 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding
Nov 07, 2024
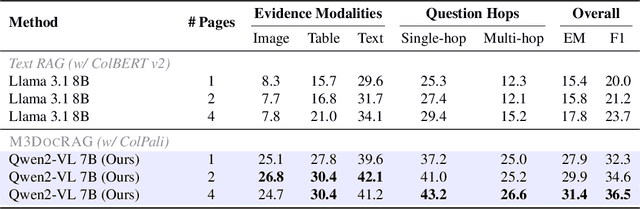
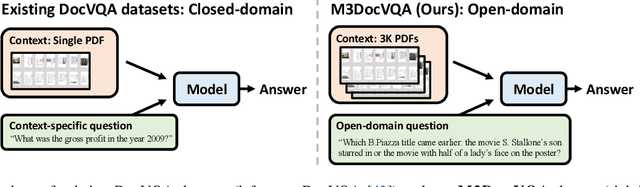
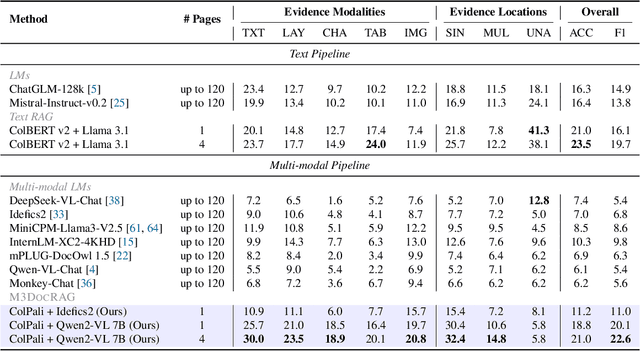
Document visual question answering (DocVQA) pipelines that answer questions from documents have broad applications. Existing methods focus on handling single-page documents with multi-modal language models (MLMs), or rely on text-based retrieval-augmented generation (RAG) that uses text extraction tools such as optical character recognition (OCR). However, there are difficulties in applying these methods in real-world scenarios: (a) questions often require information across different pages or documents, where MLMs cannot handle many long documents; (b) documents often have important information in visual elements such as figures, but text extraction tools ignore them. We introduce M3DocRAG, a novel multi-modal RAG framework that flexibly accommodates various document contexts (closed-domain and open-domain), question hops (single-hop and multi-hop), and evidence modalities (text, chart, figure, etc.). M3DocRAG finds relevant documents and answers questions using a multi-modal retriever and an MLM, so that it can efficiently handle single or many documents while preserving visual information. Since previous DocVQA datasets ask questions in the context of a specific document, we also present M3DocVQA, a new benchmark for evaluating open-domain DocVQA over 3,000+ PDF documents with 40,000+ pages. In three benchmarks (M3DocVQA/MMLongBench-Doc/MP-DocVQA), empirical results show that M3DocRAG with ColPali and Qwen2-VL 7B achieves superior performance than many strong baselines, including state-of-the-art performance in MP-DocVQA. We provide comprehensive analyses of different indexing, MLMs, and retrieval models. Lastly, we qualitatively show that M3DocRAG can successfully handle various scenarios, such as when relevant information exists across multiple pages and when answer evidence only exists in images.
Enhancing Keyphrase Extraction from Long Scientific Documents using Graph Embeddings
May 16, 2023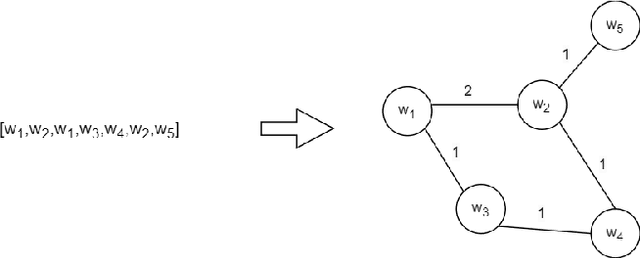

