 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Convergence Benefits of Fewer Data Weight Updates over Longer Horizon
Feb 23, 2026Data mixing--the strategic reweighting of training domains--is a critical component in training robust machine learning models. This problem is naturally formulated as a bilevel optimization task, where the outer loop optimizes domain weights to minimize validation loss, and the inner loop optimizes model parameters to minimize the weighted training loss. Classical bilevel optimization relies on hypergradients, which theoretically require the inner optimization to reach convergence. However, due to computational constraints, state-of-the-art methods use a finite, often small, number of inner update steps before updating the weights. The theoretical implications of this approximation are not well understood. In this work, we rigorously analyze the convergence behavior of data mixing with a finite number of inner steps $T$. We prove that the "greedy" practical approach of using $T=1$ can fail even in a simple quadratic example. Under a fixed parameter update budget $N$ and assuming the per-domain losses are strongly convex, we show that the optimal $T$ scales as $Θ(\log N)$ (resp., $Θ({(N \log N)}^{1/2})$) for the data mixing problem with access to full (resp., stochastic) gradients. We complement our theoretical results with proof-of-concept experiments.
Self-Boost via Optimal Retraining: An Analysis via Approximate Message Passing
May 21, 2025Retraining a model using its own predictions together with the original, potentially noisy labels is a well-known strategy for improving the model performance. While prior works have demonstrated the benefits of specific heuristic retraining schemes, the question of how to optimally combine the model's predictions and the provided labels remains largely open. This paper addresses this fundamental question for binary classification tasks. We develop a principled framework based on approximate message passing (AMP) to analyze iterative retraining procedures for two ground truth settings: Gaussian mixture model (GMM) and generalized linear model (GLM). Our main contribution is the derivation of the Bayes optimal aggregator function to combine the current model's predictions and the given labels, which when used to retrain the same model, minimizes its prediction error. We also quantify the performance of this optimal retraining strategy over multiple rounds. We complement our theoretical results by proposing a practically usable version of the theoretically-optimal aggregator function for linear probing with the cross-entropy loss, and demonstrate its superiority over baseline methods in the high label noise regime.
Upweighting Easy Samples in Fine-Tuning Mitigates Forgetting
Feb 05, 2025Fine-tuning a pre-trained model on a downstream task often degrades its original capabilities, a phenomenon known as "catastrophic forgetting". This is especially an issue when one does not have access to the data and recipe used to develop the pre-trained model. Under this constraint, most existing methods for mitigating forgetting are inapplicable. To address this challenge, we propose a sample weighting scheme for the fine-tuning data solely based on the pre-trained model's losses. Specifically, we upweight the easy samples on which the pre-trained model's loss is low and vice versa to limit the drift from the pre-trained model. Our approach is orthogonal and yet complementary to existing methods; while such methods mostly operate on parameter or gradient space, we concentrate on the sample space. We theoretically analyze the impact of fine-tuning with our method in a linear setting, showing that it stalls learning in a certain subspace which inhibits overfitting to the target task. We empirically demonstrate the efficacy of our method on both language and vision tasks. As an example, when fine-tuning Gemma 2 2B on MetaMathQA, our method results in only a $0.8\%$ drop in accuracy on GSM8K (another math dataset) compared to standard fine-tuning, while preserving $5.4\%$ more accuracy on the pre-training datasets. Our code is publicly available at https://github.com/sanyalsunny111/FLOW_finetuning .
Retraining with Predicted Hard Labels Provably Increases Model Accuracy
Jun 17, 2024The performance of a model trained with \textit{noisy labels} is often improved by simply \textit{retraining} the model with its own predicted \textit{hard} labels (i.e., $1$/$0$ labels). Yet, a detailed theoretical characterization of this phenomenon is lacking. In this paper, we theoretically analyze retraining in a linearly separable setting with randomly corrupted labels given to us and prove that retraining can improve the population accuracy obtained by initially training with the given (noisy) labels. To the best of our knowledge, this is the first such theoretical result. Retraining finds application in improving training with label differential privacy (DP) which involves training with noisy labels. We empirically show that retraining selectively on the samples for which the predicted label matches the given label significantly improves label DP training at \textit{no extra privacy cost}; we call this \textit{consensus-based retraining}. For e.g., when training ResNet-18 on CIFAR-100 with $\epsilon=3$ label DP, we obtain $6.4\%$ improvement in accuracy with consensus-based retraining.
