 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Design Space Between Transformers and Recursive Neural Nets
Sep 03, 2024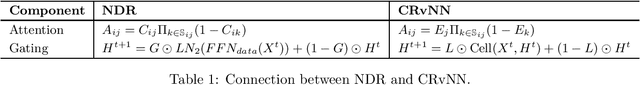
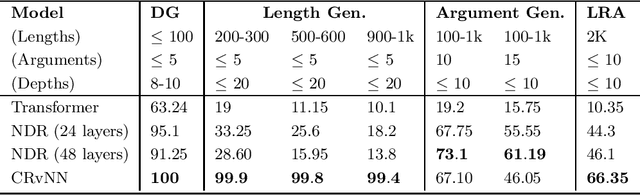
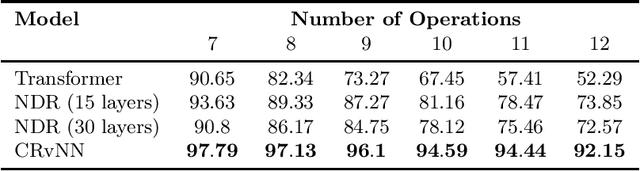
In this paper, we study two classes of models, Recursive Neural Networks (RvNNs) and Transformers, and show that a tight connection between them emerges from the recent development of two recent models - Continuous Recursive Neural Networks (CRvNN) and Neural Data Routers (NDR). On one hand, CRvNN pushes the boundaries of traditional RvNN, relaxing its discrete structure-wise composition and ends up with a Transformer-like structure. On the other hand, NDR constrains the original Transformer to induce better structural inductive bias, ending up with a model that is close to CRvNN. Both models, CRvNN and NDR, show strong performance in algorithmic tasks and generalization in which simpler forms of RvNNs and Transformers fail. We explore these "bridge" models in the design space between RvNNs and Transformers, formalize their tight connections, discuss their limitations, and propose ideas for future research.
Recurrent Transformers with Dynamic Halt
Feb 01, 2024

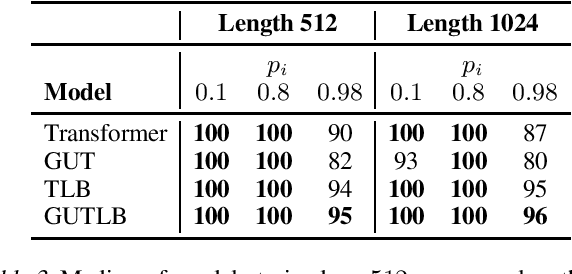

In this paper, we study the inductive biases of two major approaches to augmenting Transformers with a recurrent mechanism - (1) the approach of incorporating a depth-wise recurrence similar to Universal Transformers; and (2) the approach of incorporating a chunk-wise temporal recurrence like Temporal Latent Bottleneck. Furthermore, we propose and investigate novel ways to extend and combine the above methods - for example, we propose a global mean-based dynamic halting mechanism for Universal Transformer and an augmentation of Temporal Latent Bottleneck with elements from Universal Transformer. We compare the models and probe their inductive biases in several diagnostic tasks such as Long Range Arena (LRA), flip-flop language modeling, ListOps, and Logical Inference.
