 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Federated $k$-Means Clustering with Server-Side Data
Jun 04, 2025Clustering is a cornerstone of data analysis that is particularly suited to identifying coherent subgroups or substructures in unlabeled data, as are generated continuously in large amounts these days. However, in many cases traditional clustering methods are not applicable, because data are increasingly being produced and stored in a distributed way, e.g. on edge devices, and privacy concerns prevent it from being transferred to a central server. To address this challenge, we present \acronym, a new algorithm for $k$-means clustering that is fully-federated as well as differentially private. Our approach leverages (potentially small and out-of-distribution) server-side data to overcome the primary challenge of differentially private clustering methods: the need for a good initialization. Combining our initialization with a simple federated DP-Lloyds algorithm we obtain an algorithm that achieves excellent results on synthetic and real-world benchmark tasks. We also provide a theoretical analysis of our method that provides bounds on the convergence speed and cluster identification success.
A Tight VC-Dimension Analysis of Clustering Coresets with Applications
Jan 11, 2025


We consider coresets for $k$-clustering problems, where the goal is to assign points to centers minimizing powers of distances. A popular example is the $k$-median objective $\sum_{p}\min_{c\in C}dist(p,C)$. Given a point set $P$, a coreset $\Omega$ is a small weighted subset that approximates the cost of $P$ for all candidate solutions $C$ up to a $(1\pm\varepsilon )$ multiplicative factor. In this paper, we give a sharp VC-dimension based analysis for coreset construction. As a consequence, we obtain improved $k$-median coreset bounds for the following metrics: Coresets of size $\tilde{O}\left(k\varepsilon^{-2}\right)$ for shortest path metrics in planar graphs, improving over the bounds $\tilde{O}\left(k\varepsilon^{-6}\right)$ by [Cohen-Addad, Saulpic, Schwiegelshohn, STOC'21] and $\tilde{O}\left(k^2\varepsilon^{-4}\right)$ by [Braverman, Jiang, Krauthgamer, Wu, SODA'21]. Coresets of size $\tilde{O}\left(kd\ell\varepsilon^{-2}\log m\right)$ for clustering $d$-dimensional polygonal curves of length at most $m$ with curves of length at most $\ell$ with respect to Frechet metrics, improving over the bounds $\tilde{O}\left(k^3d\ell\varepsilon^{-3}\log m\right)$ by [Braverman, Cohen-Addad, Jiang, Krauthgamer, Schwiegelshohn, Toftrup, and Wu, FOCS'22] and $\tilde{O}\left(k^2d\ell\varepsilon^{-2}\log m \log |P|\right)$ by [Conradi, Kolbe, Psarros, Rohde, SoCG'24].
Almost-linear Time Approximation Algorithm to Euclidean $k$-median and $k$-means
Jul 15, 2024Clustering is one of the staples of data analysis and unsupervised learning. As such, clustering algorithms are often used on massive data sets, and they need to be extremely fast. We focus on the Euclidean $k$-median and $k$-means problems, two of the standard ways to model the task of clustering. For these, the go-to algorithm is $k$-means++, which yields an $O(\log k)$-approximation in time $\tilde O(nkd)$. While it is possible to improve either the approximation factor [Lattanzi and Sohler, ICML19] or the running time [Cohen-Addad et al., NeurIPS 20], it is unknown how precise a linear-time algorithm can be. In this paper, we almost answer this question by presenting an almost linear-time algorithm to compute a constant-factor approximation.
Making Old Things New: A Unified Algorithm for Differentially Private Clustering
Jun 17, 2024As a staple of data analysis and unsupervised learning, the problem of private clustering has been widely studied under various privacy models. Centralized differential privacy is the first of them, and the problem has also been studied for the local and the shuffle variation. In each case, the goal is to design an algorithm that computes privately a clustering, with the smallest possible error. The study of each variation gave rise to new algorithms: the landscape of private clustering algorithms is therefore quite intricate. In this paper, we show that a 20-year-old algorithm can be slightly modified to work for any of these models. This provides a unified picture: while matching almost all previously known results, it allows us to improve some of them and extend it to a new privacy model, the continual observation setting, where the input is changing over time and the algorithm must output a new solution at each time step.
