 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalized Square Root: Sharper Matrix Factorization Bounds for Differentially Private Continual Counting
Sep 17, 2025The factorization norms of the lower-triangular all-ones $n \times n$ matrix, $\gamma_2(M_{count})$ and $\gamma_{F}(M_{count})$, play a central role in differential privacy as they are used to give theoretical justification of the accuracy of the only known production-level private training algorithm of deep neural networks by Google. Prior to this work, the best known upper bound on $\gamma_2(M_{count})$ was $1 + \frac{\log n}{\pi}$ by Mathias (Linear Algebra and Applications, 1993), and the best known lower bound was $\frac{1}{\pi}(2 + \log(\frac{2n+1}{3})) \approx 0.507 + \frac{\log n}{\pi}$ (Matou\v{s}ek, Nikolov, Talwar, IMRN 2020), where $\log$ denotes the natural logarithm. Recently, Henzinger and Upadhyay (SODA 2025) gave the first explicit factorization that meets the bound of Mathias (1993) and asked whether there exists an explicit factorization that improves on Mathias' bound. We answer this question in the affirmative. Additionally, we improve the lower bound significantly. More specifically, we show that $$ 0.701 + \frac{\log n}{\pi} + o(1) \;\leq\; \gamma_2(M_{count}) \;\leq\; 0.846 + \frac{\log n}{\pi} + o(1). $$ That is, we reduce the gap between the upper and lower bound to $0.14 + o(1)$. We also show that our factors achieve a better upper bound for $\gamma_{F}(M_{count})$ compared to prior work, and we establish an improved lower bound: $$ 0.701 + \frac{\log n}{\pi} + o(1) \;\leq\; \gamma_{F}(M_{count}) \;\leq\; 0.748 + \frac{\log n}{\pi} + o(1). $$ That is, the gap between the lower and upper bound provided by our explicit factorization is $0.047 + o(1)$.
Correlated Noise Mechanisms for Differentially Private Learning
Jun 09, 2025
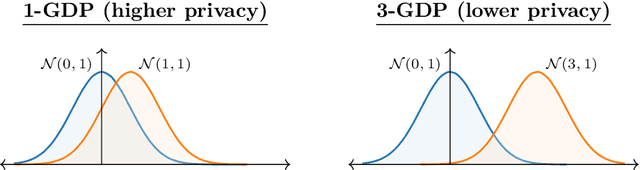

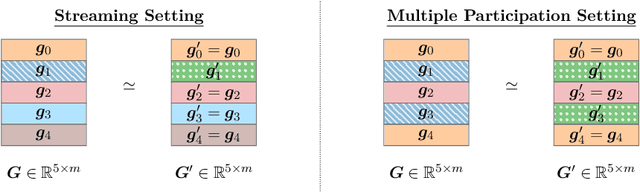
This monograph explores the design and analysis of correlated noise mechanisms for differential privacy (DP), focusing on their application to private training of AI and machine learning models via the core primitive of estimation of weighted prefix sums. While typical DP mechanisms inject independent noise into each step of a stochastic gradient (SGD) learning algorithm in order to protect the privacy of the training data, a growing body of recent research demonstrates that introducing (anti-)correlations in the noise can significantly improve privacy-utility trade-offs by carefully canceling out some of the noise added on earlier steps in subsequent steps. Such correlated noise mechanisms, known variously as matrix mechanisms, factorization mechanisms, and DP-Follow-the-Regularized-Leader (DP-FTRL) when applied to learning algorithms, have also been influential in practice, with industrial deployment at a global scale.
Binned Group Algebra Factorization for Differentially Private Continual Counting
Apr 06, 2025We study memory-efficient matrix factorization for differentially private counting under continual observation. While recent work by Henzinger and Upadhyay 2024 introduced a factorization method with reduced error based on group algebra, its practicality in streaming settings remains limited by computational constraints. We present new structural properties of the group algebra factorization, enabling the use of a binning technique from Andersson and Pagh (2024). By grouping similar values in rows, the binning method reduces memory usage and running time to $\tilde O(\sqrt{n})$, where $n$ is the length of the input stream, while maintaining a low error. Our work bridges the gap between theoretical improvements in factorization accuracy and practical efficiency in large-scale private learning systems.
Expander Hierarchies for Normalized Cuts on Graphs
Jun 20, 2024Expander decompositions of graphs have significantly advanced the understanding of many classical graph problems and led to numerous fundamental theoretical results. However, their adoption in practice has been hindered due to their inherent intricacies and large hidden factors in their asymptotic running times. Here, we introduce the first practically efficient algorithm for computing expander decompositions and their hierarchies and demonstrate its effectiveness and utility by incorporating it as the core component in a novel solver for the normalized cut graph clustering objective. Our extensive experiments on a variety of large graphs show that our expander-based algorithm outperforms state-of-the-art solvers for normalized cut with respect to solution quality by a large margin on a variety of graph classes such as citation, e-mail, and social networks or web graphs while remaining competitive in running time.
