 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Survival Control: Extending Synthetic Controls for "When-If" Decision
Nov 18, 2025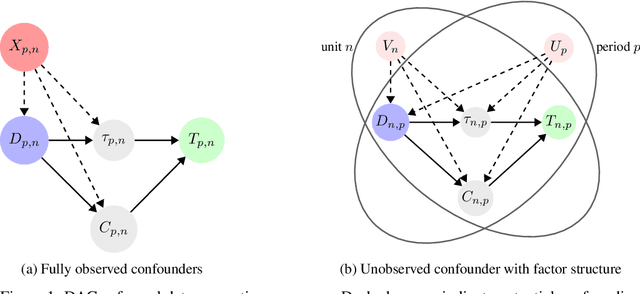
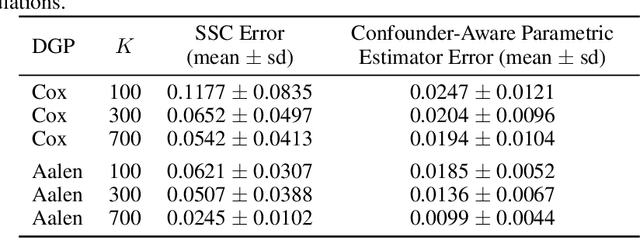
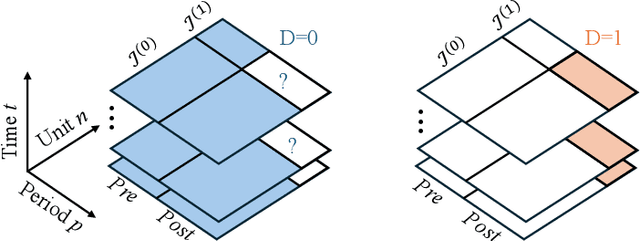
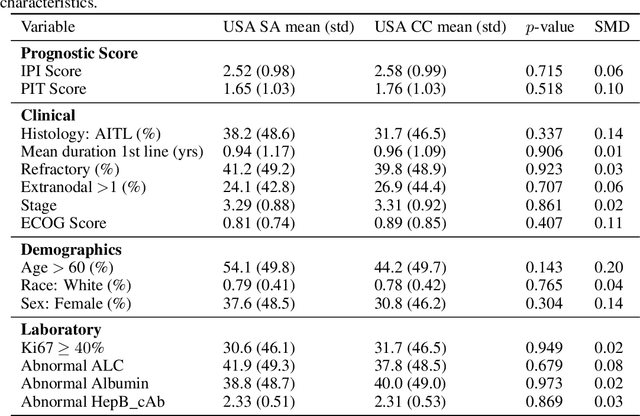
Estimating causal effects on time-to-event outcomes from observational data is particularly challenging due to censoring, limited sample sizes, and non-random treatment assignment. The need for answering such "when-if" questions--how the timing of an event would change under a specified intervention--commonly arises in real-world settings with heterogeneous treatment adoption and confounding. To address these challenges, we propose Synthetic Survival Control (SSC) to estimate counterfactual hazard trajectories in a panel data setting where multiple units experience potentially different treatments over multiple periods. In such a setting, SSC estimates the counterfactual hazard trajectory for a unit of interest as a weighted combination of the observed trajectories from other units. To provide formal justification, we introduce a panel framework with a low-rank structure for causal survival analysis. Indeed, such a structure naturally arises under classical parametric survival models. Within this framework, for the causal estimand of interest, we establish identification and finite sample guarantees for SSC. We validate our approach using a multi-country clinical dataset of cancer treatment outcomes, where the staggered introduction of new therapies creates a quasi-experimental setting. Empirically, we find that access to novel treatments is associated with improved survival, as reflected by lower post-intervention hazard trajectories relative to their synthetic counterparts. Given the broad relevance of survival analysis across medicine, economics, and public policy, our framework offers a general and interpretable tool for counterfactual survival inference using observational data.