Towards Quantifying the Preconditioning Effect of Adam
Feb 11, 2024There is a notable dearth of results characterizing the preconditioning effect of Adam and showing how it may alleviate the curse of ill-conditioning -- an issue plaguing gradient descent (GD). In this work, we perform a detailed analysis of Adam's preconditioning effect for quadratic functions and quantify to what extent Adam can mitigate the dependence on the condition number of the Hessian. Our key finding is that Adam can suffer less from the condition number but at the expense of suffering a dimension-dependent quantity. Specifically, for a $d$-dimensional quadratic with a diagonal Hessian having condition number $\kappa$, we show that the effective condition number-like quantity controlling the iteration complexity of Adam without momentum is $\mathcal{O}(\min(d, \kappa))$. For a diagonally dominant Hessian, we obtain a bound of $\mathcal{O}(\min(d \sqrt{d \kappa}, \kappa))$ for the corresponding quantity. Thus, when $d < \mathcal{O}(\kappa^p)$ where $p = 1$ for a diagonal Hessian and $p = 1/3$ for a diagonally dominant Hessian, Adam can outperform GD (which has an $\mathcal{O}(\kappa)$ dependence). On the negative side, our results suggest that Adam can be worse than GD for a sufficiently non-diagonal Hessian even if $d \ll \mathcal{O}(\kappa^{1/3})$; we corroborate this with empirical evidence. Finally, we extend our analysis to functions satisfying per-coordinate Lipschitz smoothness and a modified version of the Polyak-\L ojasiewicz condition.
Understanding the Training Speedup from Sampling with Approximate Losses
Feb 10, 2024It is well known that selecting samples with large losses/gradients can significantly reduce the number of training steps. However, the selection overhead is often too high to yield any meaningful gains in terms of overall training time. In this work, we focus on the greedy approach of selecting samples with large \textit{approximate losses} instead of exact losses in order to reduce the selection overhead. For smooth convex losses, we show that such a greedy strategy can converge to a constant factor of the minimum value of the average loss in fewer iterations than the standard approach of random selection. We also theoretically quantify the effect of the approximation level. We then develop SIFT which uses early exiting to obtain approximate losses with an intermediate layer's representations for sample selection. We evaluate SIFT on the task of training a 110M parameter 12-layer BERT base model and show significant gains (in terms of training hours and number of backpropagation steps) without any optimized implementation over vanilla training. For e.g., to reach 64% validation accuracy, SIFT with exit at the first layer takes ~43 hours compared to ~57 hours of vanilla training.
Understanding Self-Distillation in the Presence of Label Noise
Jan 30, 2023



Self-distillation (SD) is the process of first training a \enquote{teacher} model and then using its predictions to train a \enquote{student} model with the \textit{same} architecture. Specifically, the student's objective function is $\big(\xi*\ell(\text{teacher's predictions}, \text{ student's predictions}) + (1-\xi)*\ell(\text{given labels}, \text{ student's predictions})\big)$, where $\ell$ is some loss function and $\xi$ is some parameter $\in [0,1]$. Empirically, SD has been observed to provide performance gains in several settings. In this paper, we theoretically characterize the effect of SD in two supervised learning problems with \textit{noisy labels}. We first analyze SD for regularized linear regression and show that in the high label noise regime, the optimal value of $\xi$ that minimizes the expected error in estimating the ground truth parameter is surprisingly greater than 1. Empirically, we show that $\xi > 1$ works better than $\xi \leq 1$ even with the cross-entropy loss for several classification datasets when 50\% or 30\% of the labels are corrupted. Further, we quantify when optimal SD is better than optimal regularization. Next, we analyze SD in the case of logistic regression for binary classification with random label corruption and quantify the range of label corruption in which the student outperforms the teacher in terms of accuracy. To our knowledge, this is the first result of its kind for the cross-entropy loss.
