 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Free Synthetic Data Mitigates Forgetting
May 20, 2025Fine-tuning a language model often results in a degradation of its existing performance on other tasks, due to a shift in the model parameters; this phenomenon is often referred to as (catastrophic) forgetting. We are interested in mitigating this, in settings where we only have access to the model weights but no access to its training data/recipe. A natural approach is to penalize the KL divergence between the original model and the new one. Our main realization is that a simple process - which we term context-free generation - allows for an approximate unbiased estimation of this KL divergence. We show that augmenting a fine-tuning dataset with context-free generations mitigates forgetting, in two settings: (a) preserving the zero-shot performance of pretrained-only models, and (b) preserving the reasoning performance of thinking models. We show that contextual synthetic data, and even a portion of the pretraining data, are less effective. We also investigate the effect of choices like generation temperature, data ratios etc. We present our results for OLMo-1B for pretrained-only setting and R1-Distill-Llama-8B for the reasoning setting.
Understanding the Training Speedup from Sampling with Approximate Losses
Feb 10, 2024It is well known that selecting samples with large losses/gradients can significantly reduce the number of training steps. However, the selection overhead is often too high to yield any meaningful gains in terms of overall training time. In this work, we focus on the greedy approach of selecting samples with large \textit{approximate losses} instead of exact losses in order to reduce the selection overhead. For smooth convex losses, we show that such a greedy strategy can converge to a constant factor of the minimum value of the average loss in fewer iterations than the standard approach of random selection. We also theoretically quantify the effect of the approximation level. We then develop SIFT which uses early exiting to obtain approximate losses with an intermediate layer's representations for sample selection. We evaluate SIFT on the task of training a 110M parameter 12-layer BERT base model and show significant gains (in terms of training hours and number of backpropagation steps) without any optimized implementation over vanilla training. For e.g., to reach 64% validation accuracy, SIFT with exit at the first layer takes ~43 hours compared to ~57 hours of vanilla training.
Large Language Models as Annotators: Enhancing Generalization of NLP Models at Minimal Cost
Jun 27, 2023State-of-the-art supervised NLP models achieve high accuracy but are also susceptible to failures on inputs from low-data regimes, such as domains that are not represented in training data. As an approximation to collecting ground-truth labels for the specific domain, we study the use of large language models (LLMs) for annotating inputs and improving the generalization of NLP models. Specifically, given a budget for LLM annotations, we present an algorithm for sampling the most informative inputs to annotate and retrain the NLP model. We find that popular active learning strategies such as uncertainty-based sampling do not work well. Instead, we propose a sampling strategy based on the difference in prediction scores between the base model and the finetuned NLP model, utilizing the fact that most NLP models are finetuned from a base model. Experiments with classification (semantic similarity) and ranking (semantic search) tasks show that our sampling strategy leads to significant gains in accuracy for both the training and target domains.
Controlling Learned Effects to Reduce Spurious Correlations in Text Classifiers
May 26, 2023To address the problem of NLP classifiers learning spurious correlations between training features and target labels, a common approach is to make the model's predictions invariant to these features. However, this can be counter-productive when the features have a non-zero causal effect on the target label and thus are important for prediction. Therefore, using methods from the causal inference literature, we propose an algorithm to regularize the learnt effect of the features on the model's prediction to the estimated effect of feature on label. This results in an automated augmentation method that leverages the estimated effect of a feature to appropriately change the labels for new augmented inputs. On toxicity and IMDB review datasets, the proposed algorithm minimises spurious correlations and improves the minority group (i.e., samples breaking spurious correlations) accuracy, while also improving the total accuracy compared to standard training.
Missing Value Imputation on Multidimensional Time Series
Mar 02, 2021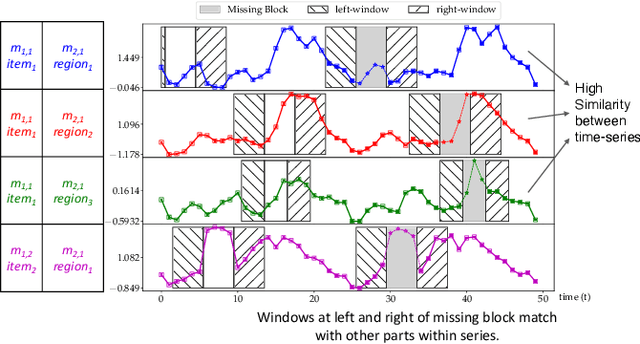
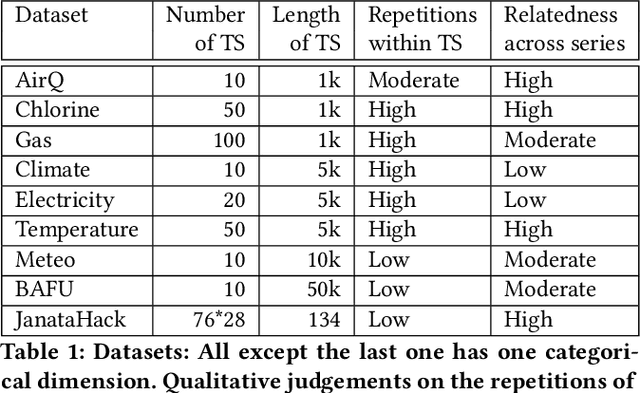
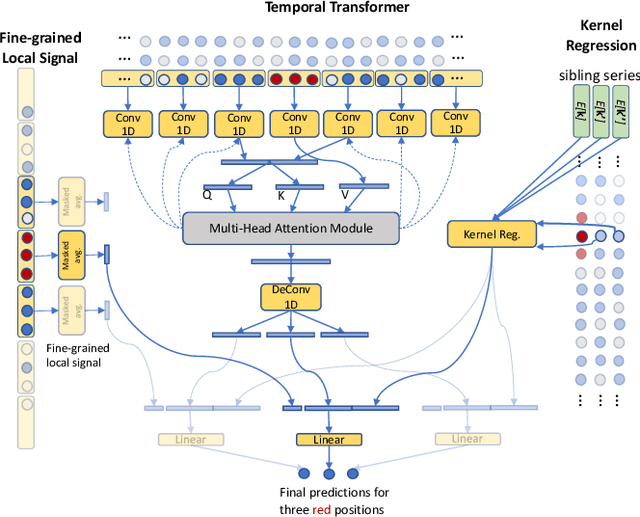

We present DeepMVI, a deep learning method for missing value imputation in multidimensional time-series datasets. Missing values are commonplace in decision support platforms that aggregate data over long time stretches from disparate sources, and reliable data analytics calls for careful handling of missing data. One strategy is imputing the missing values, and a wide variety of algorithms exist spanning simple interpolation, matrix factorization methods like SVD, statistical models like Kalman filters, and recent deep learning methods. We show that often these provide worse results on aggregate analytics compared to just excluding the missing data. DeepMVI uses a neural network to combine fine-grained and coarse-grained patterns along a time series, and trends from related series across categorical dimensions. After failing with off-the-shelf neural architectures, we design our own network that includes a temporal transformer with a novel convolutional window feature, and kernel regression with learned embeddings. The parameters and their training are designed carefully to generalize across different placements of missing blocks and data characteristics. Experiments across nine real datasets, four different missing scenarios, comparing seven existing methods show that DeepMVI is significantly more accurate, reducing error by more than 50% in more than half the cases, compared to the best existing method. Although slower than simpler matrix factorization methods, we justify the increased time overheads by showing that DeepMVI is the only option that provided overall more accurate analytics than dropping missing values.