A Causal Inference Framework for Data Rich Environments
Apr 02, 2025We propose a formal model for counterfactual estimation with unobserved confounding in "data-rich" settings, i.e., where there are a large number of units and a large number of measurements per unit. Our model provides a bridge between the structural causal model view of causal inference common in the graphical models literature with that of the latent factor model view common in the potential outcomes literature. We show how classic models for potential outcomes and treatment assignments fit within our framework. We provide an identification argument for the average treatment effect, the average treatment effect on the treated, and the average treatment effect on the untreated. For any estimator that has a fast enough estimation error rate for a certain nuisance parameter, we establish it is consistent for these various causal parameters. We then show principal component regression is one such estimator that leads to consistent estimation, and we analyze the minimal smoothness required of the potential outcomes function for consistency.
Explaining the Success of Nearest Neighbor Methods in Prediction
Feb 21, 2025Many modern methods for prediction leverage nearest neighbor search to find past training examples most similar to a test example, an idea that dates back in text to at least the 11th century and has stood the test of time. This monograph aims to explain the success of these methods, both in theory, for which we cover foundational nonasymptotic statistical guarantees on nearest-neighbor-based regression and classification, and in practice, for which we gather prominent methods for approximate nearest neighbor search that have been essential to scaling prediction systems reliant on nearest neighbor analysis to handle massive datasets. Furthermore, we discuss connections to learning distances for use with nearest neighbor methods, including how random decision trees and ensemble methods learn nearest neighbor structure, as well as recent developments in crowdsourcing and graphons. In terms of theory, our focus is on nonasymptotic statistical guarantees, which we state in the form of how many training data and what algorithm parameters ensure that a nearest neighbor prediction method achieves a user-specified error tolerance. We begin with the most general of such results for nearest neighbor and related kernel regression and classification in general metric spaces. In such settings in which we assume very little structure, what enables successful prediction is smoothness in the function being estimated for regression, and a low probability of landing near the decision boundary for classification. In practice, these conditions could be difficult to verify for a real dataset. We then cover recent guarantees on nearest neighbor prediction in the three case studies of time series forecasting, recommending products to people over time, and delineating human organs in medical images by looking at image patches. In these case studies, clustering structure enables successful prediction.
Integrating Expert Judgment and Algorithmic Decision Making: An Indistinguishability Framework
Oct 11, 2024
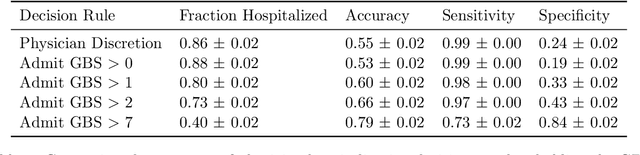


We introduce a novel framework for human-AI collaboration in prediction and decision tasks. Our approach leverages human judgment to distinguish inputs which are algorithmically indistinguishable, or "look the same" to any feasible predictive algorithm. We argue that this framing clarifies the problem of human-AI collaboration in prediction and decision tasks, as experts often form judgments by drawing on information which is not encoded in an algorithm's training data. Algorithmic indistinguishability yields a natural test for assessing whether experts incorporate this kind of "side information", and further provides a simple but principled method for selectively incorporating human feedback into algorithmic predictions. We show that this method provably improves the performance of any feasible algorithmic predictor and precisely quantify this improvement. We demonstrate the utility of our framework in a case study of emergency room triage decisions, where we find that although algorithmic risk scores are highly competitive with physicians, there is strong evidence that physician judgments provide signal which could not be replicated by any predictive algorithm. This insight yields a range of natural decision rules which leverage the complementary strengths of human experts and predictive algorithms.
