 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCD: Unlearning in LLMs via Contrastive Decoding
Jun 12, 2025Machine unlearning aims to remove specific information, e.g. sensitive or undesirable content, from large language models (LLMs) while preserving overall performance. We propose an inference-time unlearning algorithm that uses contrastive decoding, leveraging two auxiliary smaller models, one trained without the forget set and one trained with it, to guide the outputs of the original model using their difference during inference. Our strategy substantially improves the tradeoff between unlearning effectiveness and model utility. We evaluate our approach on two unlearning benchmarks, TOFU and MUSE. Results show notable gains in both forget quality and retained performance in comparison to prior approaches, suggesting that incorporating contrastive decoding can offer an efficient, practical avenue for unlearning concepts in large-scale models.
Unstable Unlearning: The Hidden Risk of Concept Resurgence in Diffusion Models
Oct 10, 2024
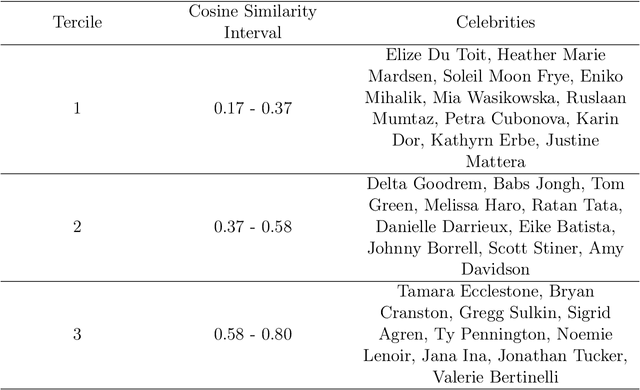
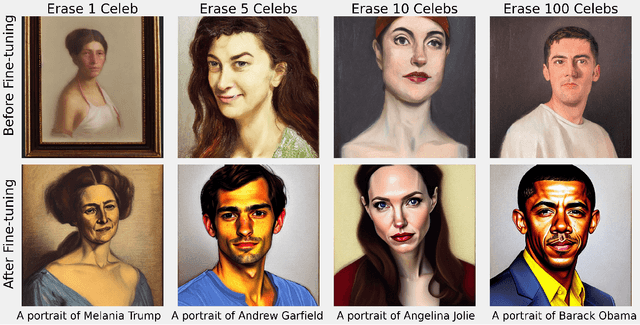
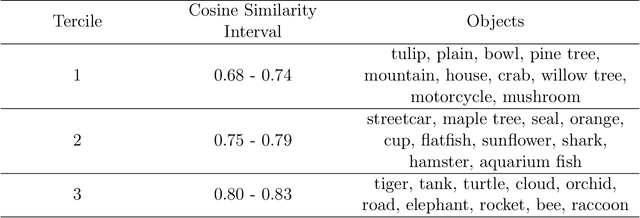
Text-to-image diffusion models rely on massive, web-scale datasets. Training them from scratch is computationally expensive, and as a result, developers often prefer to make incremental updates to existing models. These updates often compose fine-tuning steps (to learn new concepts or improve model performance) with "unlearning" steps (to "forget" existing concepts, such as copyrighted works or explicit content). In this work, we demonstrate a critical and previously unknown vulnerability that arises in this paradigm: even under benign, non-adversarial conditions, fine-tuning a text-to-image diffusion model on seemingly unrelated images can cause it to "relearn" concepts that were previously "unlearned." We comprehensively investigate the causes and scope of this phenomenon, which we term concept resurgence, by performing a series of experiments which compose "mass concept erasure" (the current state of the art for unlearning in text-to-image diffusion models (Lu et al., 2024)) with subsequent fine-tuning of Stable Diffusion v1.4. Our findings underscore the fragility of composing incremental model updates, and raise serious new concerns about current approaches to ensuring the safety and alignment of text-to-image diffusion models.