Beyond Uniform Lipschitz Condition in Differentially Private Optimization
Jun 21, 2022
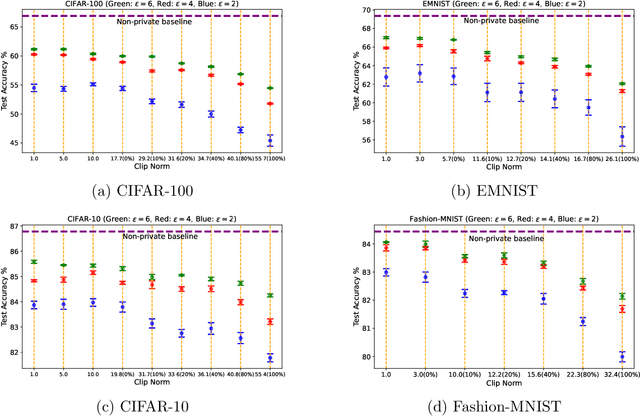

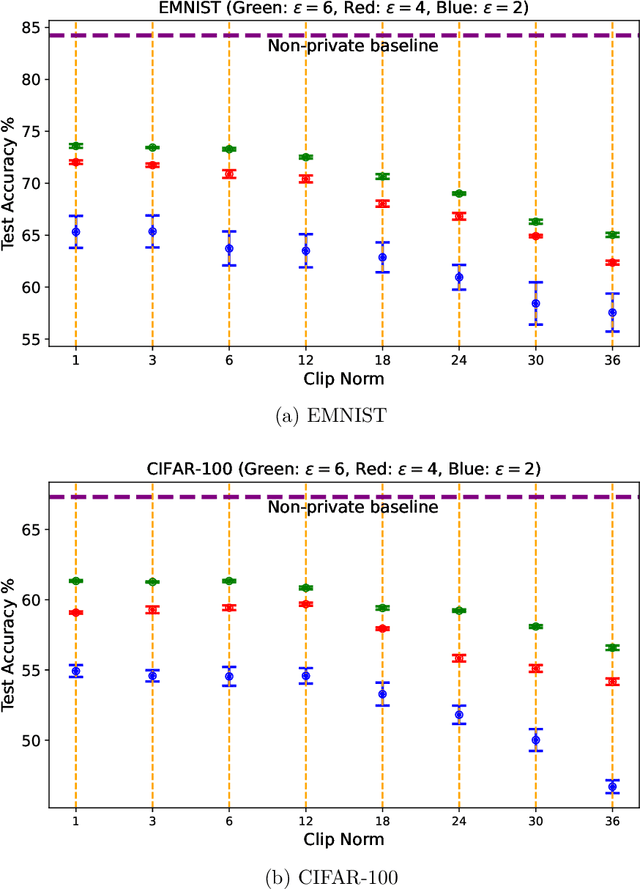
Most prior convergence results on differentially private stochastic gradient descent (DP-SGD) are derived under the simplistic assumption of uniform Lipschitzness, i.e., the per-sample gradients are uniformly bounded. This assumption is unrealistic in many problems, e.g., linear regression with Gaussian data. We relax uniform Lipschitzness by instead assuming that the per-sample gradients have \textit{sample-dependent} upper bounds, i.e., per-sample Lipschitz constants, which themselves may be unbounded. We derive new convergence results for DP-SGD on both convex and nonconvex functions when the per-sample Lipschitz constants have bounded moments. Furthermore, we provide principled guidance on choosing the clip norm in DP-SGD for convex settings satisfying our relaxed version of Lipschitzness, without making distributional assumptions on the Lipschitz constants. We verify the effectiveness of our recommendation via experiments on benchmarking datasets.