Exploiting Exogenous Structure for Sample-Efficient Reinforcement Learning
Sep 22, 2024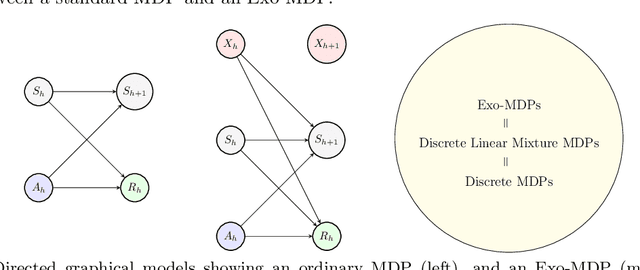
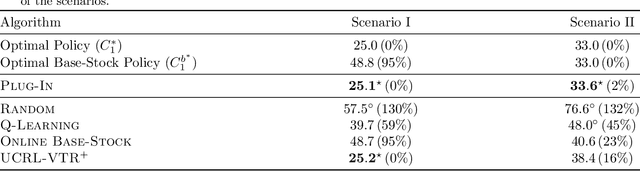
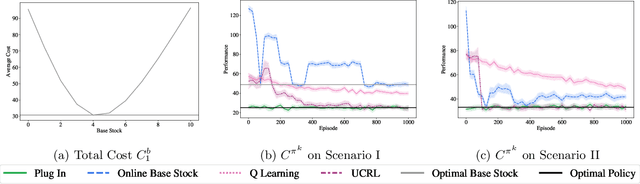
We study a class of structured Markov Decision Processes (MDPs) known as Exo-MDPs, characterized by a partition of the state space into two components. The exogenous states evolve stochastically in a manner not affected by the agent's actions, whereas the endogenous states are affected by the actions, and evolve in a deterministic and known way conditional on the exogenous states. Exo-MDPs are a natural model for various applications including inventory control, finance, power systems, ride sharing, among others. Despite seeming restrictive, this work establishes that any discrete MDP can be represented as an Exo-MDP. Further, Exo-MDPs induce a natural representation of the transition and reward dynamics as linear functions of the exogenous state distribution. This linear representation leads to near-optimal algorithms with regret guarantees scaling only with the (effective) size of the exogenous state space $d$, independent of the sizes of the endogenous state and action spaces. Specifically, when the exogenous state is fully observed, a simple plug-in approach achieves a regret upper bound of $O(H^{3/2}\sqrt{dK})$, where $H$ denotes the horizon and $K$ denotes the total number of episodes. When the exogenous state is unobserved, the linear representation leads to a regret upper bound of $O(H^{3/2}d\sqrt{K})$. We also establish a nearly matching regret lower bound of $\Omega(Hd\sqrt{K})$ for the no observation regime. We complement our theoretical findings with an experimental study on inventory control problems.
A Causal Framework to Evaluate Racial Bias in Law Enforcement Systems
Feb 22, 2024We are interested in developing a data-driven method to evaluate race-induced biases in law enforcement systems. While the recent works have addressed this question in the context of police-civilian interactions using police stop data, they have two key limitations. First, bias can only be properly quantified if true criminality is accounted for in addition to race, but it is absent in prior works. Second, law enforcement systems are multi-stage and hence it is important to isolate the true source of bias within the "causal chain of interactions" rather than simply focusing on the end outcome; this can help guide reforms. In this work, we address these challenges by presenting a multi-stage causal framework incorporating criminality. We provide a theoretical characterization and an associated data-driven method to evaluate (a) the presence of any form of racial bias, and (b) if so, the primary source of such a bias in terms of race and criminality. Our framework identifies three canonical scenarios with distinct characteristics: in settings like (1) airport security, the primary source of observed bias against a race is likely to be bias in law enforcement against innocents of that race; (2) AI-empowered policing, the primary source of observed bias against a race is likely to be bias in law enforcement against criminals of that race; and (3) police-civilian interaction, the primary source of observed bias against a race could be bias in law enforcement against that race or bias from the general public in reporting against the other race. Through an extensive empirical study using police-civilian interaction data and 911 call data, we find an instance of such a counter-intuitive phenomenon: in New Orleans, the observed bias is against the majority race and the likely reason for it is the over-reporting (via 911 calls) of incidents involving the minority race by the general public.