Settling Time vs. Accuracy Tradeoffs for Clustering Big Data
Apr 02, 2024


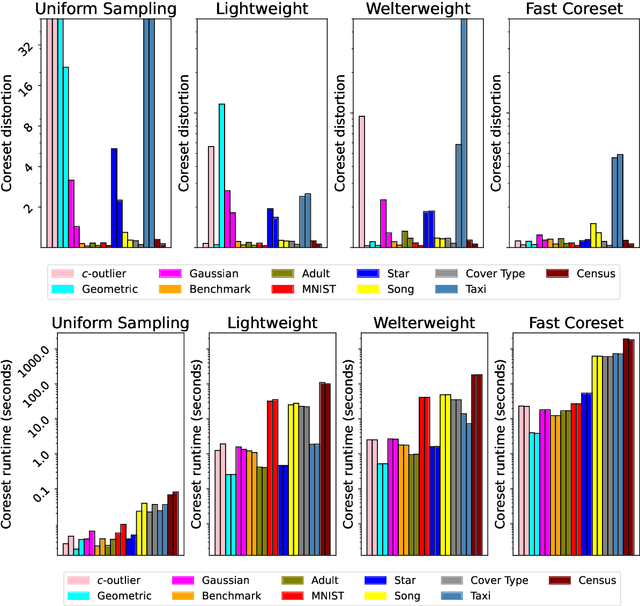
We study the theoretical and practical runtime limits of k-means and k-median clustering on large datasets. Since effectively all clustering methods are slower than the time it takes to read the dataset, the fastest approach is to quickly compress the data and perform the clustering on the compressed representation. Unfortunately, there is no universal best choice for compressing the number of points - while random sampling runs in sublinear time and coresets provide theoretical guarantees, the former does not enforce accuracy while the latter is too slow as the numbers of points and clusters grow. Indeed, it has been conjectured that any sensitivity-based coreset construction requires super-linear time in the dataset size. We examine this relationship by first showing that there does exist an algorithm that obtains coresets via sensitivity sampling in effectively linear time - within log-factors of the time it takes to read the data. Any approach that significantly improves on this must then resort to practical heuristics, leading us to consider the spectrum of sampling strategies across both real and artificial datasets in the static and streaming settings. Through this, we show the conditions in which coresets are necessary for preserving cluster validity as well as the settings in which faster, cruder sampling strategies are sufficient. As a result, we provide a comprehensive theoretical and practical blueprint for effective clustering regardless of data size. Our code is publicly available and has scripts to recreate the experiments.
Data-Efficient Learning via Clustering-Based Sensitivity Sampling: Foundation Models and Beyond
Feb 27, 2024



We study the data selection problem, whose aim is to select a small representative subset of data that can be used to efficiently train a machine learning model. We present a new data selection approach based on $k$-means clustering and sensitivity sampling. Assuming access to an embedding representation of the data with respect to which the model loss is H\"older continuous, our approach provably allows selecting a set of ``typical'' $k + 1/\varepsilon^2$ elements whose average loss corresponds to the average loss of the whole dataset, up to a multiplicative $(1\pm\varepsilon)$ factor and an additive $\varepsilon \lambda \Phi_k$, where $\Phi_k$ represents the $k$-means cost for the input embeddings and $\lambda$ is the H\"older constant. We furthermore demonstrate the performance and scalability of our approach on fine-tuning foundation models and show that it outperforms state-of-the-art methods. We also show how it can be applied on linear regression, leading to a new sampling strategy that surprisingly matches the performances of leverage score sampling, while being conceptually simpler and more scalable.
Differential Privacy for Clustering Under Continual Observation
Jul 27, 2023
We consider the problem of clustering privately a dataset in $\mathbb{R}^d$ that undergoes both insertion and deletion of points. Specifically, we give an $\varepsilon$-differentially private clustering mechanism for the $k$-means objective under continual observation. This is the first approximation algorithm for that problem with an additive error that depends only logarithmically in the number $T$ of updates. The multiplicative error is almost the same as non privately. To do so we show how to perform dimension reduction under continual observation and combine it with a differentially private greedy approximation algorithm for $k$-means. We also partially extend our results to the $k$-median problem.
