 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Probabilistic Forecasting in Time-Series using High Order Statistics
Nov 05, 2021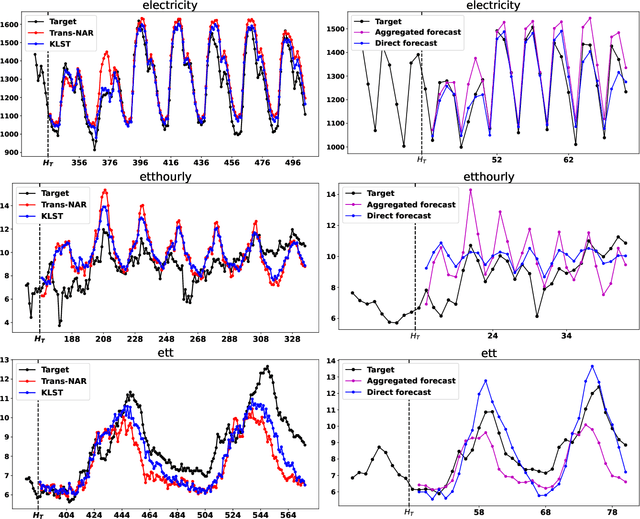


Long range forecasts are the starting point of many decision support systems that need to draw inference from high-level aggregate patterns on forecasted values. State of the art time-series forecasting methods are either subject to concept drift on long-horizon forecasts, or fail to accurately predict coherent and accurate high-level aggregates. In this work, we present a novel probabilistic forecasting method that produces forecasts that are coherent in terms of base level and predicted aggregate statistics. We achieve the coherency between predicted base-level and aggregate statistics using a novel inference method. Our inference method is based on KL-divergence and can be solved efficiently in closed form. We show that our method improves forecast performance across both base level and unseen aggregates post inference on real datasets ranging three diverse domains.
Missing Value Imputation on Multidimensional Time Series
Mar 02, 2021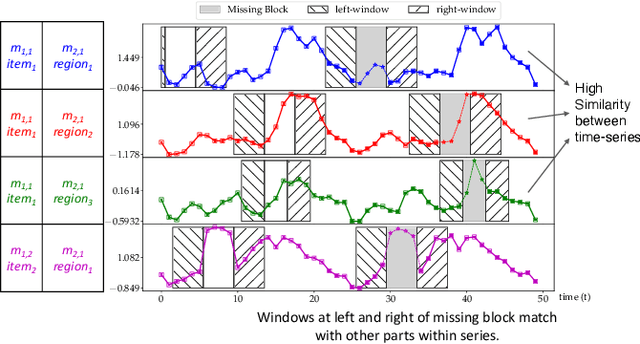
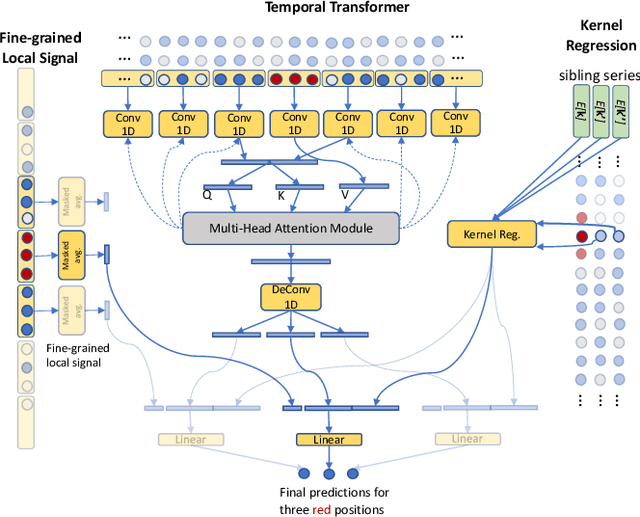

We present DeepMVI, a deep learning method for missing value imputation in multidimensional time-series datasets. Missing values are commonplace in decision support platforms that aggregate data over long time stretches from disparate sources, and reliable data analytics calls for careful handling of missing data. One strategy is imputing the missing values, and a wide variety of algorithms exist spanning simple interpolation, matrix factorization methods like SVD, statistical models like Kalman filters, and recent deep learning methods. We show that often these provide worse results on aggregate analytics compared to just excluding the missing data. DeepMVI uses a neural network to combine fine-grained and coarse-grained patterns along a time series, and trends from related series across categorical dimensions. After failing with off-the-shelf neural architectures, we design our own network that includes a temporal transformer with a novel convolutional window feature, and kernel regression with learned embeddings. The parameters and their training are designed carefully to generalize across different placements of missing blocks and data characteristics. Experiments across nine real datasets, four different missing scenarios, comparing seven existing methods show that DeepMVI is significantly more accurate, reducing error by more than 50% in more than half the cases, compared to the best existing method. Although slower than simpler matrix factorization methods, we justify the increased time overheads by showing that DeepMVI is the only option that provided overall more accurate analytics than dropping missing values.
Long Horizon Forecasting With Temporal Point Processes
Jan 08, 2021