Distinguishing the Indistinguishable: Human Expertise in Algorithmic Prediction
Feb 01, 2024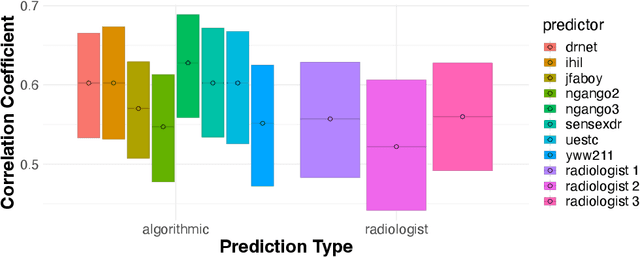
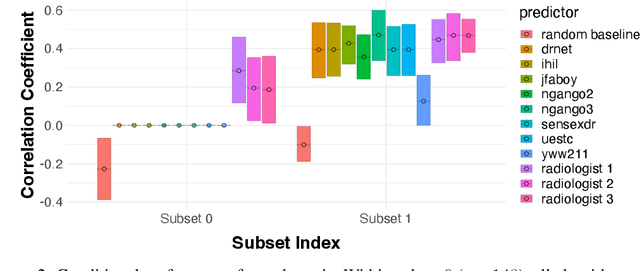
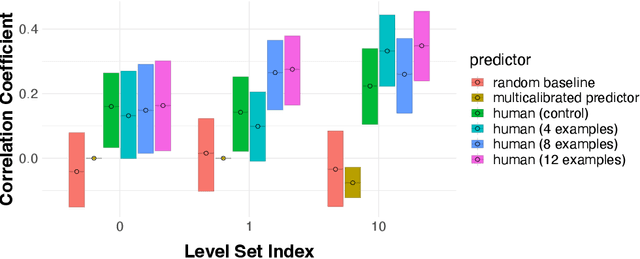

We introduce a novel framework for incorporating human expertise into algorithmic predictions. Our approach focuses on the use of human judgment to distinguish inputs which `look the same' to any feasible predictive algorithm. We argue that this framing clarifies the problem of human/AI collaboration in prediction tasks, as experts often have access to information -- particularly subjective information -- which is not encoded in the algorithm's training data. We use this insight to develop a set of principled algorithms for selectively incorporating human feedback only when it improves the performance of any feasible predictor. We find empirically that although algorithms often outperform their human counterparts on average, human judgment can significantly improve algorithmic predictions on specific instances (which can be identified ex-ante). In an X-ray classification task, we find that this subset constitutes nearly 30% of the patient population. Our approach provides a natural way of uncovering this heterogeneity and thus enabling effective human-AI collaboration.
Predicting Ground Reaction Force from Inertial Sensors
Nov 04, 2023The study of ground reaction forces (GRF) is used to characterize the mechanical loading experienced by individuals in movements such as running, which is clinically applicable to identify athletes at risk for stress-related injuries. Our aim in this paper is to determine if data collected with inertial measurement units (IMUs), that can be worn by athletes during outdoor runs, can be used to predict GRF with sufficient accuracy to allow the analysis of its derived biomechanical variables (e.g., contact time and loading rate). In this paper, we consider lightweight approaches in contrast to state-of-the-art prediction using LSTM neural networks. Specifically, we compare use of LSTMs to k-Nearest Neighbors (KNN) regression as well as propose a novel solution, SVD Embedding Regression (SER), using linear regression between singular value decomposition embeddings of IMUs data (input) and GRF data (output). We evaluate the accuracy of these techniques when using training data collected from different athletes, from the same athlete, or both, and we explore the use of acceleration and angular velocity data from sensors at different locations (sacrum and shanks). Our results illustrate that simple machine learning methods such as SER and KNN can be similarly accurate or more accurate than LSTM neural networks, with much faster training times and hyperparameter optimization; in particular, SER and KNN are more accurate when personal training data are available, and KNN comes with benefit of providing provenance of prediction. Notably, the use of personal data reduces prediction errors of all methods for most biomechanical variables.