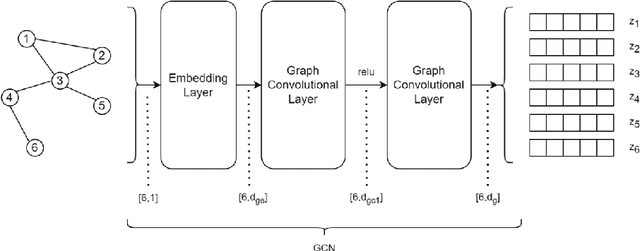

In this study, we investigate using graph neural network (GNN) representations to enhance contextualized representations of pre-trained language models (PLMs) for keyphrase extraction from lengthy documents. We show that augmenting a PLM with graph embeddings provides a more comprehensive semantic understanding of words in a document, particularly for long documents. We construct a co-occurrence graph of the text and embed it using a graph convolutional network (GCN) trained on the task of edge prediction. We propose a graph-enhanced sequence tagging architecture that augments contextualized PLM embeddings with graph representations. Evaluating on benchmark datasets, we demonstrate that enhancing PLMs with graph embeddings outperforms state-of-the-art models on long documents, showing significant improvements in F1 scores across all the datasets. Our study highlights the potential of GNN representations as a complementary approach to improve PLM performance for keyphrase extraction from long documents.
LDKP: A Dataset for Identifying Keyphrases from Long Scientific Documents
Apr 01, 2022
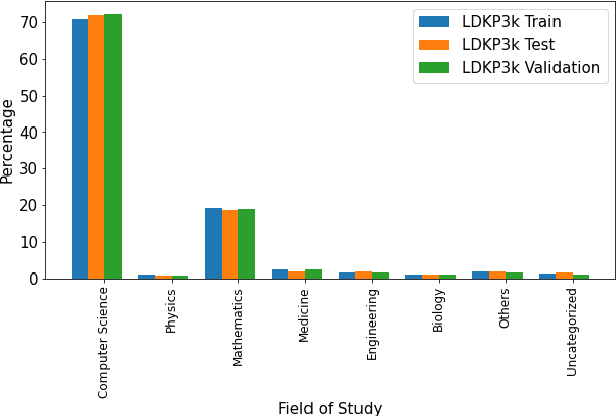
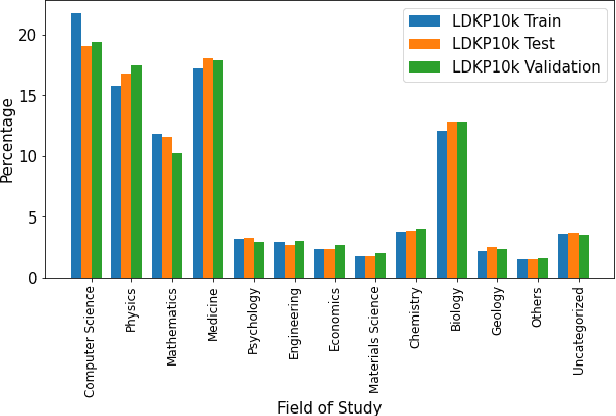

Identifying keyphrases (KPs) from text documents is a fundamental task in natural language processing and information retrieval. Vast majority of the benchmark datasets for this task are from the scientific domain containing only the document title and abstract information. This limits keyphrase extraction (KPE) and keyphrase generation (KPG) algorithms to identify keyphrases from human-written summaries that are often very short (approx 8 sentences). This presents three challenges for real-world applications: human-written summaries are unavailable for most documents, the documents are almost always long, and a high percentage of KPs are directly found beyond the limited context of title and abstract. Therefore, we release two extensive corpora mapping KPs of ~1.3M and ~100K scientific articles with their fully extracted text and additional metadata including publication venue, year, author, field of study, and citations for facilitating research on this real-world problem.
On the Evaluation of Answer-Agnostic Paragraph-level Multi-Question Generation
Mar 11, 2022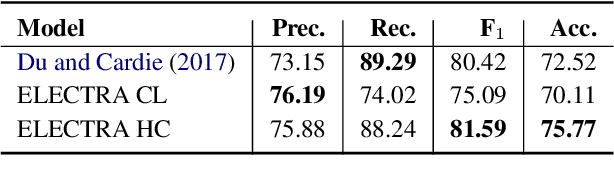

