 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantoms and Disclosures: a Causal Framework for Auditing Synthetic Data
Jun 15, 2026The rapid adoption of generative AI and Large Language Models (LLMs) has spurred interest in synthetic data as a privacy-preserving alternative to sensitive real-world datasets. However, generating high-utility synthetic data often carries the risk of memorizing and regurgitating private information from the training corpus. In this work, we present a customizable empirical auditing framework designed to detect and explain such data disclosures. Our framework introduces a mechanism to distinguish between "true disclosures"-where the system directly reproduces a user's information-and "phantom disclosures''-where the system incidentally generates a user's data. By partitioning input data into training and holdout sets and applying rigorous statistical hypothesis testing, we determine if observed disclosures are consistent with strict privacy baselines, such as zero-learning or specific Differential Privacy (DP) bounds. Crucially, this approach requires no model access, no canary insertion, and no reference model training -only the synthetic output and a held-out control set. We demonstrate that this framework effectively functions as a membership inference attack, providing empirical lower bounds on privacy leakage that are tighter than prior data-based auditing methods. Our approach is model-agnostic, applies to any synthetic data generation mechanism, and requires orders of magnitude fewer computational resources than shadow-model or canary-based alternatives.
Self-Boost via Optimal Retraining: An Analysis via Approximate Message Passing
May 21, 2025Retraining a model using its own predictions together with the original, potentially noisy labels is a well-known strategy for improving the model performance. While prior works have demonstrated the benefits of specific heuristic retraining schemes, the question of how to optimally combine the model's predictions and the provided labels remains largely open. This paper addresses this fundamental question for binary classification tasks. We develop a principled framework based on approximate message passing (AMP) to analyze iterative retraining procedures for two ground truth settings: Gaussian mixture model (GMM) and generalized linear model (GLM). Our main contribution is the derivation of the Bayes optimal aggregator function to combine the current model's predictions and the given labels, which when used to retrain the same model, minimizes its prediction error. We also quantify the performance of this optimal retraining strategy over multiple rounds. We complement our theoretical results by proposing a practically usable version of the theoretically-optimal aggregator function for linear probing with the cross-entropy loss, and demonstrate its superiority over baseline methods in the high label noise regime.
Retraining with Predicted Hard Labels Provably Increases Model Accuracy
Jun 17, 2024The performance of a model trained with \textit{noisy labels} is often improved by simply \textit{retraining} the model with its own predicted \textit{hard} labels (i.e., $1$/$0$ labels). Yet, a detailed theoretical characterization of this phenomenon is lacking. In this paper, we theoretically analyze retraining in a linearly separable setting with randomly corrupted labels given to us and prove that retraining can improve the population accuracy obtained by initially training with the given (noisy) labels. To the best of our knowledge, this is the first such theoretical result. Retraining finds application in improving training with label differential privacy (DP) which involves training with noisy labels. We empirically show that retraining selectively on the samples for which the predicted label matches the given label significantly improves label DP training at \textit{no extra privacy cost}; we call this \textit{consensus-based retraining}. For e.g., when training ResNet-18 on CIFAR-100 with $\epsilon=3$ label DP, we obtain $6.4\%$ improvement in accuracy with consensus-based retraining.
Perturb-and-Project: Differentially Private Similarities and Marginals
Jun 07, 2024We revisit the input perturbations framework for differential privacy where noise is added to the input $A\in \mathcal{S}$ and the result is then projected back to the space of admissible datasets $\mathcal{S}$. Through this framework, we first design novel efficient algorithms to privately release pair-wise cosine similarities. Second, we derive a novel algorithm to compute $k$-way marginal queries over $n$ features. Prior work could achieve comparable guarantees only for $k$ even. Furthermore, we extend our results to $t$-sparse datasets, where our efficient algorithms yields novel, stronger guarantees whenever $t\le n^{5/6}/\log n\,.$ Finally, we provide a theoretical perspective on why \textit{fast} input perturbation algorithms works well in practice. The key technical ingredients behind our results are tight sum-of-squares certificates upper bounding the Gaussian complexity of sets of solutions.
A Scalable Algorithm for Individually Fair K-means Clustering
Feb 09, 2024



We present a scalable algorithm for the individually fair ($p$, $k$)-clustering problem introduced by Jung et al. and Mahabadi et al. Given $n$ points $P$ in a metric space, let $\delta(x)$ for $x\in P$ be the radius of the smallest ball around $x$ containing at least $n / k$ points. A clustering is then called individually fair if it has centers within distance $\delta(x)$ of $x$ for each $x\in P$. While good approximation algorithms are known for this problem no efficient practical algorithms with good theoretical guarantees have been presented. We design the first fast local-search algorithm that runs in ~$O(nk^2)$ time and obtains a bicriteria $(O(1), 6)$ approximation. Then we show empirically that not only is our algorithm much faster than prior work, but it also produces lower-cost solutions.