Recursion in Recursion: Two-Level Nested Recursion for Length Generalization with Scalability
Nov 08, 2023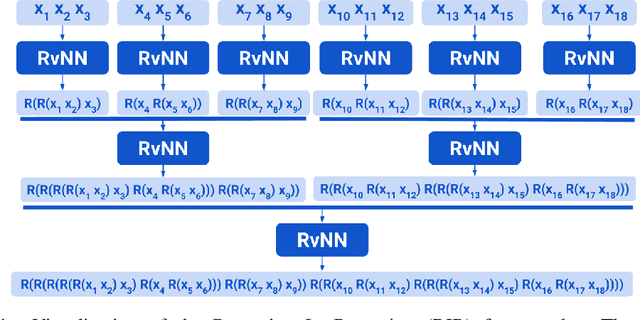
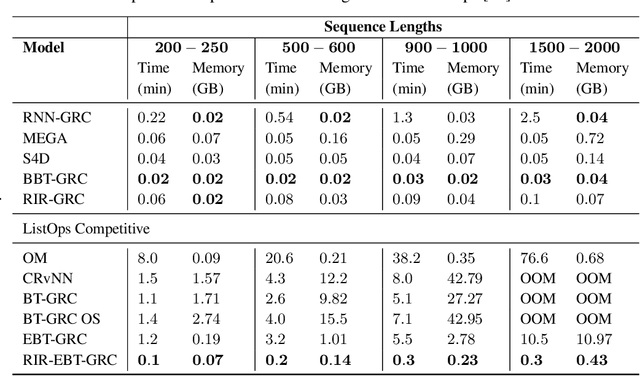
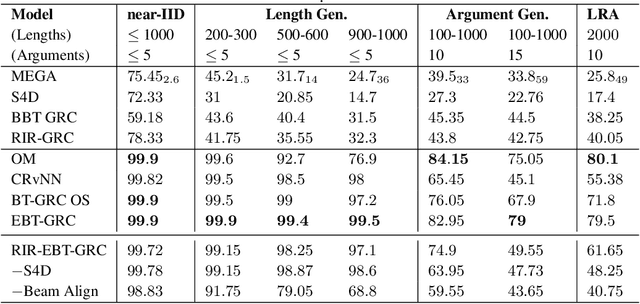
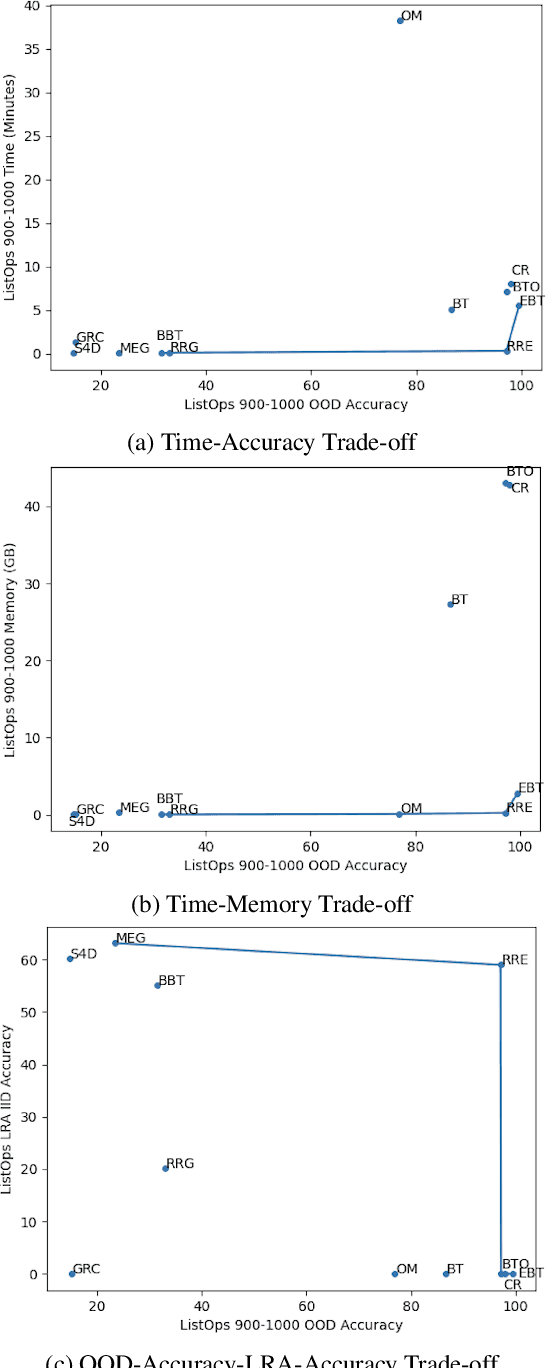
Binary Balanced Tree RvNNs (BBT-RvNNs) enforce sequence composition according to a preset balanced binary tree structure. Thus, their non-linear recursion depth is just $\log_2 n$ ($n$ being the sequence length). Such logarithmic scaling makes BBT-RvNNs efficient and scalable on long sequence tasks such as Long Range Arena (LRA). However, such computational efficiency comes at a cost because BBT-RvNNs cannot solve simple arithmetic tasks like ListOps. On the flip side, RvNNs (e.g., Beam Tree RvNN) that do succeed on ListOps (and other structure-sensitive tasks like formal logical inference) are generally several times more expensive than even RNNs. In this paper, we introduce a novel framework -- Recursion in Recursion (RIR) to strike a balance between the two sides - getting some of the benefits from both worlds. In RIR, we use a form of two-level nested recursion - where the outer recursion is a $k$-ary balanced tree model with another recursive model (inner recursion) implementing its cell function. For the inner recursion, we choose Beam Tree RvNNs (BT-RvNN). To adjust BT-RvNNs within RIR we also propose a novel strategy of beam alignment. Overall, this entails that the total recursive depth in RIR is upper-bounded by $k \log_k n$. Our best RIR-based model is the first model that demonstrates high ($\geq 90\%$) length-generalization performance on ListOps while at the same time being scalable enough to be trainable on long sequence inputs from LRA. Moreover, in terms of accuracy in the LRA language tasks, it performs competitively with Structured State Space Models (SSMs) without any special initialization - outperforming Transformers by a large margin. On the other hand, while SSMs can marginally outperform RIR on LRA, they (SSMs) fail to length-generalize on ListOps. Our code is available at: \url{https://github.com/JRC1995/BeamRecursionFamily/}.
