 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Unreasonable Effectiveness of Federated Averaging with Heterogeneous Data
Paper and Code
Jun 09, 2022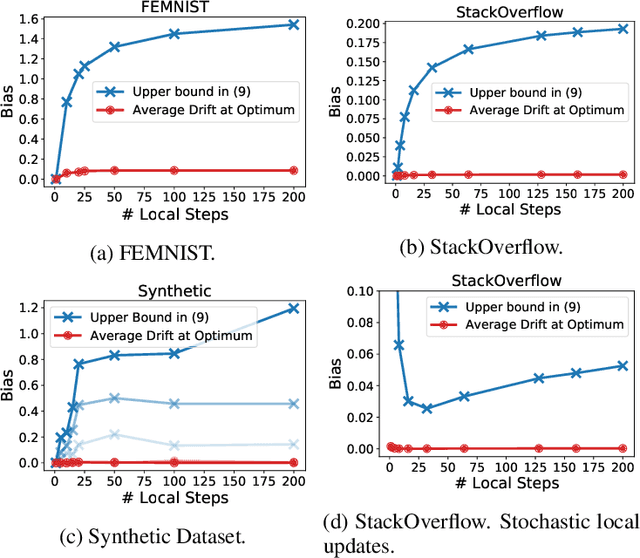
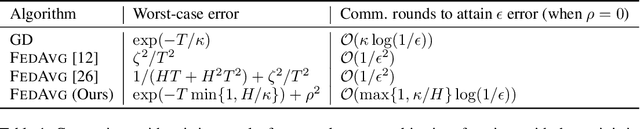
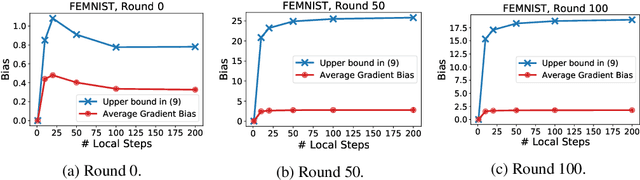
Existing theory predicts that data heterogeneity will degrade the performance of the Federated Averaging (FedAvg) algorithm in federated learning. However, in practice, the simple FedAvg algorithm converges very well. This paper explains the seemingly unreasonable effectiveness of FedAvg that contradicts the previous theoretical predictions. We find that the key assumption of bounded gradient dissimilarity in previous theoretical analyses is too pessimistic to characterize data heterogeneity in practical applications. For a simple quadratic problem, we demonstrate there exist regimes where large gradient dissimilarity does not have any negative impact on the convergence of FedAvg. Motivated by this observation, we propose a new quantity, average drift at optimum, to measure the effects of data heterogeneity, and explicitly use it to present a new theoretical analysis of FedAvg. We show that the average drift at optimum is nearly zero across many real-world federated training tasks, whereas the gradient dissimilarity can be large. And our new analysis suggests FedAvg can have identical convergence rates in homogeneous and heterogeneous data settings, and hence, leads to better understanding of its empirical success.