On Computationally Efficient Learning of Exponential Family Distributions
Sep 12, 2023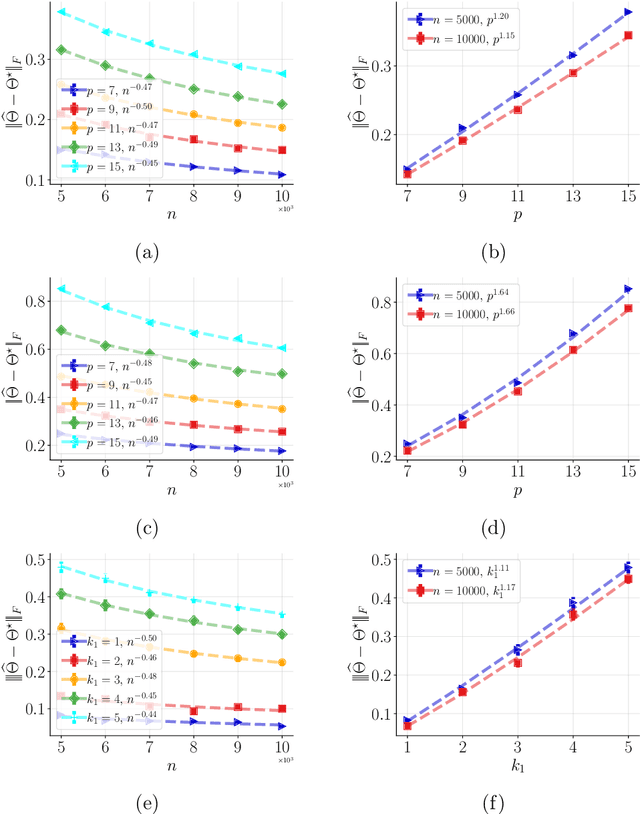
We consider the classical problem of learning, with arbitrary accuracy, the natural parameters of a $k$-parameter truncated \textit{minimal} exponential family from i.i.d. samples in a computationally and statistically efficient manner. We focus on the setting where the support as well as the natural parameters are appropriately bounded. While the traditional maximum likelihood estimator for this class of exponential family is consistent, asymptotically normal, and asymptotically efficient, evaluating it is computationally hard. In this work, we propose a novel loss function and a computationally efficient estimator that is consistent as well as asymptotically normal under mild conditions. We show that, at the population level, our method can be viewed as the maximum likelihood estimation of a re-parameterized distribution belonging to the same class of exponential family. Further, we show that our estimator can be interpreted as a solution to minimizing a particular Bregman score as well as an instance of minimizing the \textit{surrogate} likelihood. We also provide finite sample guarantees to achieve an error (in $\ell_2$-norm) of $\alpha$ in the parameter estimation with sample complexity $O({\sf poly}(k)/\alpha^2)$. Our method achives the order-optimal sample complexity of $O({\sf log}(k)/\alpha^2)$ when tailored for node-wise-sparse Markov random fields. Finally, we demonstrate the performance of our estimator via numerical experiments.
Exploiting Observation Bias to Improve Matrix Completion
Jun 07, 2023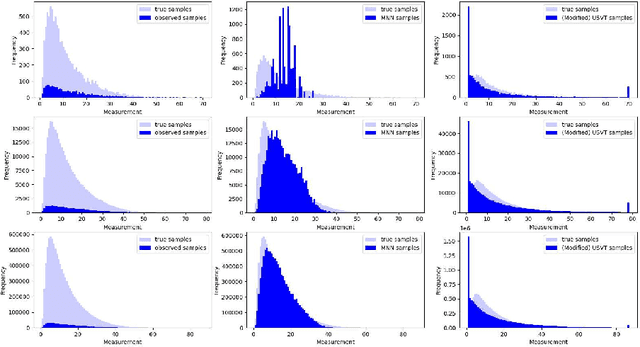

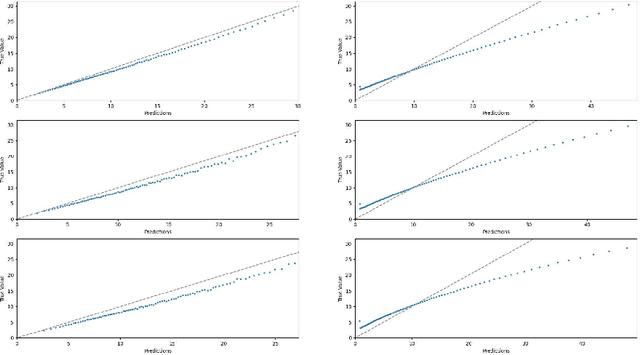

We consider a variant of matrix completion where entries are revealed in a biased manner, adopting a model akin to that introduced by Ma and Chen. Instead of treating this observation bias as a disadvantage, as is typically the case, our goal is to exploit the shared information between the bias and the outcome of interest to improve predictions. Towards this, we propose a simple two-stage algorithm: (i) interpreting the observation pattern as a fully observed noisy matrix, we apply traditional matrix completion methods to the observation pattern to estimate the distances between the latent factors; (ii) we apply supervised learning on the recovered features to impute missing observations. We establish finite-sample error rates that are competitive with the corresponding supervised learning parametric rates, suggesting that our learning performance is comparable to having access to the unobserved covariates. Empirical evaluation using a real-world dataset reflects similar performance gains, with our algorithm's estimates having 30x smaller mean squared error compared to traditional matrix completion methods.