 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIA Forecaster: Technical Report
Nov 10, 2025This technical report describes the AIA Forecaster, a Large Language Model (LLM)-based system for judgmental forecasting using unstructured data. The AIA Forecaster approach combines three core elements: agentic search over high-quality news sources, a supervisor agent that reconciles disparate forecasts for the same event, and a set of statistical calibration techniques to counter behavioral biases in large language models. On the ForecastBench benchmark (Karger et al., 2024), the AIA Forecaster achieves performance equal to human superforecasters, surpassing prior LLM baselines. In addition to reporting on ForecastBench, we also introduce a more challenging forecasting benchmark sourced from liquid prediction markets. While the AIA Forecaster underperforms market consensus on this benchmark, an ensemble combining AIA Forecaster with market consensus outperforms consensus alone, demonstrating that our forecaster provides additive information. Our work establishes a new state of the art in AI forecasting and provides practical, transferable recommendations for future research. To the best of our knowledge, this is the first work that verifiably achieves expert-level forecasting at scale.
Integrating Expert Judgment and Algorithmic Decision Making: An Indistinguishability Framework
Oct 11, 2024
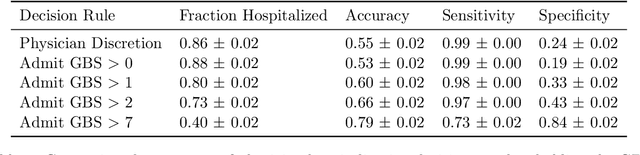


We introduce a novel framework for human-AI collaboration in prediction and decision tasks. Our approach leverages human judgment to distinguish inputs which are algorithmically indistinguishable, or "look the same" to any feasible predictive algorithm. We argue that this framing clarifies the problem of human-AI collaboration in prediction and decision tasks, as experts often form judgments by drawing on information which is not encoded in an algorithm's training data. Algorithmic indistinguishability yields a natural test for assessing whether experts incorporate this kind of "side information", and further provides a simple but principled method for selectively incorporating human feedback into algorithmic predictions. We show that this method provably improves the performance of any feasible algorithmic predictor and precisely quantify this improvement. We demonstrate the utility of our framework in a case study of emergency room triage decisions, where we find that although algorithmic risk scores are highly competitive with physicians, there is strong evidence that physician judgments provide signal which could not be replicated by any predictive algorithm. This insight yields a range of natural decision rules which leverage the complementary strengths of human experts and predictive algorithms.
Unstable Unlearning: The Hidden Risk of Concept Resurgence in Diffusion Models
Oct 10, 2024
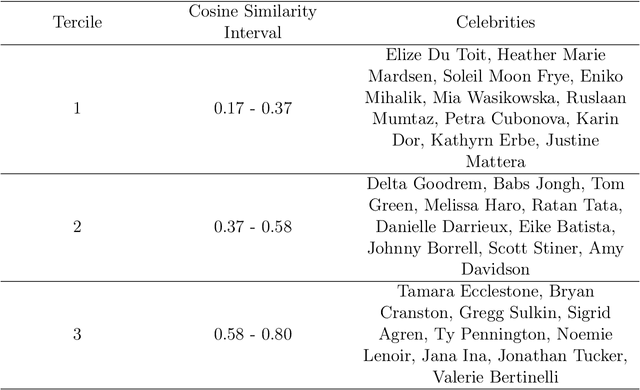
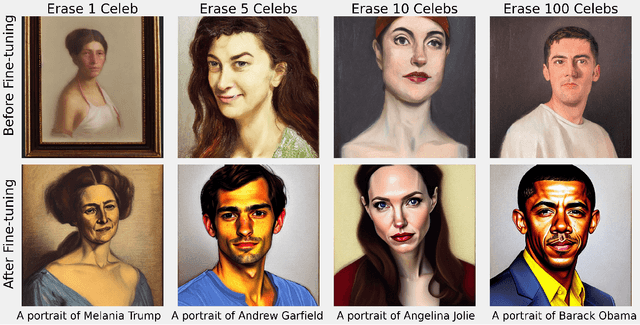
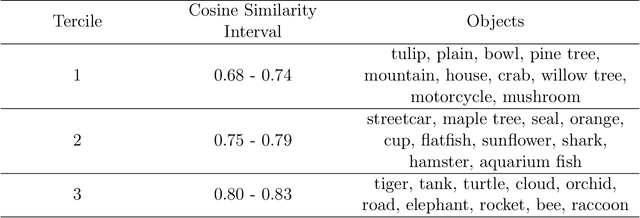
Text-to-image diffusion models rely on massive, web-scale datasets. Training them from scratch is computationally expensive, and as a result, developers often prefer to make incremental updates to existing models. These updates often compose fine-tuning steps (to learn new concepts or improve model performance) with "unlearning" steps (to "forget" existing concepts, such as copyrighted works or explicit content). In this work, we demonstrate a critical and previously unknown vulnerability that arises in this paradigm: even under benign, non-adversarial conditions, fine-tuning a text-to-image diffusion model on seemingly unrelated images can cause it to "relearn" concepts that were previously "unlearned." We comprehensively investigate the causes and scope of this phenomenon, which we term concept resurgence, by performing a series of experiments which compose "mass concept erasure" (the current state of the art for unlearning in text-to-image diffusion models (Lu et al., 2024)) with subsequent fine-tuning of Stable Diffusion v1.4. Our findings underscore the fragility of composing incremental model updates, and raise serious new concerns about current approaches to ensuring the safety and alignment of text-to-image diffusion models.
