 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022
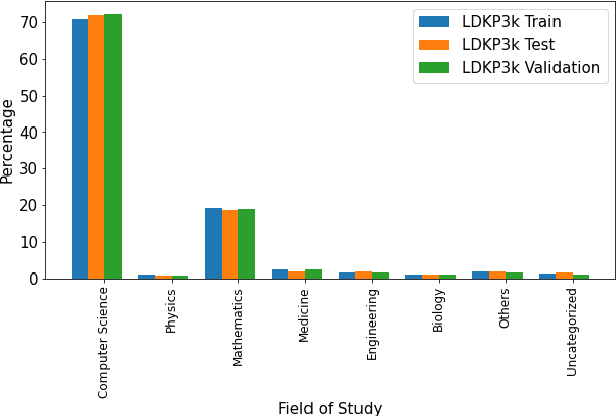
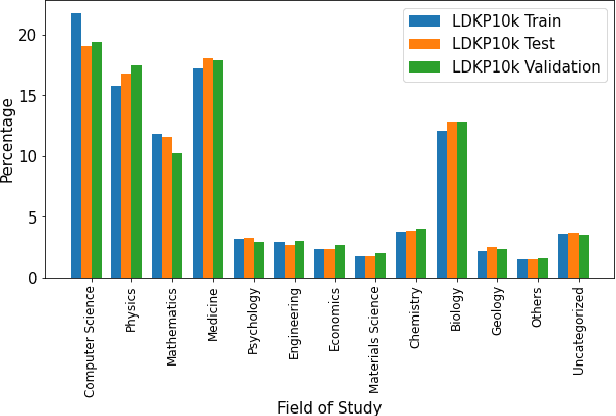

Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.