Differentially Private Clustering in Data Streams
Jul 14, 2023The streaming model is an abstraction of computing over massive data streams, which is a popular way of dealing with large-scale modern data analysis. In this model, there is a stream of data points, one after the other. A streaming algorithm is only allowed one pass over the data stream, and the goal is to perform some analysis during the stream while using as small space as possible. Clustering problems (such as $k$-means and $k$-median) are fundamental unsupervised machine learning primitives, and streaming clustering algorithms have been extensively studied in the past. However, since data privacy becomes a central concern in many real-world applications, non-private clustering algorithms are not applicable in many scenarios. In this work, we provide the first differentially private streaming algorithms for $k$-means and $k$-median clustering of $d$-dimensional Euclidean data points over a stream with length at most $T$ using $poly(k,d,\log(T))$ space to achieve a {\it constant} multiplicative error and a $poly(k,d,\log(T))$ additive error. In particular, we present a differentially private streaming clustering framework which only requires an offline DP coreset algorithm as a blackbox. By plugging in existing DP coreset results via Ghazi, Kumar, Manurangsi 2020 and Kaplan, Stemmer 2018, we achieve (1) a $(1+\gamma)$-multiplicative approximation with $\tilde{O}_\gamma(poly(k,d,\log(T)))$ space for any $\gamma>0$, and the additive error is $poly(k,d,\log(T))$ or (2) an $O(1)$-multiplicative approximation with $\tilde{O}(k \cdot poly(d,\log(T)))$ space and $poly(k,d,\log(T))$ additive error. In addition, our algorithmic framework is also differentially private under the continual release setting, i.e., the union of outputs of our algorithms at every timestamp is always differentially private.
Measuring Re-identification Risk
Apr 12, 2023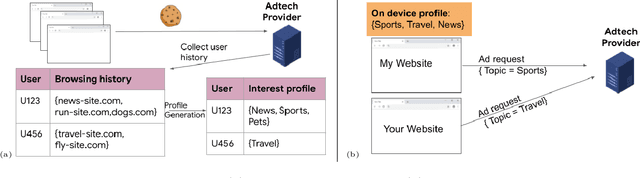
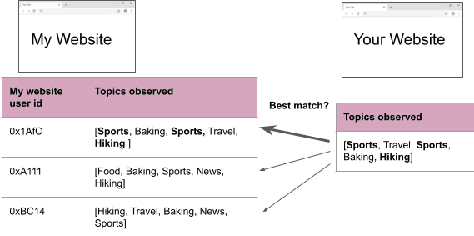
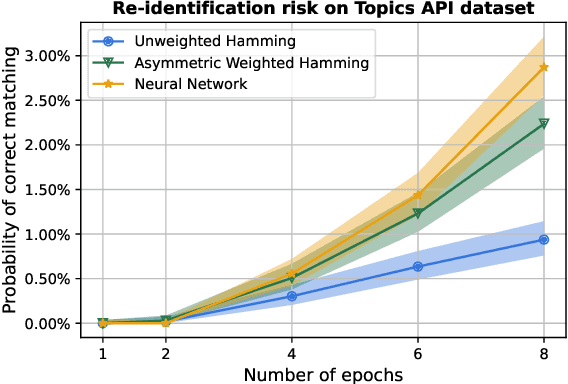
Compact user representations (such as embeddings) form the backbone of personalization services. In this work, we present a new theoretical framework to measure re-identification risk in such user representations. Our framework, based on hypothesis testing, formally bounds the probability that an attacker may be able to obtain the identity of a user from their representation. As an application, we show how our framework is general enough to model important real-world applications such as the Chrome's Topics API for interest-based advertising. We complement our theoretical bounds by showing provably good attack algorithms for re-identification that we use to estimate the re-identification risk in the Topics API. We believe this work provides a rigorous and interpretable notion of re-identification risk and a framework to measure it that can be used to inform real-world applications.