Algorithms that Approximate Data Removal: New Results and Limitations
Sep 25, 2022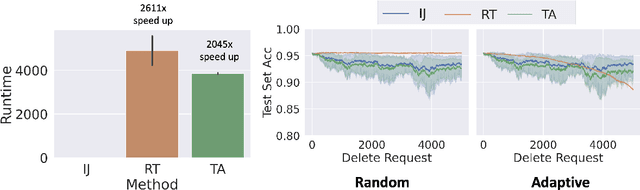
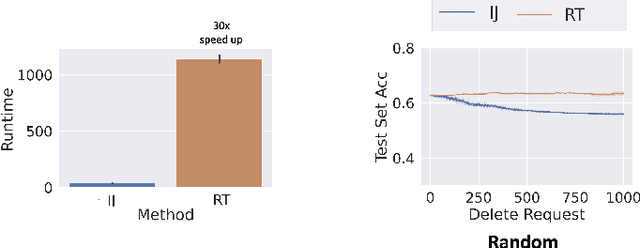
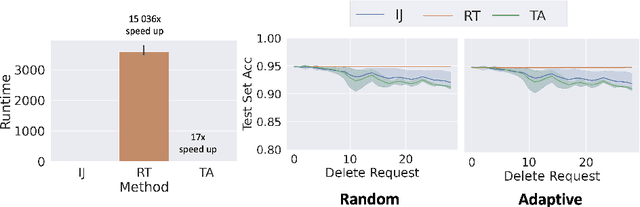
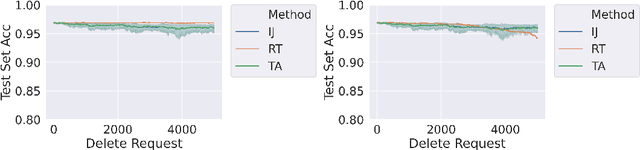
We study the problem of deleting user data from machine learning models trained using empirical risk minimization. Our focus is on learning algorithms which return the empirical risk minimizer and approximate unlearning algorithms that comply with deletion requests that come streaming minibatches. Leveraging the infintesimal jacknife, we develop an online unlearning algorithm that is both computationally and memory efficient. Unlike prior memory efficient unlearning algorithms, we target models that minimize objectives with non-smooth regularizers, such as the commonly used $\ell_1$, elastic net, or nuclear norm penalties. We also provide generalization, deletion capacity, and unlearning guarantees that are consistent with state of the art methods. Across a variety of benchmark datasets, our algorithm empirically improves upon the runtime of prior methods while maintaining the same memory requirements and test accuracy. Finally, we open a new direction of inquiry by proving that all approximate unlearning algorithms introduced so far fail to unlearn in problem settings where common hyperparameter tuning methods, such as cross-validation, have been used to select models.
When Personalization Harms: Reconsidering the Use of Group Attributes in Prediction
Jun 04, 2022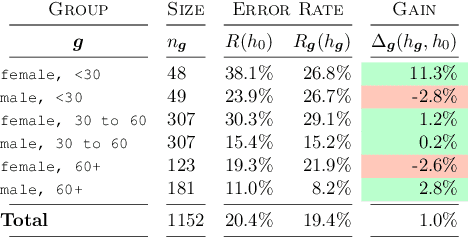
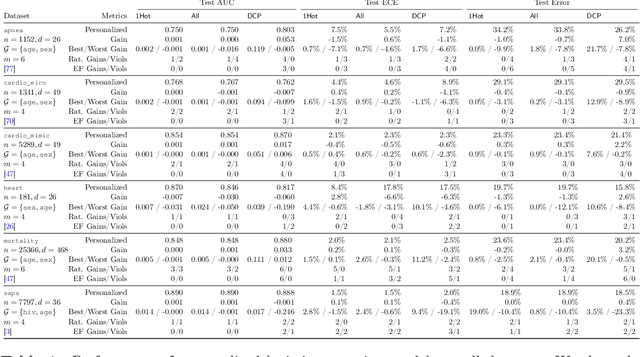
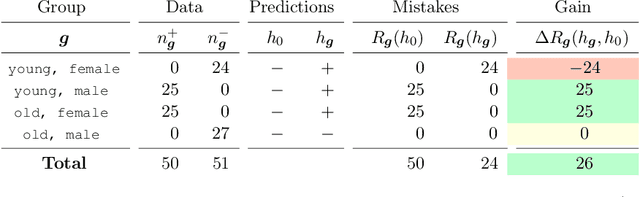

The standard approach to personalization in machine learning consists of training a model with group attributes like sex, age group, and blood type. In this work, we show that this approach to personalization fails to improve performance for all groups who provide personal data. We discuss how this effect inflicts harm in applications where models assign predictions on the basis of group membership. We propose collective preference guarantees to ensure the fair use of group attributes in prediction. We characterize how common approaches to personalization violate fair use due to failures in model development and deployment. We conduct a comprehensive empirical study of personalization in clinical prediction models. Our results highlight the prevalence of fair use violations, demonstrate actionable interventions to mitigate harm and underscore the need to measure the gains of personalization for all groups who provide personal data.