Efficient Beam Tree Recursion
Jul 20, 2023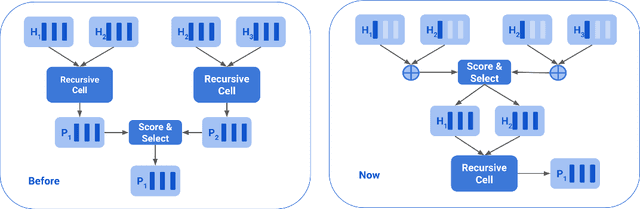
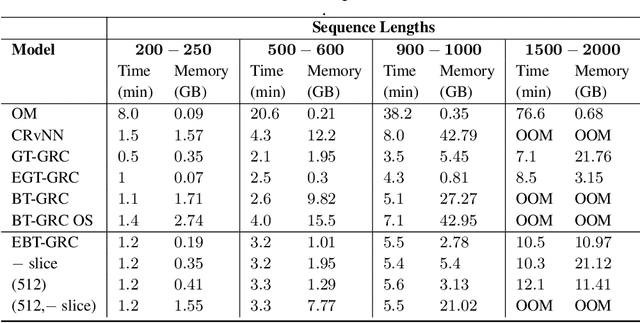
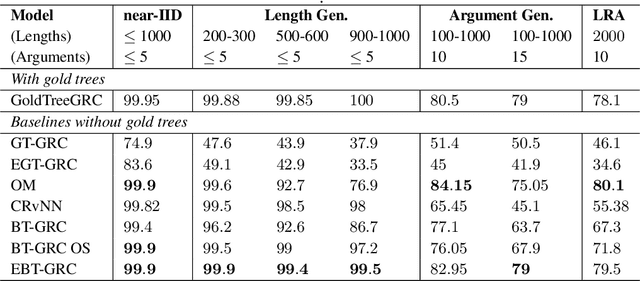
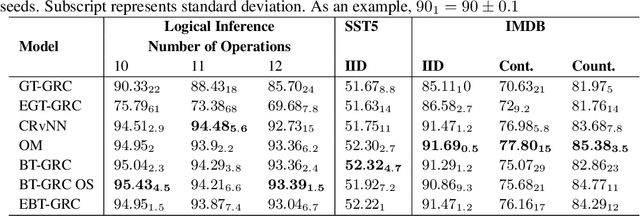
Beam Tree Recursive Neural Network (BT-RvNN) was recently proposed as a simple extension of Gumbel Tree RvNN and it was shown to achieve state-of-the-art length generalization performance in ListOps while maintaining comparable performance on other tasks. However, although not the worst in its kind, BT-RvNN can be still exorbitantly expensive in memory usage. In this paper, we identify the main bottleneck in BT-RvNN's memory usage to be the entanglement of the scorer function and the recursive cell function. We propose strategies to remove this bottleneck and further simplify its memory usage. Overall, our strategies not only reduce the memory usage of BT-RvNN by $10$-$16$ times but also create a new state-of-the-art in ListOps while maintaining similar performance in other tasks. In addition, we also propose a strategy to utilize the induced latent-tree node representations produced by BT-RvNN to turn BT-RvNN from a sentence encoder of the form $f:\mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{d}$ into a sequence contextualizer of the form $f:\mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{n \times d}$. Thus, our proposals not only open up a path for further scalability of RvNNs but also standardize a way to use BT-RvNNs as another building block in the deep learning toolkit that can be easily stacked or interfaced with other popular models such as Transformers and Structured State Space models.