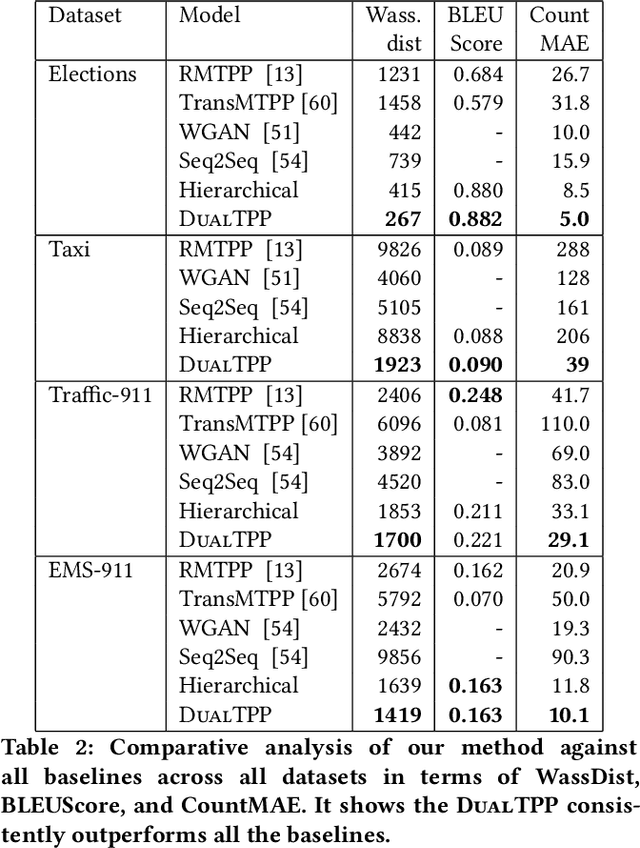
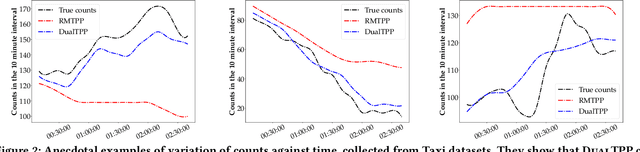
In recent years, marked temporal point processes (MTPPs) have emerged as a powerful modeling machinery to characterize asynchronous events in a wide variety of applications. MTPPs have demonstrated significant potential in predicting event-timings, especially for events arriving in near future. However, due to current design choices, MTPPs often show poor predictive performance at forecasting event arrivals in distant future. To ameliorate this limitation, in this paper, we design DualTPP which is specifically well-suited to long horizon event forecasting. DualTPP has two components. The first component is an intensity free MTPP model, which captures microscopic or granular level signals of the event dynamics by modeling the time of future events. The second component takes a different dual perspective of modeling aggregated counts of events in a given time-window, thus encapsulating macroscopic event dynamics. Then we develop a novel inference framework jointly over the two models % for efficiently forecasting long horizon events by solving a sequence of constrained quadratic optimization problems. Experiments with a diverse set of real datasets show that DualTPP outperforms existing MTPP methods on long horizon forecasting by substantial margins, achieving almost an order of magnitude reduction in Wasserstein distance between actual events and forecasts.
Streaming Adaptation of Deep Forecasting Models using Adaptive Recurrent Units
Jul 04, 2019

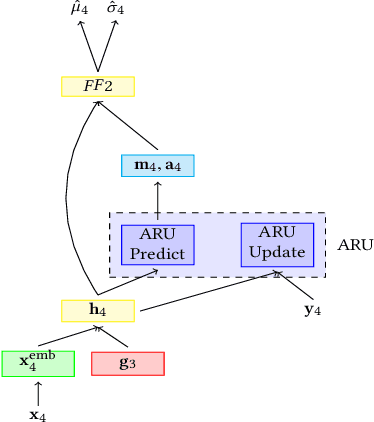

We present ARU, an Adaptive Recurrent Unit for streaming adaptation of deep globally trained time-series forecasting models. The ARU combines the advantages of learning complex data transformations across multiple time series from deep global models, with per-series localization offered by closed-form linear models. Unlike existing methods of adaptation that are either memory-intensive or non-responsive after training, ARUs require only fixed sized state and adapt to streaming data via an easy RNN-like update operation. The core principle driving ARU is simple --- maintain sufficient statistics of conditional Gaussian distributions and use them to compute local parameters in closed form. Our contribution is in embedding such local linear models in globally trained deep models while allowing end-to-end training on the one hand, and easy RNN-like updates on the other. Across several datasets we show that ARU is more effective than recently proposed local adaptation methods that tax the global network to compute local parameters.