 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Median Matching for Robust k-Subset Selection from Noisy Data
Apr 03, 2025Data pruning -- the combinatorial task of selecting a small and representative subset from a large dataset, is crucial for mitigating the enormous computational costs associated with training data-hungry modern deep learning models at scale. Since large scale data collections are invariably noisy, developing data pruning strategies that remain robust even in the presence of corruption is critical in practice. However, existing data pruning methods often fail under high corruption rates due to their reliance on empirical mean estimation, which is highly sensitive to outliers. In response, we propose Geometric Median (GM) Matching, a novel k-subset selection strategy that leverages Geometric Median -- a robust estimator with an optimal breakdown point of 1/2; to enhance resilience against noisy data. Our method iteratively selects a k-subset such that the mean of the subset approximates the GM of the (potentially) noisy dataset, ensuring robustness even under arbitrary corruption. We provide theoretical guarantees, showing that GM Matching enjoys an improved O(1/k) convergence rate -- a quadratic improvement over random sampling, even under arbitrary corruption. Extensive experiments across image classification and image generation tasks demonstrate that GM Matching consistently outperforms existing pruning approaches, particularly in high-corruption settings and at high pruning rates; making it a strong baseline for robust data pruning.
Geometric Median (GM) Matching for Robust Data Pruning
Jun 25, 2024Data pruning, the combinatorial task of selecting a small and informative subset from a large dataset, is crucial for mitigating the enormous computational costs associated with training data-hungry modern deep learning models at scale. Since large-scale data collections are invariably noisy, developing data pruning strategies that remain robust even in the presence of corruption is critical in practice. Unfortunately, the existing heuristics for (robust) data pruning lack theoretical coherence and rely on heroic assumptions, that are, often unattainable, by the very nature of the problem setting. Moreover, these strategies often yield sub-optimal neural scaling laws even compared to random sampling, especially in scenarios involving strong corruption and aggressive pruning rates -- making provably robust data pruning an open challenge. In response, in this work, we propose Geometric Median ($\gm$) Matching -- a herding~\citep{welling2009herding} style greedy algorithm -- that yields a $k$-subset such that the mean of the subset approximates the geometric median of the (potentially) noisy dataset. Theoretically, we show that $\gm$ Matching enjoys an improved $\gO(1/k)$ scaling over $\gO(1/\sqrt{k})$ scaling of uniform sampling; while achieving the optimal breakdown point of 1/2 even under arbitrary corruption. Extensive experiments across popular deep learning benchmarks indicate that $\gm$ Matching consistently outperforms prior state-of-the-art; the gains become more profound at high rates of corruption and aggressive pruning rates; making $\gm$ Matching a strong baseline for future research in robust data pruning.