Improved Coresets for Euclidean $k$-Means
Nov 16, 2022Given a set of $n$ points in $d$ dimensions, the Euclidean $k$-means problem (resp. the Euclidean $k$-median problem) consists of finding $k$ centers such that the sum of squared distances (resp. sum of distances) from every point to its closest center is minimized. The arguably most popular way of dealing with this problem in the big data setting is to first compress the data by computing a weighted subset known as a coreset and then run any algorithm on this subset. The guarantee of the coreset is that for any candidate solution, the ratio between coreset cost and the cost of the original instance is less than a $(1\pm \varepsilon)$ factor. The current state of the art coreset size is $\tilde O(\min(k^{2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-4}))$ for Euclidean $k$-means and $\tilde O(\min(k^{2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-3}))$ for Euclidean $k$-median. The best known lower bound for both problems is $\Omega(k \varepsilon^{-2})$. In this paper, we improve the upper bounds $\tilde O(\min(k^{3/2} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-4}))$ for $k$-means and $\tilde O(\min(k^{4/3} \cdot \varepsilon^{-2},k\cdot \varepsilon^{-3}))$ for $k$-median. In particular, ours is the first provable bound that breaks through the $k^2$ barrier while retaining an optimal dependency on $\varepsilon$.
Scalable Differentially Private Clustering via Hierarchically Separated Trees
Jun 17, 2022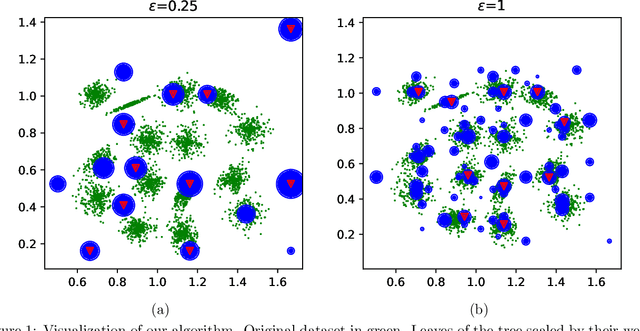
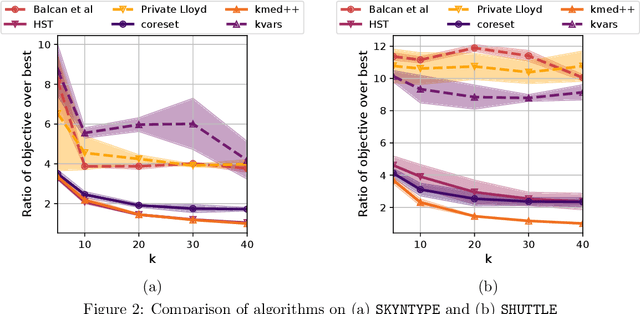
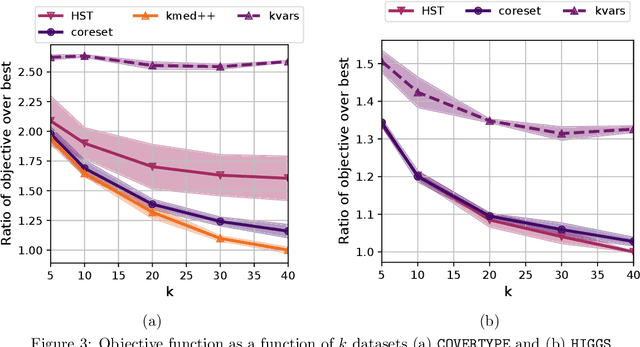
We study the private $k$-median and $k$-means clustering problem in $d$ dimensional Euclidean space. By leveraging tree embeddings, we give an efficient and easy to implement algorithm, that is empirically competitive with state of the art non private methods. We prove that our method computes a solution with cost at most $O(d^{3/2}\log n)\cdot OPT + O(k d^2 \log^2 n / \epsilon^2)$, where $\epsilon$ is the privacy guarantee. (The dimension term, $d$, can be replaced with $O(\log k)$ using standard dimension reduction techniques.) Although the worst-case guarantee is worse than that of state of the art private clustering methods, the algorithm we propose is practical, runs in near-linear, $\tilde{O}(nkd)$, time and scales to tens of millions of points. We also show that our method is amenable to parallelization in large-scale distributed computing environments. In particular we show that our private algorithms can be implemented in logarithmic number of MPC rounds in the sublinear memory regime. Finally, we complement our theoretical analysis with an empirical evaluation demonstrating the algorithm's efficiency and accuracy in comparison to other privacy clustering baselines.
