 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Anonymity for Sparse Binary Matrices
Paper and Code

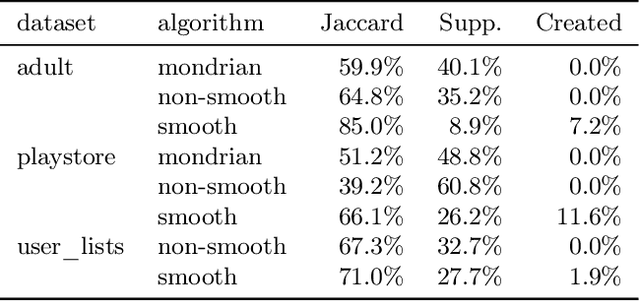
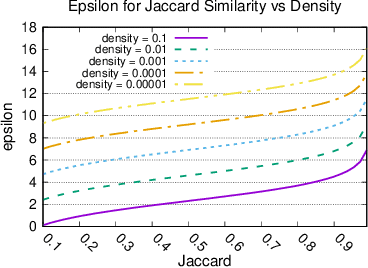
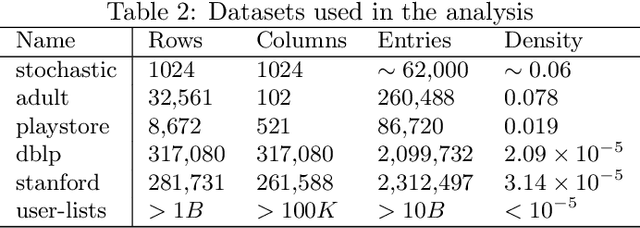
When working with user data providing well-defined privacy guarantees is paramount. In this work we aim to manipulate and share an entire sparse dataset with a third party privately. In fact, differential privacy has emerged as the gold standard of privacy, however, when it comes to sharing sparse datasets, as one of our main results, we prove that \emph{any} differentially private mechanism that maintains a reasonable similarity with the initial dataset is doomed to have a very weak privacy guarantee. Hence we need to opt for other privacy notions such as $k$-anonymity are better at preserving utility in this context. In this work we present a variation of $k$-anonymity, which we call smooth $k$-anonymity and design simple algorithms that efficiently provide smooth $k$-anonymity. We further perform an empirical evaluation to back our theoretical guarantees, and show that our algorithm improves the performance in downstream machine learning tasks on anonymized data.