Public Data-Assisted Mirror Descent for Private Model Training
Dec 01, 2021
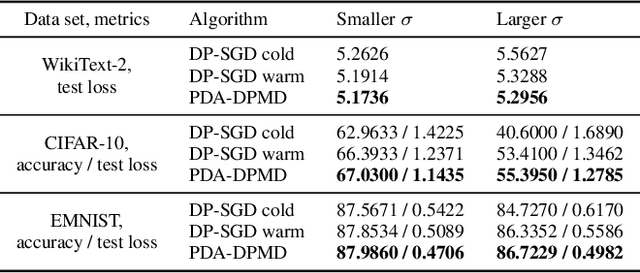


We revisit the problem of using public data to improve the privacy/utility trade-offs for differentially private (DP) model training. Here, public data refers to auxiliary data sets that have no privacy concerns. We consider public data that is from the same distribution as the private training data. For convex losses, we show that a variant of Mirror Descent provides population risk guarantees which are independent of the dimension of the model ($p$). Specifically, we apply Mirror Descent with the loss generated by the public data as the mirror map, and using DP gradients of the loss generated by the private (sensitive) data. To obtain dimension independence, we require $G_Q^2 \leq p$ public data samples, where $G_Q$ is a measure of the isotropy of the loss function. We further show that our algorithm has a natural ``noise stability'' property: If around the current iterate the public loss satisfies $\alpha_v$-strong convexity in a direction $v$, then using noisy gradients instead of the exact gradients shifts our next iterate in the direction $v$ by an amount proportional to $1/\alpha_v$ (in contrast with DP-SGD, where the shift is isotropic). Analogous results in prior works had to explicitly learn the geometry using the public data in the form of preconditioner matrices. Our method is also applicable to non-convex losses, as it does not rely on convexity assumptions to ensure DP guarantees. We demonstrate the empirical efficacy of our algorithm by showing privacy/utility trade-offs on linear regression, deep learning benchmark datasets (WikiText-2, CIFAR-10, and EMNIST), and in federated learning (StackOverflow). We show that our algorithm not only significantly improves over traditional DP-SGD and DP-FedAvg, which do not have access to public data, but also improves over DP-SGD and DP-FedAvg on models that have been pre-trained with the public data to begin with.
Chasing Your Long Tails: Differentially Private Prediction in Health Care Settings
Oct 13, 2020
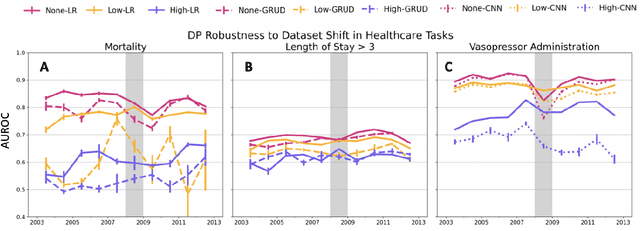


Machine learning models in health care are often deployed in settings where it is important to protect patient privacy. In such settings, methods for differentially private (DP) learning provide a general-purpose approach to learn models with privacy guarantees. Modern methods for DP learning ensure privacy through mechanisms that censor information judged as too unique. The resulting privacy-preserving models, therefore, neglect information from the tails of a data distribution, resulting in a loss of accuracy that can disproportionately affect small groups. In this paper, we study the effects of DP learning in health care. We use state-of-the-art methods for DP learning to train privacy-preserving models in clinical prediction tasks, including x-ray classification of images and mortality prediction in time series data. We use these models to perform a comprehensive empirical investigation of the tradeoffs between privacy, utility, robustness to dataset shift, and fairness. Our results highlight lesser-known limitations of methods for DP learning in health care, models that exhibit steep tradeoffs between privacy and utility, and models whose predictions are disproportionately influenced by large demographic groups in the training data. We discuss the costs and benefits of differentially private learning in health care.
Using Generative Models for Pediatric wbMRI
Jun 01, 2020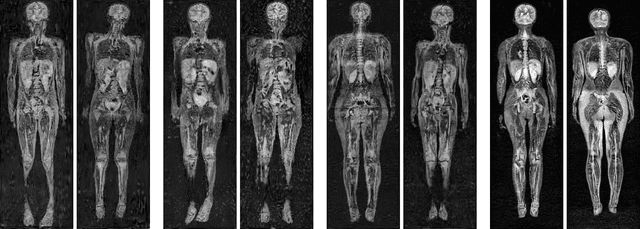

Early detection of cancer is key to a good prognosis and requires frequent testing, especially in pediatrics. Whole-body magnetic resonance imaging (wbMRI) is an essential part of several well-established screening protocols, with screening starting in early childhood. To date, machine learning (ML) has been used on wbMRI images to stage adult cancer patients. It is not possible to use such tools in pediatrics due to the changing bone signal throughout growth, the difficulty of obtaining these images in young children due to movement and limited compliance, and the rarity of positive cases. We evaluate the quality of wbMRI images generated using generative adversarial networks (GANs) trained on wbMRI data from The Hospital for Sick Children in Toronto. We use the Frchet Inception Distance (FID) metric, Domain Frchet Distance (DFD), and blind tests with a radiology fellow for evaluation. We demonstrate that StyleGAN2 provides the best performance in generating wbMRI images with respect to all three metrics.