 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Expert Judgment and Algorithmic Decision Making: An Indistinguishability Framework
Oct 11, 2024
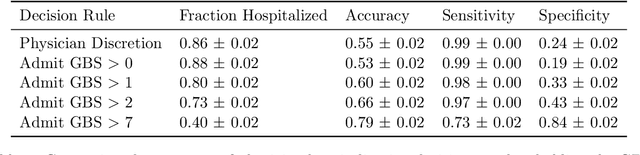


We introduce a novel framework for human-AI collaboration in prediction and decision tasks. Our approach leverages human judgment to distinguish inputs which are algorithmically indistinguishable, or "look the same" to any feasible predictive algorithm. We argue that this framing clarifies the problem of human-AI collaboration in prediction and decision tasks, as experts often form judgments by drawing on information which is not encoded in an algorithm's training data. Algorithmic indistinguishability yields a natural test for assessing whether experts incorporate this kind of "side information", and further provides a simple but principled method for selectively incorporating human feedback into algorithmic predictions. We show that this method provably improves the performance of any feasible algorithmic predictor and precisely quantify this improvement. We demonstrate the utility of our framework in a case study of emergency room triage decisions, where we find that although algorithmic risk scores are highly competitive with physicians, there is strong evidence that physician judgments provide signal which could not be replicated by any predictive algorithm. This insight yields a range of natural decision rules which leverage the complementary strengths of human experts and predictive algorithms.
Auditing for Human Expertise
Jun 02, 2023High-stakes prediction tasks (e.g., patient diagnosis) are often handled by trained human experts. A common source of concern about automation in these settings is that experts may exercise intuition that is difficult to model and/or have access to information (e.g., conversations with a patient) that is simply unavailable to a would-be algorithm. This raises a natural question whether human experts add value which could not be captured by an algorithmic predictor. We develop a statistical framework under which we can pose this question as a natural hypothesis test. Indeed, as our framework highlights, detecting human expertise is more subtle than simply comparing the accuracy of expert predictions to those made by a particular learning algorithm. Instead, we propose a simple procedure which tests whether expert predictions are statistically independent from the outcomes of interest after conditioning on the available inputs (`features'). A rejection of our test thus suggests that human experts may add value to any algorithm trained on the available data, and has direct implications for whether human-AI `complementarity' is achievable in a given prediction task. We highlight the utility of our procedure using admissions data collected from the emergency department of a large academic hospital system, where we show that physicians' admit/discharge decisions for patients with acute gastrointestinal bleeding (AGIB) appear to be incorporating information not captured in a standard algorithmic screening tool. This is despite the fact that the screening tool is arguably more accurate than physicians' discretionary decisions, highlighting that -- even absent normative concerns about accountability or interpretability -- accuracy is insufficient to justify algorithmic automation.