From Transparency to Accountability and Back: A Discussion of Access and Evidence in AI Auditing
Oct 07, 2024Artificial intelligence (AI) is increasingly intervening in our lives, raising widespread concern about its unintended and undeclared side effects. These developments have brought attention to the problem of AI auditing: the systematic evaluation and analysis of an AI system, its development, and its behavior relative to a set of predetermined criteria. Auditing can take many forms, including pre-deployment risk assessments, ongoing monitoring, and compliance testing. It plays a critical role in providing assurances to various AI stakeholders, from developers to end users. Audits may, for instance, be used to verify that an algorithm complies with the law, is consistent with industry standards, and meets the developer's claimed specifications. However, there are many operational challenges to AI auditing that complicate its implementation. In this work, we examine a key operational issue in AI auditing: what type of access to an AI system is needed to perform a meaningful audit? Addressing this question has direct policy relevance, as it can inform AI audit guidelines and requirements. We begin by discussing the factors that auditors balance when determining the appropriate type of access, and unpack the benefits and drawbacks of four types of access. We conclude that, at minimum, black-box access -- providing query access to a model without exposing its internal implementation -- should be granted to auditors, as it balances concerns related to trade secrets, data privacy, audit standardization, and audit efficiency. We then suggest a framework for determining how much further access (in addition to black-box access) to grant auditors. We show that auditing can be cast as a natural hypothesis test, draw parallels hypothesis testing and legal procedure, and argue that this framing provides clear and interpretable guidance on audit implementation.
Distinguishing the Indistinguishable: Human Expertise in Algorithmic Prediction
Feb 01, 2024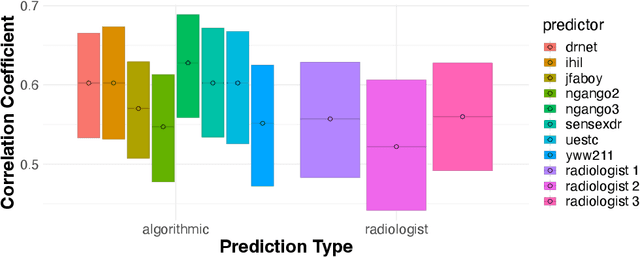
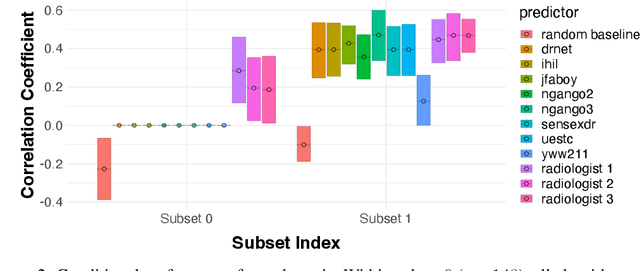
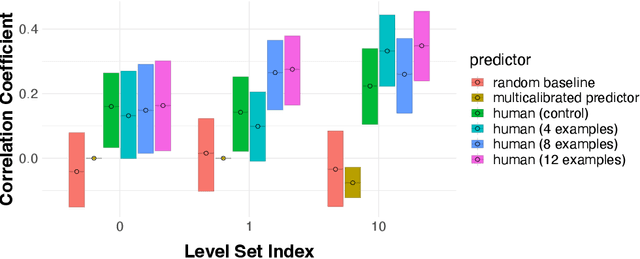

We introduce a novel framework for incorporating human expertise into algorithmic predictions. Our approach focuses on the use of human judgment to distinguish inputs which `look the same' to any feasible predictive algorithm. We argue that this framing clarifies the problem of human/AI collaboration in prediction tasks, as experts often have access to information -- particularly subjective information -- which is not encoded in the algorithm's training data. We use this insight to develop a set of principled algorithms for selectively incorporating human feedback only when it improves the performance of any feasible predictor. We find empirically that although algorithms often outperform their human counterparts on average, human judgment can significantly improve algorithmic predictions on specific instances (which can be identified ex-ante). In an X-ray classification task, we find that this subset constitutes nearly 30% of the patient population. Our approach provides a natural way of uncovering this heterogeneity and thus enabling effective human-AI collaboration.
Auditing for Human Expertise
Jun 02, 2023High-stakes prediction tasks (e.g., patient diagnosis) are often handled by trained human experts. A common source of concern about automation in these settings is that experts may exercise intuition that is difficult to model and/or have access to information (e.g., conversations with a patient) that is simply unavailable to a would-be algorithm. This raises a natural question whether human experts add value which could not be captured by an algorithmic predictor. We develop a statistical framework under which we can pose this question as a natural hypothesis test. Indeed, as our framework highlights, detecting human expertise is more subtle than simply comparing the accuracy of expert predictions to those made by a particular learning algorithm. Instead, we propose a simple procedure which tests whether expert predictions are statistically independent from the outcomes of interest after conditioning on the available inputs (`features'). A rejection of our test thus suggests that human experts may add value to any algorithm trained on the available data, and has direct implications for whether human-AI `complementarity' is achievable in a given prediction task. We highlight the utility of our procedure using admissions data collected from the emergency department of a large academic hospital system, where we show that physicians' admit/discharge decisions for patients with acute gastrointestinal bleeding (AGIB) appear to be incorporating information not captured in a standard algorithmic screening tool. This is despite the fact that the screening tool is arguably more accurate than physicians' discretionary decisions, highlighting that -- even absent normative concerns about accountability or interpretability -- accuracy is insufficient to justify algorithmic automation.