Making Old Things New: A Unified Algorithm for Differentially Private Clustering
Jun 17, 2024As a staple of data analysis and unsupervised learning, the problem of private clustering has been widely studied under various privacy models. Centralized differential privacy is the first of them, and the problem has also been studied for the local and the shuffle variation. In each case, the goal is to design an algorithm that computes privately a clustering, with the smallest possible error. The study of each variation gave rise to new algorithms: the landscape of private clustering algorithms is therefore quite intricate. In this paper, we show that a 20-year-old algorithm can be slightly modified to work for any of these models. This provides a unified picture: while matching almost all previously known results, it allows us to improve some of them and extend it to a new privacy model, the continual observation setting, where the input is changing over time and the algorithm must output a new solution at each time step.
Data-Efficient Learning via Clustering-Based Sensitivity Sampling: Foundation Models and Beyond
Feb 27, 2024



We study the data selection problem, whose aim is to select a small representative subset of data that can be used to efficiently train a machine learning model. We present a new data selection approach based on $k$-means clustering and sensitivity sampling. Assuming access to an embedding representation of the data with respect to which the model loss is H\"older continuous, our approach provably allows selecting a set of ``typical'' $k + 1/\varepsilon^2$ elements whose average loss corresponds to the average loss of the whole dataset, up to a multiplicative $(1\pm\varepsilon)$ factor and an additive $\varepsilon \lambda \Phi_k$, where $\Phi_k$ represents the $k$-means cost for the input embeddings and $\lambda$ is the H\"older constant. We furthermore demonstrate the performance and scalability of our approach on fine-tuning foundation models and show that it outperforms state-of-the-art methods. We also show how it can be applied on linear regression, leading to a new sampling strategy that surprisingly matches the performances of leverage score sampling, while being conceptually simpler and more scalable.
Simple, Scalable and Effective Clustering via One-Dimensional Projections
Oct 25, 2023Clustering is a fundamental problem in unsupervised machine learning with many applications in data analysis. Popular clustering algorithms such as Lloyd's algorithm and $k$-means++ can take $\Omega(ndk)$ time when clustering $n$ points in a $d$-dimensional space (represented by an $n\times d$ matrix $X$) into $k$ clusters. In applications with moderate to large $k$, the multiplicative $k$ factor can become very expensive. We introduce a simple randomized clustering algorithm that provably runs in expected time $O(\mathrm{nnz}(X) + n\log n)$ for arbitrary $k$. Here $\mathrm{nnz}(X)$ is the total number of non-zero entries in the input dataset $X$, which is upper bounded by $nd$ and can be significantly smaller for sparse datasets. We prove that our algorithm achieves approximation ratio $\smash{\widetilde{O}(k^4)}$ on any input dataset for the $k$-means objective. We also believe that our theoretical analysis is of independent interest, as we show that the approximation ratio of a $k$-means algorithm is approximately preserved under a class of projections and that $k$-means++ seeding can be implemented in expected $O(n \log n)$ time in one dimension. Finally, we show experimentally that our clustering algorithm gives a new tradeoff between running time and cluster quality compared to previous state-of-the-art methods for these tasks.
Differential Privacy for Clustering Under Continual Observation
Jul 27, 2023
We consider the problem of clustering privately a dataset in $\mathbb{R}^d$ that undergoes both insertion and deletion of points. Specifically, we give an $\varepsilon$-differentially private clustering mechanism for the $k$-means objective under continual observation. This is the first approximation algorithm for that problem with an additive error that depends only logarithmically in the number $T$ of updates. The multiplicative error is almost the same as non privately. To do so we show how to perform dimension reduction under continual observation and combine it with a differentially private greedy approximation algorithm for $k$-means. We also partially extend our results to the $k$-median problem.
