar 15, 2012



We present a Dirichlet process mixture model over discrete incomplete rankings and study two Gibbs sampling inference techniques for estimating posterior clusterings. The first approach uses a slice sampling subcomponent for estimating cluster parameters. The second approach marginalizes out several cluster parameters by taking advantage of approximations to the conditional posteriors. We empirically demonstrate (1) the effectiveness of this approximation for improving convergence, (2) the benefits of the Dirichlet process model over alternative clustering techniques for ranked data, and (3) the applicability of the approach to exploring large realworld ranking datasets.