Towards Optimal Lower Bounds for k-median and k-means Coresets
Feb 25, 2022
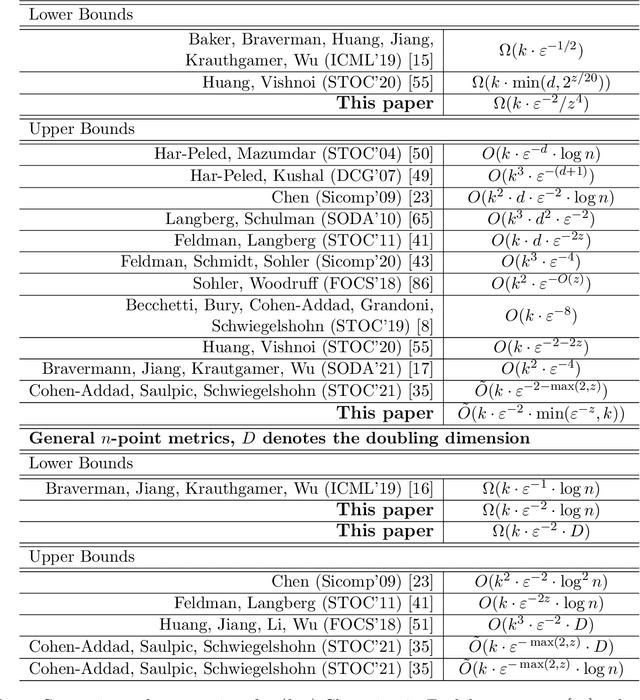
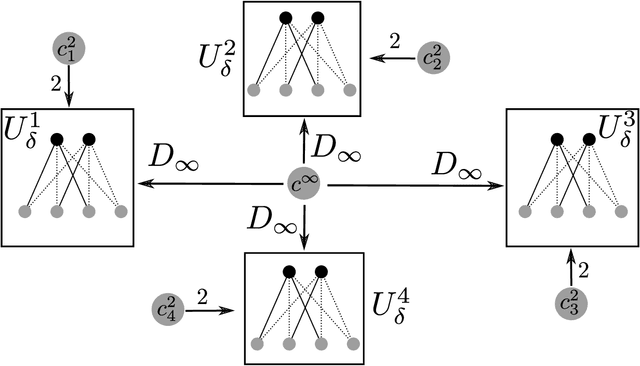
Given a set of points in a metric space, the $(k,z)$-clustering problem consists of finding a set of $k$ points called centers, such that the sum of distances raised to the power of $z$ of every data point to its closest center is minimized. Special cases include the famous k-median problem ($z = 1$) and k-means problem ($z = 2$). The $k$-median and $k$-means problems are at the heart of modern data analysis and massive data applications have given raise to the notion of coreset: a small (weighted) subset of the input point set preserving the cost of any solution to the problem up to a multiplicative $(1 \pm \varepsilon)$ factor, hence reducing from large to small scale the input to the problem. In this paper, we present improved lower bounds for coresets in various metric spaces. In finite metrics consisting of $n$ points and doubling metrics with doubling constant $D$, we show that any coreset for $(k,z)$ clustering must consist of at least $\Omega(k \varepsilon^{-2} \log n)$ and $\Omega(k \varepsilon^{-2} D)$ points, respectively. Both bounds match previous upper bounds up to polylog factors. In Euclidean spaces, we show that any coreset for $(k,z)$ clustering must consists of at least $\Omega(k\varepsilon^{-2})$ points. We complement these lower bounds with a coreset construction consisting of at most $\tilde{O}(k\varepsilon^{-2}\cdot \min(\varepsilon^{-z},k))$ points.