 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePublic Data-Assisted Mirror Descent for Private Model Training
Paper and Code
Dec 01, 2021
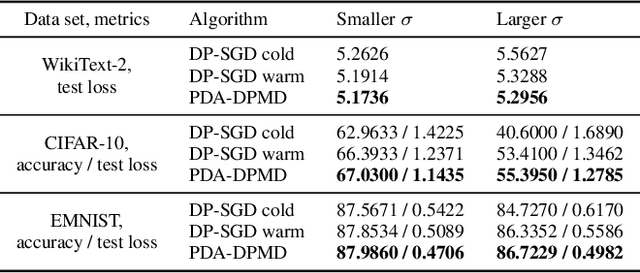


We revisit the problem of using public data to improve the privacy/utility trade-offs for differentially private (DP) model training. Here, public data refers to auxiliary data sets that have no privacy concerns. We consider public data that is from the same distribution as the private training data. For convex losses, we show that a variant of Mirror Descent provides population risk guarantees which are independent of the dimension of the model ($p$). Specifically, we apply Mirror Descent with the loss generated by the public data as the mirror map, and using DP gradients of the loss generated by the private (sensitive) data. To obtain dimension independence, we require $G_Q^2 \leq p$ public data samples, where $G_Q$ is a measure of the isotropy of the loss function. We further show that our algorithm has a natural ``noise stability'' property: If around the current iterate the public loss satisfies $\alpha_v$-strong convexity in a direction $v$, then using noisy gradients instead of the exact gradients shifts our next iterate in the direction $v$ by an amount proportional to $1/\alpha_v$ (in contrast with DP-SGD, where the shift is isotropic). Analogous results in prior works had to explicitly learn the geometry using the public data in the form of preconditioner matrices. Our method is also applicable to non-convex losses, as it does not rely on convexity assumptions to ensure DP guarantees. We demonstrate the empirical efficacy of our algorithm by showing privacy/utility trade-offs on linear regression, deep learning benchmark datasets (WikiText-2, CIFAR-10, and EMNIST), and in federated learning (StackOverflow). We show that our algorithm not only significantly improves over traditional DP-SGD and DP-FedAvg, which do not have access to public data, but also improves over DP-SGD and DP-FedAvg on models that have been pre-trained with the public data to begin with.