Beam Tree Recursive Cells
Jun 01, 2023We propose Beam Tree Recursive Cell (BT-Cell) - a backpropagation-friendly framework to extend Recursive Neural Networks (RvNNs) with beam search for latent structure induction. We further extend this framework by proposing a relaxation of the hard top-k operators in beam search for better propagation of gradient signals. We evaluate our proposed models in different out-of-distribution splits in both synthetic and realistic data. Our experiments show that BTCell achieves near-perfect performance on several challenging structure-sensitive synthetic tasks like ListOps and logical inference while maintaining comparable performance in realistic data against other RvNN-based models. Additionally, we identify a previously unknown failure case for neural models in generalization to unseen number of arguments in ListOps. The code is available at: https://github.com/JRC1995/BeamTreeRecursiveCells.
Monotonic Location Attention for Length Generalization
May 31, 2023



We explore different ways to utilize position-based cross-attention in seq2seq networks to enable length generalization in algorithmic tasks. We show that a simple approach of interpolating the original and reversed encoded representations combined with relative attention allows near-perfect length generalization for both forward and reverse lookup tasks or copy tasks that had been generally hard to tackle. We also devise harder diagnostic tasks where the relative distance of the ideal attention position varies with timestep. In such settings, the simple interpolation trick with relative attention is not sufficient. We introduce novel variants of location attention building on top of Dubois et al. (2020) to address the new diagnostic tasks. We also show the benefits of our approaches for length generalization in SCAN (Lake & Baroni, 2018) and CFQ (Keysers et al., 2020). Our code is available on GitHub.
Data Augmentation for Low-Resource Keyphrase Generation
May 29, 2023Keyphrase generation is the task of summarizing the contents of any given article into a few salient phrases (or keyphrases). Existing works for the task mostly rely on large-scale annotated datasets, which are not easy to acquire. Very few works address the problem of keyphrase generation in low-resource settings, but they still rely on a lot of additional unlabeled data for pretraining and on automatic methods for pseudo-annotations. In this paper, we present data augmentation strategies specifically to address keyphrase generation in purely resource-constrained domains. We design techniques that use the full text of the articles to improve both present and absent keyphrase generation. We test our approach comprehensively on three datasets and show that the data augmentation strategies consistently improve the state-of-the-art performance. We release our source code at https://github.com/kgarg8/kpgen-lowres-data-aug.
Neural Keyphrase Generation: Analysis and Evaluation
Apr 27, 2023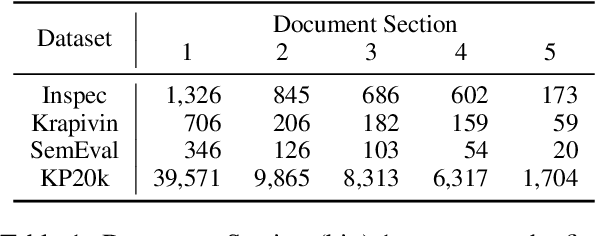



Keyphrase generation aims at generating topical phrases from a given text either by copying from the original text (present keyphrases) or by producing new keyphrases (absent keyphrases) that capture the semantic meaning of the text. Encoder-decoder models are most widely used for this task because of their capabilities for absent keyphrase generation. However, there has been little to no analysis on the performance and behavior of such models for keyphrase generation. In this paper, we study various tendencies exhibited by three strong models: T5 (based on a pre-trained transformer), CatSeq-Transformer (a non-pretrained Transformer), and ExHiRD (based on a recurrent neural network). We analyze prediction confidence scores, model calibration, and the effect of token position on keyphrases generation. Moreover, we motivate and propose a novel metric framework, SoftKeyScore, to evaluate the similarity between two sets of keyphrases by using softscores to account for partial matching and semantic similarity. We find that SoftKeyScore is more suitable than the standard F1 metric for evaluating two sets of given keyphrases.
