 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelated Noise Mechanisms for Differentially Private Learning
Jun 09, 2025
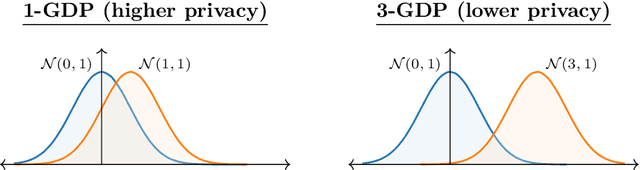

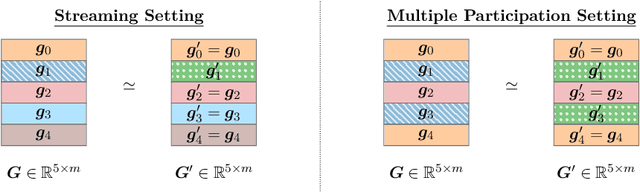
This monograph explores the design and analysis of correlated noise mechanisms for differential privacy (DP), focusing on their application to private training of AI and machine learning models via the core primitive of estimation of weighted prefix sums. While typical DP mechanisms inject independent noise into each step of a stochastic gradient (SGD) learning algorithm in order to protect the privacy of the training data, a growing body of recent research demonstrates that introducing (anti-)correlations in the noise can significantly improve privacy-utility trade-offs by carefully canceling out some of the noise added on earlier steps in subsequent steps. Such correlated noise mechanisms, known variously as matrix mechanisms, factorization mechanisms, and DP-Follow-the-Regularized-Leader (DP-FTRL) when applied to learning algorithms, have also been influential in practice, with industrial deployment at a global scale.
The Last Iterate Advantage: Empirical Auditing and Principled Heuristic Analysis of Differentially Private SGD
Oct 10, 2024We propose a simple heuristic privacy analysis of noisy clipped stochastic gradient descent (DP-SGD) in the setting where only the last iterate is released and the intermediate iterates remain hidden. Namely, our heuristic assumes a linear structure for the model. We show experimentally that our heuristic is predictive of the outcome of privacy auditing applied to various training procedures. Thus it can be used prior to training as a rough estimate of the final privacy leakage. We also probe the limitations of our heuristic by providing some artificial counterexamples where it underestimates the privacy leakage. The standard composition-based privacy analysis of DP-SGD effectively assumes that the adversary has access to all intermediate iterates, which is often unrealistic. However, this analysis remains the state of the art in practice. While our heuristic does not replace a rigorous privacy analysis, it illustrates the large gap between the best theoretical upper bounds and the privacy auditing lower bounds and sets a target for further work to improve the theoretical privacy analyses. We also empirically support our heuristic and show existing privacy auditing attacks are bounded by our heuristic analysis in both vision and language tasks.
Private Geometric Median
Jun 11, 2024In this paper, we study differentially private (DP) algorithms for computing the geometric median (GM) of a dataset: Given $n$ points, $x_1,\dots,x_n$ in $\mathbb{R}^d$, the goal is to find a point $\theta$ that minimizes the sum of the Euclidean distances to these points, i.e., $\sum_{i=1}^{n} \|\theta - x_i\|_2$. Off-the-shelf methods, such as DP-GD, require strong a priori knowledge locating the data within a ball of radius $R$, and the excess risk of the algorithm depends linearly on $R$. In this paper, we ask: can we design an efficient and private algorithm with an excess error guarantee that scales with the (unknown) radius containing the majority of the datapoints? Our main contribution is a pair of polynomial-time DP algorithms for the task of private GM with an excess error guarantee that scales with the effective diameter of the datapoints. Additionally, we propose an inefficient algorithm based on the inverse smooth sensitivity mechanism, which satisfies the more restrictive notion of pure DP. We complement our results with a lower bound and demonstrate the optimality of our polynomial-time algorithms in terms of sample complexity.
Avoiding Pitfalls for Privacy Accounting of Subsampled Mechanisms under Composition
May 27, 2024We consider the problem of computing tight privacy guarantees for the composition of subsampled differentially private mechanisms. Recent algorithms can numerically compute the privacy parameters to arbitrary precision but must be carefully applied. Our main contribution is to address two common points of confusion. First, some privacy accountants assume that the privacy guarantees for the composition of a subsampled mechanism are determined by self-composing the worst-case datasets for the uncomposed mechanism. We show that this is not true in general. Second, Poisson subsampling is sometimes assumed to have similar privacy guarantees compared to sampling without replacement. We show that the privacy guarantees may in fact differ significantly between the two sampling schemes. In particular, we give an example of hyperparameters that result in $\varepsilon \approx 1$ for Poisson subsampling and $\varepsilon > 10$ for sampling without replacement. This occurs for some parameters that could realistically be chosen for DP-SGD.
Efficient and Near-Optimal Noise Generation for Streaming Differential Privacy
Apr 26, 2024In the task of differentially private (DP) continual counting, we receive a stream of increments and our goal is to output an approximate running total of these increments, without revealing too much about any specific increment. Despite its simplicity, differentially private continual counting has attracted significant attention both in theory and in practice. Existing algorithms for differentially private continual counting are either inefficient in terms of their space usage or add an excessive amount of noise, inducing suboptimal utility. The most practical DP continual counting algorithms add carefully correlated Gaussian noise to the values. The task of choosing the covariance for this noise can be expressed in terms of factoring the lower-triangular matrix of ones (which computes prefix sums). We present two approaches from this class (for different parameter regimes) that achieve near-optimal utility for DP continual counting and only require logarithmic or polylogarithmic space (and time). Our first approach is based on a space-efficient streaming matrix multiplication algorithm for a class of Toeplitz matrices. We show that to instantiate this algorithm for DP continual counting, it is sufficient to find a low-degree rational function that approximates the square root on a circle in the complex plane. We then apply and extend tools from approximation theory to achieve this. We also derive efficient closed-forms for the objective function for arbitrarily many steps, and show direct numerical optimization yields a highly practical solution to the problem. Our second approach combines our first approach with a recursive construction similar to the binary tree mechanism.
Privacy Amplification for Matrix Mechanisms
Oct 24, 2023