Differentially-Private Hierarchical Clustering with Provable Approximation Guarantees
Jan 31, 2023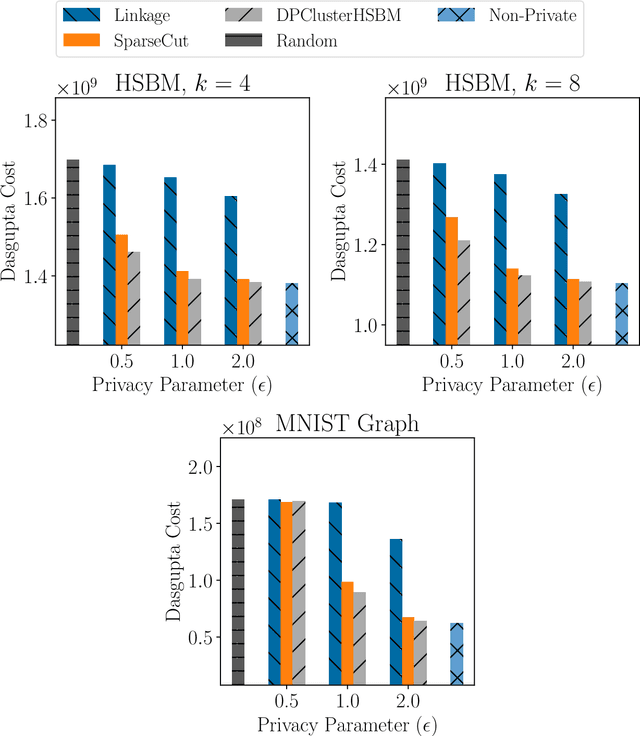
Hierarchical Clustering is a popular unsupervised machine learning method with decades of history and numerous applications. We initiate the study of differentially private approximation algorithms for hierarchical clustering under the rigorous framework introduced by (Dasgupta, 2016). We show strong lower bounds for the problem: that any $\epsilon$-DP algorithm must exhibit $O(|V|^2/ \epsilon)$-additive error for an input dataset $V$. Then, we exhibit a polynomial-time approximation algorithm with $O(|V|^{2.5}/ \epsilon)$-additive error, and an exponential-time algorithm that meets the lower bound. To overcome the lower bound, we focus on the stochastic block model, a popular model of graphs, and, with a separation assumption on the blocks, propose a private $1+o(1)$ approximation algorithm which also recovers the blocks exactly. Finally, we perform an empirical study of our algorithms and validate their performance.
Private estimation algorithms for stochastic block models and mixture models
Jan 11, 2023We introduce general tools for designing efficient private estimation algorithms, in the high-dimensional settings, whose statistical guarantees almost match those of the best known non-private algorithms. To illustrate our techniques, we consider two problems: recovery of stochastic block models and learning mixtures of spherical Gaussians. For the former, we present the first efficient $(\epsilon, \delta)$-differentially private algorithm for both weak recovery and exact recovery. Previously known algorithms achieving comparable guarantees required quasi-polynomial time. For the latter, we design an $(\epsilon, \delta)$-differentially private algorithm that recovers the centers of the $k$-mixture when the minimum separation is at least $ O(k^{1/t}\sqrt{t})$. For all choices of $t$, this algorithm requires sample complexity $n\geq k^{O(1)}d^{O(t)}$ and time complexity $(nd)^{O(t)}$. Prior work required minimum separation at least $O(\sqrt{k})$ as well as an explicit upper bound on the Euclidean norm of the centers.
Differentially Private Graph Learning via Sensitivity-Bounded Personalized PageRank
Jul 14, 2022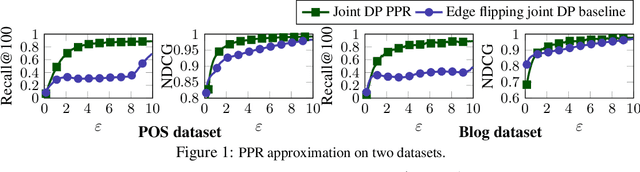
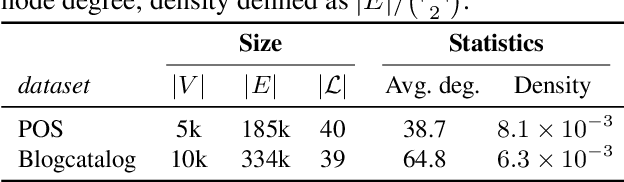
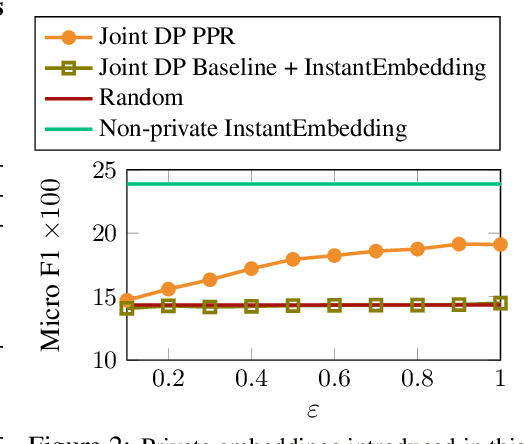
Personalized PageRank (PPR) is a fundamental tool in unsupervised learning of graph representations such as node ranking, labeling, and graph embedding. However, while data privacy is one of the most important recent concerns, existing PPR algorithms are not designed to protect user privacy. PPR is highly sensitive to the input graph edges: the difference of only one edge may cause a big change in the PPR vector, potentially leaking private user data. In this work, we propose an algorithm which outputs an approximate PPR and has provably bounded sensitivity to input edges. In addition, we prove that our algorithm achieves similar accuracy to non-private algorithms when the input graph has large degrees. Our sensitivity-bounded PPR directly implies private algorithms for several tools of graph learning, such as, differentially private (DP) PPR ranking, DP node classification, and DP node embedding. To complement our theoretical analysis, we also empirically verify the practical performances of our algorithms.