A Unifying Framework for Differentially Private Sums under Continual Observation
Jul 18, 2023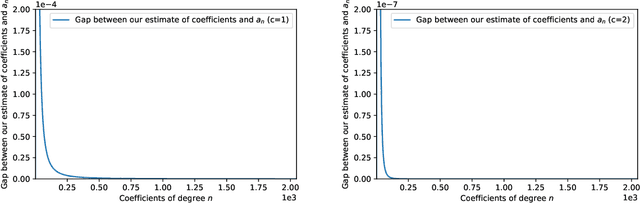
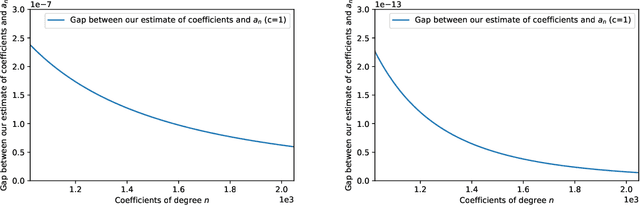
We study the problem of maintaining a differentially private decaying sum under continual observation. We give a unifying framework and an efficient algorithm for this problem for \emph{any sufficiently smooth} function. Our algorithm is the first differentially private algorithm that does not have a multiplicative error for polynomially-decaying weights. Our algorithm improves on all prior works on differentially private decaying sums under continual observation and recovers exactly the additive error for the special case of continual counting from Henzinger et al. (SODA 2023) as a corollary. Our algorithm is a variant of the factorization mechanism whose error depends on the $\gamma_2$ and $\gamma_F$ norm of the underlying matrix. We give a constructive proof for an almost exact upper bound on the $\gamma_2$ and $\gamma_F$ norm and an almost tight lower bound on the $\gamma_2$ norm for a large class of lower-triangular matrices. This is the first non-trivial lower bound for lower-triangular matrices whose non-zero entries are not all the same. It includes matrices for all continual decaying sums problems, resulting in an upper bound on the additive error of any differentially private decaying sums algorithm under continual observation. We also explore some implications of our result in discrepancy theory and operator algebra. Given the importance of the $\gamma_2$ norm in computer science and the extensive work in mathematics, we believe our result will have further applications.
Almost Tight Error Bounds on Differentially Private Continual Counting
Nov 09, 2022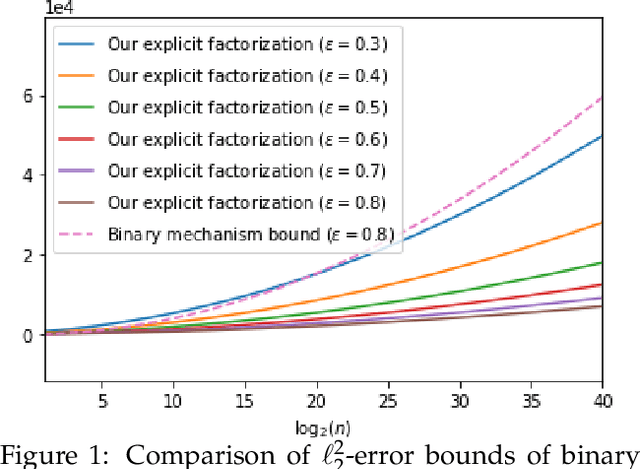
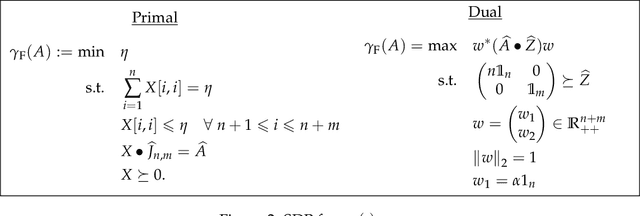
The first large-scale deployment of private federated learning uses differentially private counting in the continual release model as a subroutine (Google AI blog titled "Federated Learning with Formal Differential Privacy Guarantees"). In this case, a concrete bound on the error is very relevant to reduce the privacy parameter. The standard mechanism for continual counting is the binary mechanism. We present a novel mechanism and show that its mean squared error is both asymptotically optimal and a factor 10 smaller than the error of the binary mechanism. We also show that the constants in our analysis are almost tight by giving non-asymptotic lower and upper bounds that differ only in the constants of lower-order terms. Our algorithm is a matrix mechanism for the counting matrix and takes constant time per release. We also use our explicit factorization of the counting matrix to give an upper bound on the excess risk of the private learning algorithm of Denisov et al. (NeurIPS 2022). Our lower bound for any continual counting mechanism is the first tight lower bound on continual counting under approximate differential privacy. It is achieved using a new lower bound on a certain factorization norm, denoted by $\gamma_F(\cdot)$, in terms of the singular values of the matrix. In particular, we show that for any complex matrix, $A \in \mathbb{C}^{m \times n}$, \[ \gamma_F(A) \geq \frac{1}{\sqrt{m}}\|A\|_1, \] where $\|\cdot \|$ denotes the Schatten-1 norm. We believe this technique will be useful in proving lower bounds for a larger class of linear queries. To illustrate the power of this technique, we show the first lower bound on the mean squared error for answering parity queries.