 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Personalization Harms: Reconsidering the Use of Group Attributes in Prediction
Paper and Code
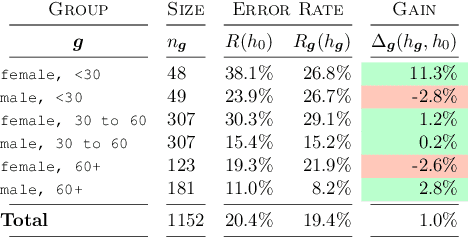
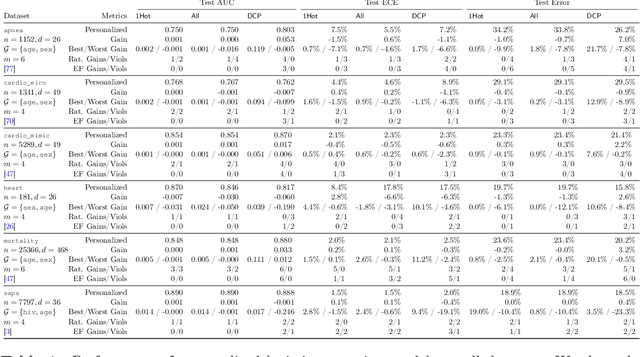
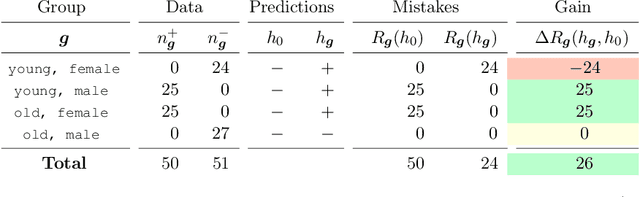

The standard approach to personalization in machine learning consists of training a model with group attributes like sex, age group, and blood type. In this work, we show that this approach to personalization fails to improve performance for all groups who provide personal data. We discuss how this effect inflicts harm in applications where models assign predictions on the basis of group membership. We propose collective preference guarantees to ensure the fair use of group attributes in prediction. We characterize how common approaches to personalization violate fair use due to failures in model development and deployment. We conduct a comprehensive empirical study of personalization in clinical prediction models. Our results highlight the prevalence of fair use violations, demonstrate actionable interventions to mitigate harm and underscore the need to measure the gains of personalization for all groups who provide personal data.