On the Unreasonable Effectiveness of Federated Averaging with Heterogeneous Data
Jun 09, 2022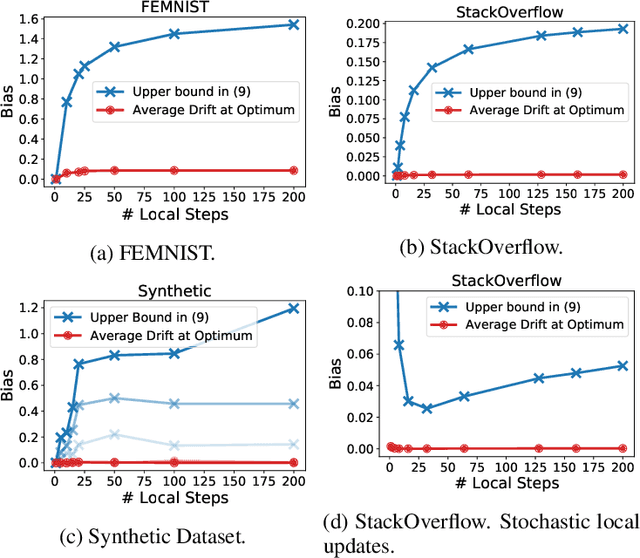
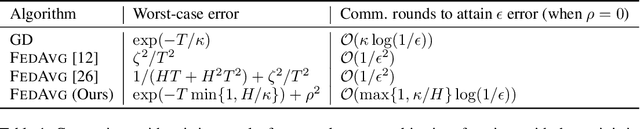
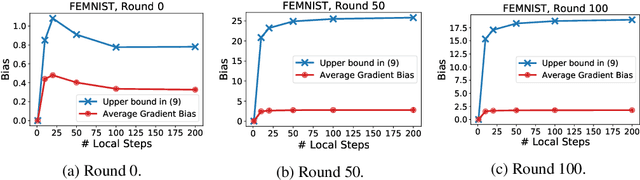
Existing theory predicts that data heterogeneity will degrade the performance of the Federated Averaging (FedAvg) algorithm in federated learning. However, in practice, the simple FedAvg algorithm converges very well. This paper explains the seemingly unreasonable effectiveness of FedAvg that contradicts the previous theoretical predictions. We find that the key assumption of bounded gradient dissimilarity in previous theoretical analyses is too pessimistic to characterize data heterogeneity in practical applications. For a simple quadratic problem, we demonstrate there exist regimes where large gradient dissimilarity does not have any negative impact on the convergence of FedAvg. Motivated by this observation, we propose a new quantity, average drift at optimum, to measure the effects of data heterogeneity, and explicitly use it to present a new theoretical analysis of FedAvg. We show that the average drift at optimum is nearly zero across many real-world federated training tasks, whereas the gradient dissimilarity can be large. And our new analysis suggests FedAvg can have identical convergence rates in homogeneous and heterogeneous data settings, and hence, leads to better understanding of its empirical success.
DISCO : efficient unsupervised decoding for discrete natural language problems via convex relaxation
Jul 13, 2021
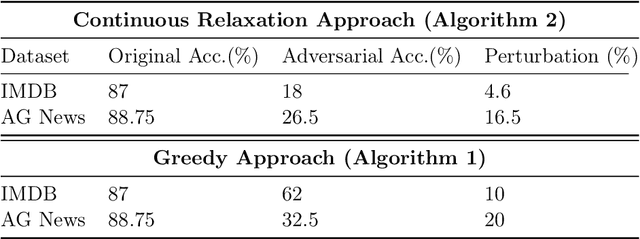
In this paper we study test time decoding; an ubiquitous step in almost all sequential text generation task spanning across a wide array of natural language processing (NLP) problems. Our main contribution is to develop a continuous relaxation framework for the combinatorial NP-hard decoding problem and propose Disco - an efficient algorithm based on standard first order gradient based. We provide tight analysis and show that our proposed algorithm linearly converges to within $\epsilon$ neighborhood of the optima. Finally, we perform preliminary experiments on the task of adversarial text generation and show superior performance of Disco over several popular decoding approaches.