 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Modeling Using Latent Permutations
Jan 15, 2014
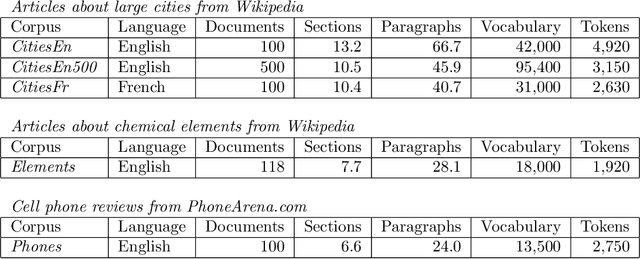
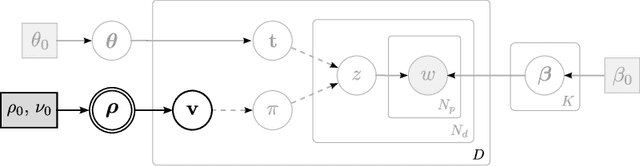
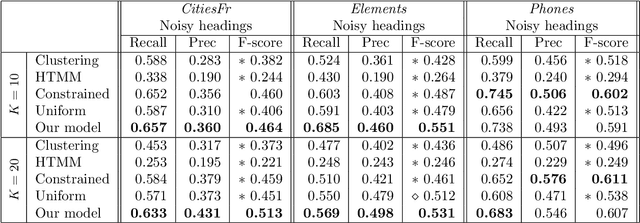
We present a novel Bayesian topic model for learning discourse-level document structure. Our model leverages insights from discourse theory to constrain latent topic assignments in a way that reflects the underlying organization of document topics. We propose a global model in which both topic selection and ordering are biased to be similar across a collection of related documents. We show that this space of orderings can be effectively represented using a distribution over permutations called the Generalized Mallows Model. We apply our method to three complementary discourse-level tasks: cross-document alignment, document segmentation, and information ordering. Our experiments show that incorporating our permutation-based model in these applications yields substantial improvements in performance over previously proposed methods.
Budget-Optimal Task Allocation for Reliable Crowdsourcing Systems
Mar 26, 2013
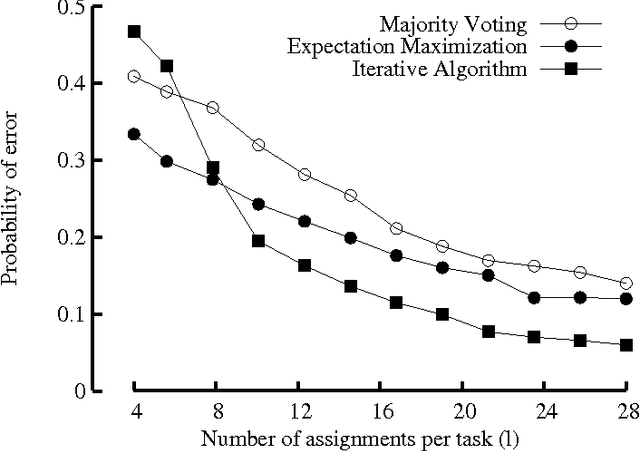
Crowdsourcing systems, in which numerous tasks are electronically distributed to numerous "information piece-workers", have emerged as an effective paradigm for human-powered solving of large scale problems in domains such as image classification, data entry, optical character recognition, recommendation, and proofreading. Because these low-paid workers can be unreliable, nearly all such systems must devise schemes to increase confidence in their answers, typically by assigning each task multiple times and combining the answers in an appropriate manner, e.g. majority voting. In this paper, we consider a general model of such crowdsourcing tasks and pose the problem of minimizing the total price (i.e., number of task assignments) that must be paid to achieve a target overall reliability. We give a new algorithm for deciding which tasks to assign to which workers and for inferring correct answers from the workers' answers. We show that our algorithm, inspired by belief propagation and low-rank matrix approximation, significantly outperforms majority voting and, in fact, is optimal through comparison to an oracle that knows the reliability of every worker. Further, we compare our approach with a more general class of algorithms which can dynamically assign tasks. By adaptively deciding which questions to ask to the next arriving worker, one might hope to reduce uncertainty more efficiently. We show that, perhaps surprisingly, the minimum price necessary to achieve a target reliability scales in the same manner under both adaptive and non-adaptive scenarios. Hence, our non-adaptive approach is order-optimal under both scenarios. This strongly relies on the fact that workers are fleeting and can not be exploited. Therefore, architecturally, our results suggest that building a reliable worker-reputation system is essential to fully harnessing the potential of adaptive designs.