Privacy amplification exploits randomness in data selection to provide tighter differential privacy (DP) guarantees. This analysis is key to DP-SGD's success in machine learning, but, is not readily applicable to the newer state-of-the-art algorithms. This is because these algorithms, known as DP-FTRL, use the matrix mechanism to add correlated noise instead of independent noise as in DP-SGD. In this paper, we propose "MMCC", the first algorithm to analyze privacy amplification via sampling for any generic matrix mechanism. MMCC is nearly tight in that it approaches a lower bound as $\epsilon\to0$. To analyze correlated outputs in MMCC, we prove that they can be analyzed as if they were independent, by conditioning them on prior outputs. Our "conditional composition theorem" has broad utility: we use it to show that the noise added to binary-tree-DP-FTRL can asymptotically match the noise added to DP-SGD with amplification. Our amplification algorithm also has practical empirical utility: we show it leads to significant improvement in the privacy-utility trade-offs for DP-FTRL algorithms on standard benchmarks.
Correlated Noise Provably Beats Independent Noise for Differentially Private Learning
Oct 10, 2023



Differentially private learning algorithms inject noise into the learning process. While the most common private learning algorithm, DP-SGD, adds independent Gaussian noise in each iteration, recent work on matrix factorization mechanisms has shown empirically that introducing correlations in the noise can greatly improve their utility. We characterize the asymptotic learning utility for any choice of the correlation function, giving precise analytical bounds for linear regression and as the solution to a convex program for general convex functions. We show, using these bounds, how correlated noise provably improves upon vanilla DP-SGD as a function of problem parameters such as the effective dimension and condition number. Moreover, our analytical expression for the near-optimal correlation function circumvents the cubic complexity of the semi-definite program used to optimize the noise correlation matrix in previous work. We validate our theory with experiments on private deep learning. Our work matches or outperforms prior work while being efficient both in terms of compute and memory.
Differentially Private Medians and Interior Points for Non-Pathological Data
May 22, 2023We construct differentially private estimators with low sample complexity that estimate the median of an arbitrary distribution over $\mathbb{R}$ satisfying very mild moment conditions. Our result stands in contrast to the surprising negative result of Bun et al. (FOCS 2015) that showed there is no differentially private estimator with any finite sample complexity that returns any non-trivial approximation to the median of an arbitrary distribution.
Faster Differentially Private Convex Optimization via Second-Order Methods
May 22, 2023



Differentially private (stochastic) gradient descent is the workhorse of DP private machine learning in both the convex and non-convex settings. Without privacy constraints, second-order methods, like Newton's method, converge faster than first-order methods like gradient descent. In this work, we investigate the prospect of using the second-order information from the loss function to accelerate DP convex optimization. We first develop a private variant of the regularized cubic Newton method of Nesterov and Polyak, and show that for the class of strongly convex loss functions, our algorithm has quadratic convergence and achieves the optimal excess loss. We then design a practical second-order DP algorithm for the unconstrained logistic regression problem. We theoretically and empirically study the performance of our algorithm. Empirical results show our algorithm consistently achieves the best excess loss compared to other baselines and is 10-40x faster than DP-GD/DP-SGD.
Privacy Auditing with One (1) Training Run
May 15, 2023We propose a scheme for auditing differentially private machine learning systems with a single training run. This exploits the parallelism of being able to add or remove multiple training examples independently. We analyze this using the connection between differential privacy and statistical generalization, which avoids the cost of group privacy. Our auditing scheme requires minimal assumptions about the algorithm and can be applied in the black-box or white-box setting.