 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMissing Value Imputation on Multidimensional Time Series
Paper and Code
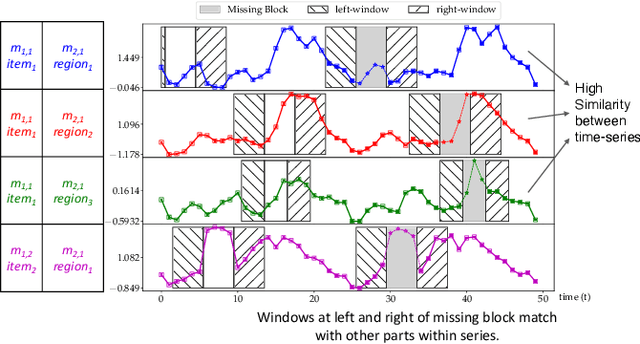
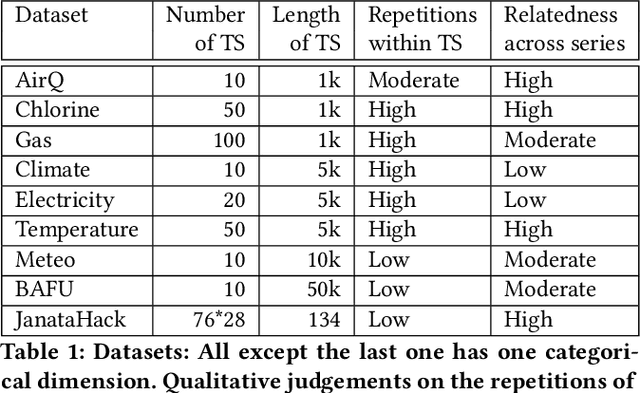
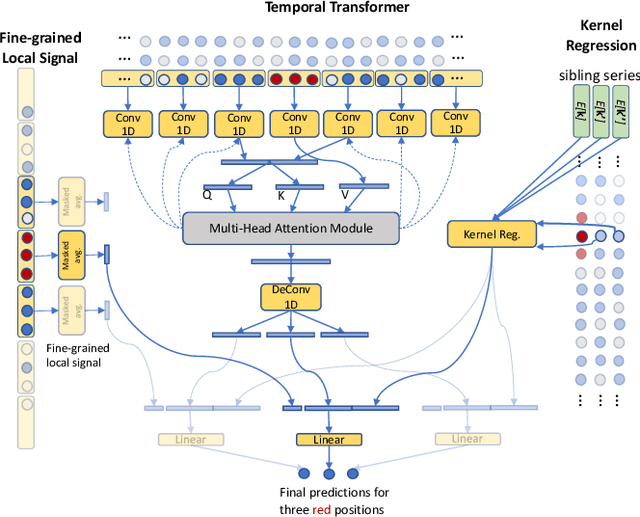

We present DeepMVI, a deep learning method for missing value imputation in multidimensional time-series datasets. Missing values are commonplace in decision support platforms that aggregate data over long time stretches from disparate sources, and reliable data analytics calls for careful handling of missing data. One strategy is imputing the missing values, and a wide variety of algorithms exist spanning simple interpolation, matrix factorization methods like SVD, statistical models like Kalman filters, and recent deep learning methods. We show that often these provide worse results on aggregate analytics compared to just excluding the missing data. DeepMVI uses a neural network to combine fine-grained and coarse-grained patterns along a time series, and trends from related series across categorical dimensions. After failing with off-the-shelf neural architectures, we design our own network that includes a temporal transformer with a novel convolutional window feature, and kernel regression with learned embeddings. The parameters and their training are designed carefully to generalize across different placements of missing blocks and data characteristics. Experiments across nine real datasets, four different missing scenarios, comparing seven existing methods show that DeepMVI is significantly more accurate, reducing error by more than 50% in more than half the cases, compared to the best existing method. Although slower than simpler matrix factorization methods, we justify the increased time overheads by showing that DeepMVI is the only option that provided overall more accurate analytics than dropping missing values.