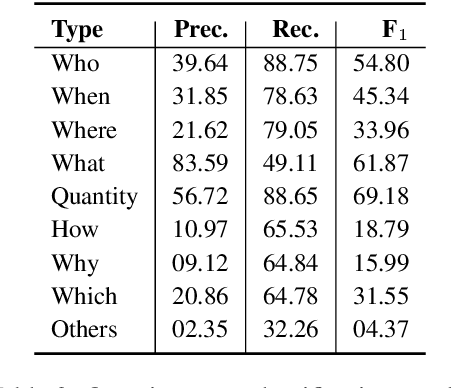

We study the task of predicting a set of salient questions from a given paragraph without any prior knowledge of the precise answer. We make two main contributions. First, we propose a new method to evaluate a set of predicted questions against the set of references by using the Hungarian algorithm to assign predicted questions to references before scoring the assigned pairs. We show that our proposed evaluation strategy has better theoretical and practical properties compared to prior methods because it can properly account for the coverage of references. Second, we compare different strategies to utilize a pre-trained seq2seq model to generate and select a set of questions related to a given paragraph. The code is available.
Learning Rich Representation of Keyphrases from Text
Dec 16, 2021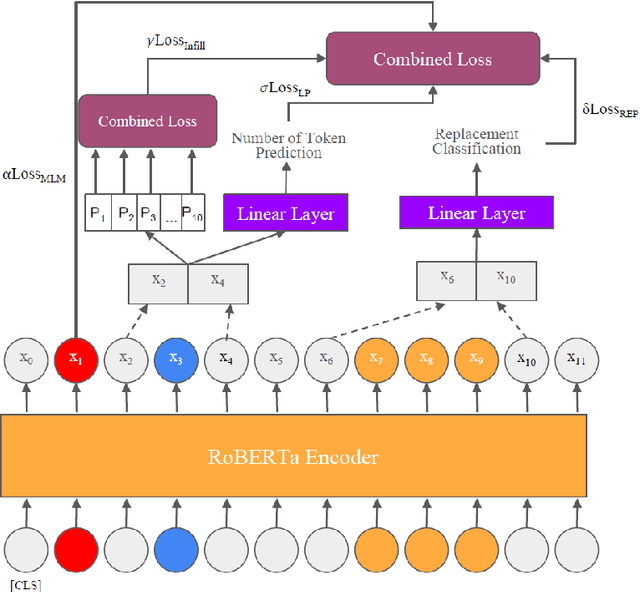

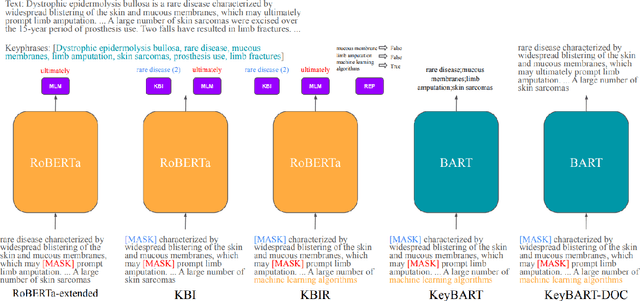
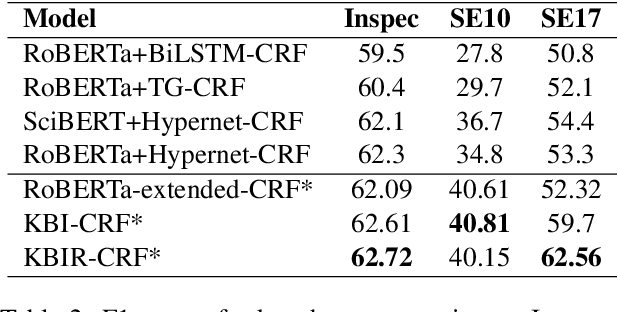
In this work, we explore how to learn task-specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (upto 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (upto 4.33 points in F1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition (NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks.
On the Use of Context for Predicting Citation Worthiness of Sentences in Scholarly Articles
Apr 18, 2021
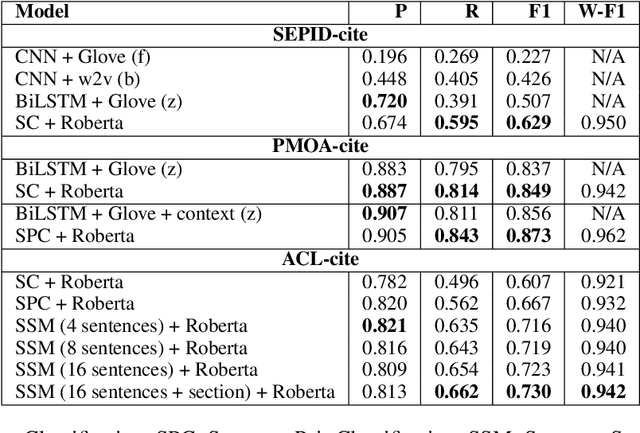
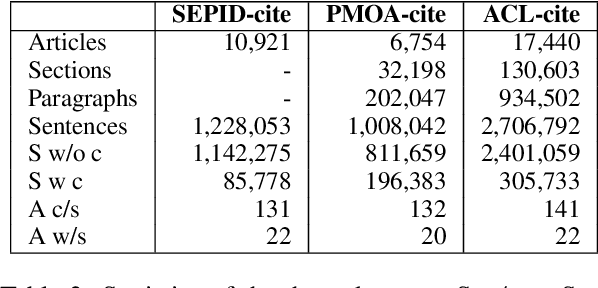
In this paper, we study the importance of context in predicting the citation worthiness of sentences in scholarly articles. We formulate this problem as a sequence labeling task solved using a hierarchical BiLSTM model. We contribute a new benchmark dataset containing over two million sentences and their corresponding labels. We preserve the sentence order in this dataset and perform document-level train/test splits, which importantly allows incorporating contextual information in the modeling process. We evaluate the proposed approach on three benchmark datasets. Our results quantify the benefits of using context and contextual embeddings for citation worthiness. Lastly, through error analysis, we provide insights into cases where context plays an essential role in predicting citation worthiness.
GupShup: An Annotated Corpus for Abstractive Summarization of Open-Domain Code-Switched Conversations
Apr 17, 2021



Code-switching is the communication phenomenon where speakers switch between different languages during a conversation. With the widespread adoption of conversational agents and chat platforms, code-switching has become an integral part of written conversations in many multi-lingual communities worldwide. This makes it essential to develop techniques for summarizing and understanding these conversations. Towards this objective, we introduce abstractive summarization of Hindi-English code-switched conversations and develop the first code-switched conversation summarization dataset - GupShup, which contains over 6,831 conversations in Hindi-English and their corresponding human-annotated summaries in English and Hindi-English. We present a detailed account of the entire data collection and annotation processes. We analyze the dataset using various code-switching statistics. We train state-of-the-art abstractive summarization models and report their performances using both automated metrics and human evaluation. Our results show that multi-lingual mBART and multi-view seq2seq models obtain the best performances on the new dataset
Get It Scored Using AutoSAS -- An Automated System for Scoring Short Answers
Dec 21, 2020
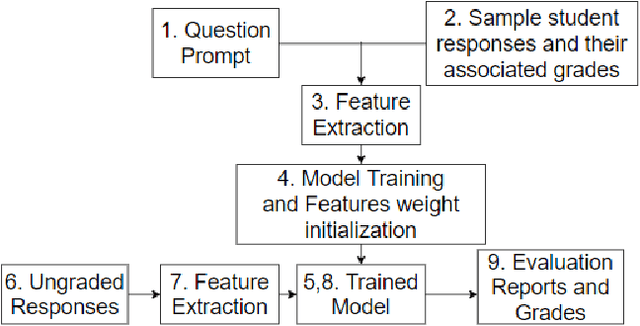


In the era of MOOCs, online exams are taken by millions of candidates, where scoring short answers is an integral part. It becomes intractable to evaluate them by human graders. Thus, a generic automated system capable of grading these responses should be designed and deployed. In this paper, we present a fast, scalable, and accurate approach towards automated Short Answer Scoring (SAS). We propose and explain the design and development of a system for SAS, namely AutoSAS. Given a question along with its graded samples, AutoSAS can learn to grade that prompt successfully. This paper further lays down the features such as lexical diversity, Word2Vec, prompt, and content overlap that plays a pivotal role in building our proposed model. We also present a methodology for indicating the factors responsible for scoring an answer. The trained model is evaluated on an extensively used public dataset, namely Automated Student Assessment Prize Short Answer Scoring (ASAP-SAS). AutoSAS shows state-of-the-art performance and achieves better results by over 8% in some of the question prompts as measured by Quadratic Weighted Kappa (QWK), showing performance comparable to humans.
MIDAS at SemEval-2020 Task 10: Emphasis Selection using Label Distribution Learning and Contextual Embeddings
Sep 06, 2020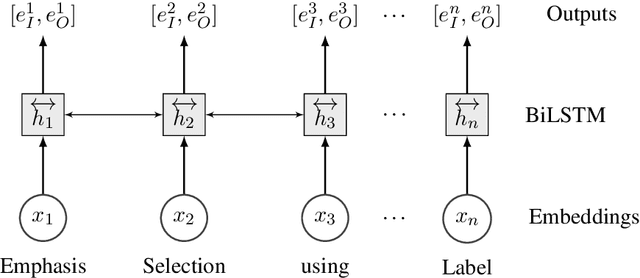
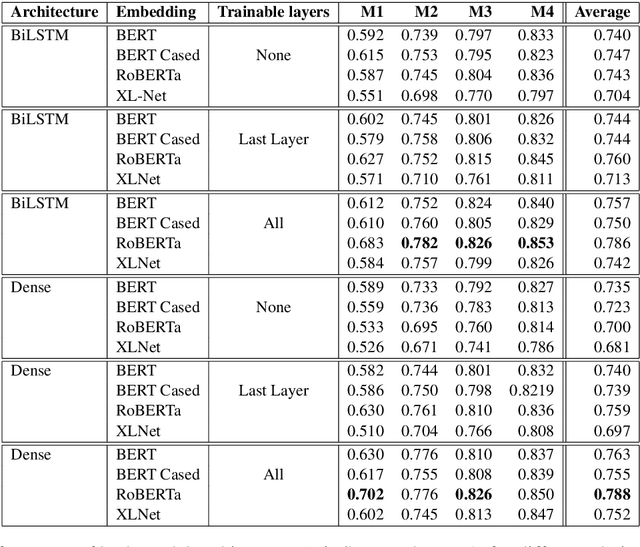


This paper presents our submission to the SemEval 2020 - Task 10 on emphasis selection in written text. We approach this emphasis selection problem as a sequence labeling task where we represent the underlying text with various contextual embedding models. We also employ label distribution learning to account for annotator disagreements. We experiment with the choice of model architectures, trainability of layers, and different contextual embeddings. Our best performing architecture is an ensemble of different models, which achieved an overall matching score of 0.783, placing us 15th out of 31 participating teams. Lastly, we analyze the results in terms of parts of speech tags, sentence lengths, and word ordering.
An Iterative Approach for Identifying Complaint Based Tweets in Social Media Platforms
Jan 24, 2020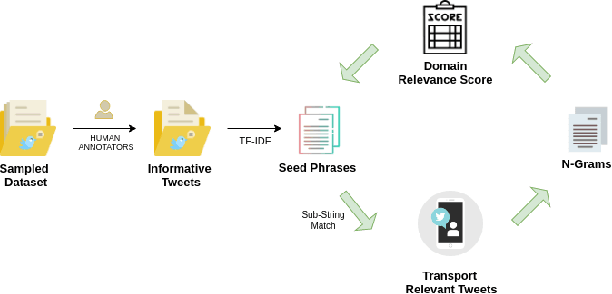

Twitter is a social media platform where users express opinions over a variety of issues. Posts offering grievances or complaints can be utilized by private/ public organizations to improve their service and promptly gauge a low-cost assessment. In this paper, we propose an iterative methodology which aims to identify complaint based posts pertaining to the transport domain. We perform comprehensive evaluations along with releasing a novel dataset for the research purposes.