On the Evaluation of Answer-Agnostic Paragraph-level Multi-Question Generation
Mar 11, 2022

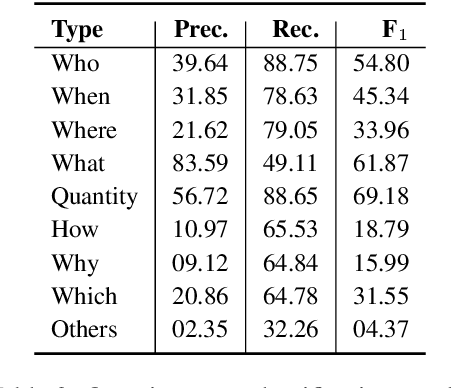

We study the task of predicting a set of salient questions from a given paragraph without any prior knowledge of the precise answer. We make two main contributions. First, we propose a new method to evaluate a set of predicted questions against the set of references by using the Hungarian algorithm to assign predicted questions to references before scoring the assigned pairs. We show that our proposed evaluation strategy has better theoretical and practical properties compared to prior methods because it can properly account for the coverage of references. Second, we compare different strategies to utilize a pre-trained seq2seq model to generate and select a set of questions related to a given paragraph. The code is available.
Novelty Controlled Paraphrase Generation with Retrieval Augmented Conditional Prompt Tuning
Feb 01, 2022
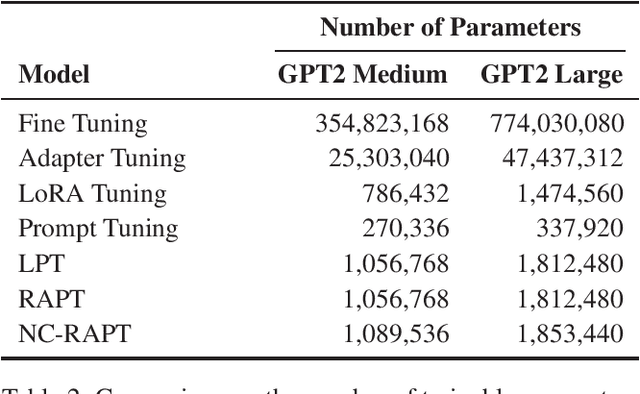

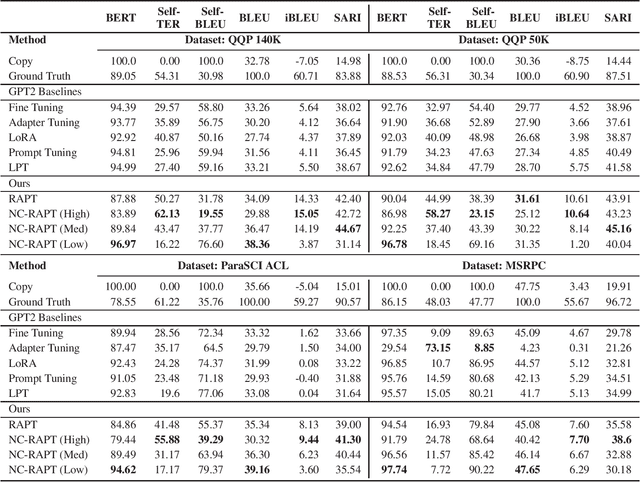
Paraphrase generation is a fundamental and long-standing task in natural language processing. In this paper, we concentrate on two contributions to the task: (1) we propose Retrieval Augmented Prompt Tuning (RAPT) as a parameter-efficient method to adapt large pre-trained language models for paraphrase generation; (2) we propose Novelty Conditioned RAPT (NC-RAPT) as a simple model-agnostic method of using specialized prompt tokens for controlled paraphrase generation with varying levels of lexical novelty. By conducting extensive experiments on four datasets, we demonstrate the effectiveness of the proposed approaches for retaining the semantic content of the original text while inducing lexical novelty in the generation.