Contrastive Approach to Prior Free Positive Unlabeled Learning
Feb 08, 2024Positive Unlabeled (PU) learning refers to the task of learning a binary classifier given a few labeled positive samples, and a set of unlabeled samples (which could be positive or negative). In this paper, we propose a novel PU learning framework, that starts by learning a feature space through pretext-invariant representation learning and then applies pseudo-labeling to the unlabeled examples, leveraging the concentration property of the embeddings. Overall, our proposed approach handily outperforms state-of-the-art PU learning methods across several standard PU benchmark datasets, while not requiring a-priori knowledge or estimate of class prior. Remarkably, our method remains effective even when labeled data is scant, where most PU learning algorithms falter. We also provide simple theoretical analysis motivating our proposed algorithms and establish generalization guarantee for our approach.
Positive Unlabeled Contrastive Learning
Jun 01, 2022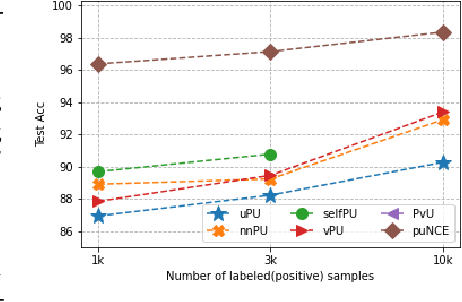
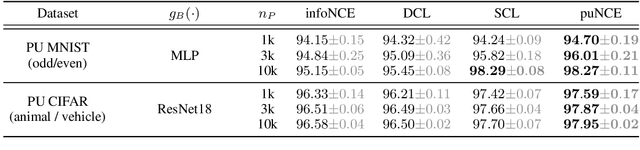
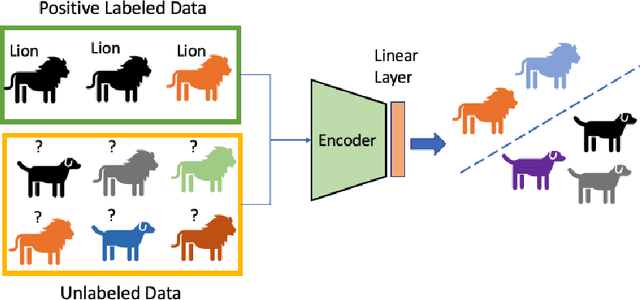
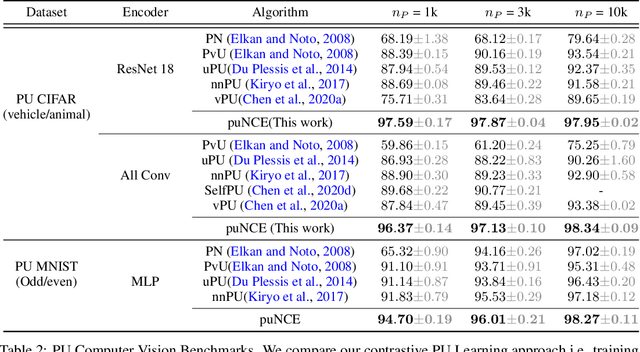
Self-supervised pretraining on unlabeled data followed by supervised finetuning on labeled data is a popular paradigm for learning from limited labeled examples. In this paper, we investigate and extend this paradigm to the classical positive unlabeled (PU) setting - the weakly supervised task of learning a binary classifier only using a few labeled positive examples and a set of unlabeled samples. We propose a novel PU learning objective positive unlabeled Noise Contrastive Estimation (puNCE) that leverages the available explicit (from labeled samples) and implicit (from unlabeled samples) supervision to learn useful representations from positive unlabeled input data. The underlying idea is to assign each training sample an individual weight; labeled positives are given unit weight; unlabeled samples are duplicated, one copy is labeled positive and the other as negative with weights $\pi$ and $(1-\pi)$ where $\pi$ denotes the class prior. Extensive experiments across vision and natural language tasks reveal that puNCE consistently improves over existing unsupervised and supervised contrastive baselines under limited supervision.
LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022
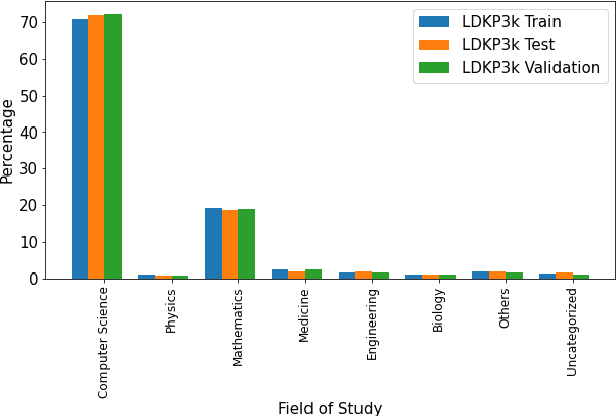
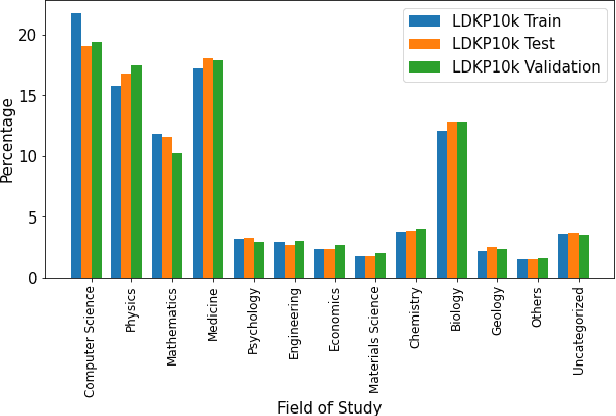

Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.
DISCO : efficient unsupervised decoding for discrete natural language problems via convex relaxation
Jul 13, 2021
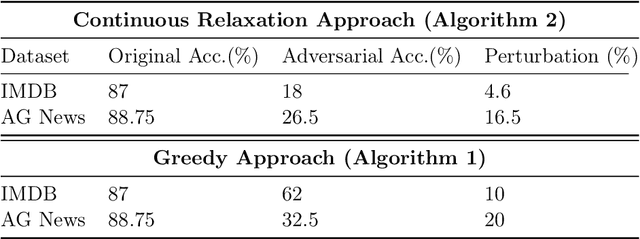
In this paper we study test time decoding; an ubiquitous step in almost all sequential text generation task spanning across a wide array of natural language processing (NLP) problems. Our main contribution is to develop a continuous relaxation framework for the combinatorial NP-hard decoding problem and propose Disco - an efficient algorithm based on standard first order gradient based. We provide tight analysis and show that our proposed algorithm linearly converges to within $\epsilon$ neighborhood of the optima. Finally, we perform preliminary experiments on the task of adversarial text generation and show superior performance of Disco over several popular decoding approaches.
Robust Training in High Dimensions via Block Coordinate Geometric Median Descent
Jun 16, 2021



Geometric median (\textsc{Gm}) is a classical method in statistics for achieving a robust estimation of the uncorrupted data; under gross corruption, it achieves the optimal breakdown point of 0.5. However, its computational complexity makes it infeasible for robustifying stochastic gradient descent (SGD) for high-dimensional optimization problems. In this paper, we show that by applying \textsc{Gm} to only a judiciously chosen block of coordinates at a time and using a memory mechanism, one can retain the breakdown point of 0.5 for smooth non-convex problems, with non-asymptotic convergence rates comparable to the SGD with \textsc{Gm}.
Neural Distributed Source Coding
Jun 05, 2021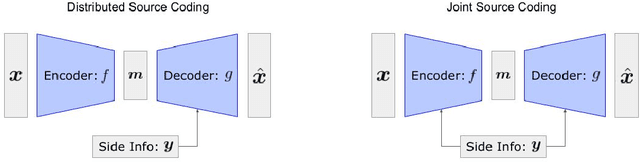
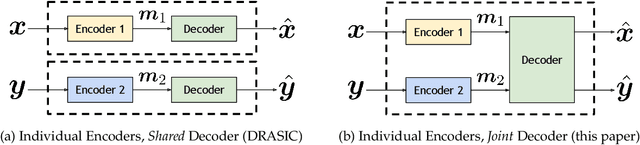


Distributed source coding is the task of encoding an input in the absence of correlated side information that is only available to the decoder. Remarkably, Slepian and Wolf showed in 1973 that an encoder that has no access to the correlated side information can asymptotically achieve the same compression rate as when the side information is available at both the encoder and the decoder. While there is significant prior work on this topic in information theory, practical distributed source coding has been limited to synthetic datasets and specific correlation structures. Here we present a general framework for lossy distributed source coding that is agnostic to the correlation structure and can scale to high dimensions. Rather than relying on hand-crafted source-modeling, our method utilizes a powerful conditional deep generative model to learn the distributed encoder and decoder. We evaluate our method on realistic high-dimensional datasets and show substantial improvements in distributed compression performance.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
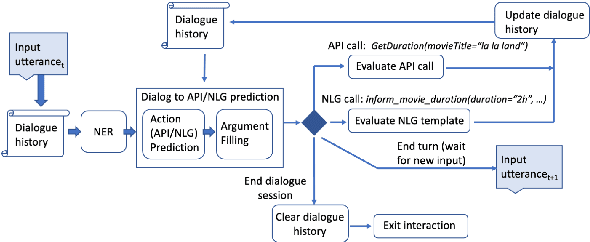

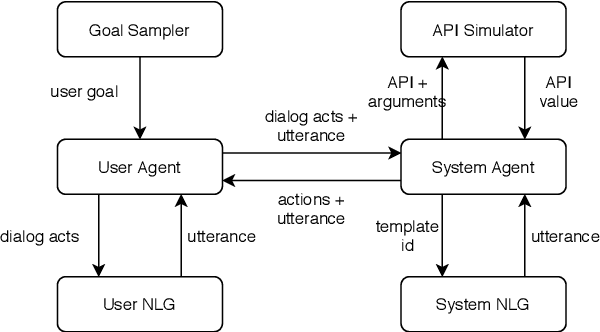
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021



Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset