 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Use ChatGPT To Write Our Paper! Benchmarking LLMs To Write the Introduction of a Research Paper
Aug 19, 2025
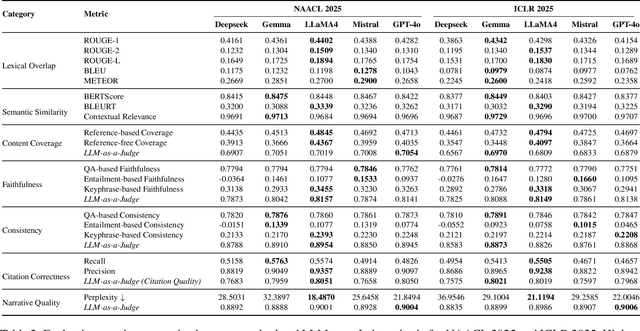
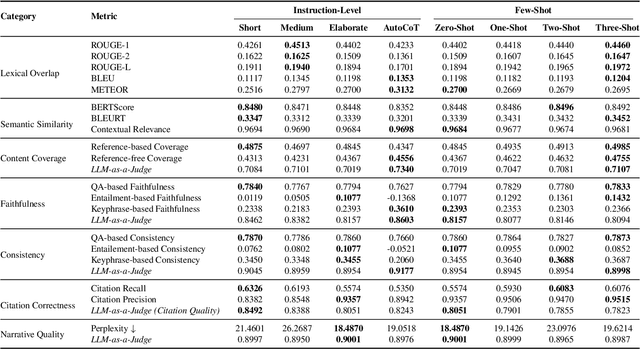
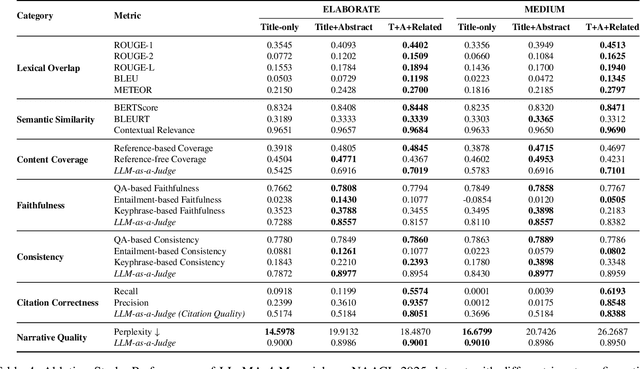
As researchers increasingly adopt LLMs as writing assistants, generating high-quality research paper introductions remains both challenging and essential. We introduce Scientific Introduction Generation (SciIG), a task that evaluates LLMs' ability to produce coherent introductions from titles, abstracts, and related works. Curating new datasets from NAACL 2025 and ICLR 2025 papers, we assess five state-of-the-art models, including both open-source (DeepSeek-v3, Gemma-3-12B, LLaMA 4-Maverick, MistralAI Small 3.1) and closed-source GPT-4o systems, across multiple dimensions: lexical overlap, semantic similarity, content coverage, faithfulness, consistency, citation correctness, and narrative quality. Our comprehensive framework combines automated metrics with LLM-as-a-judge evaluations. Results demonstrate LLaMA-4 Maverick's superior performance on most metrics, particularly in semantic similarity and faithfulness. Moreover, three-shot prompting consistently outperforms fewer-shot approaches. These findings provide practical insights into developing effective research writing assistants and set realistic expectations for LLM-assisted academic writing. To foster reproducibility and future research, we will publicly release all code and datasets.
Stanceformer: Target-Aware Transformer for Stance Detection
Oct 09, 2024The task of Stance Detection involves discerning the stance expressed in a text towards a specific subject or target. Prior works have relied on existing transformer models that lack the capability to prioritize targets effectively. Consequently, these models yield similar performance regardless of whether we utilize or disregard target information, undermining the task's significance. To address this challenge, we introduce Stanceformer, a target-aware transformer model that incorporates enhanced attention towards the targets during both training and inference. Specifically, we design a \textit{Target Awareness} matrix that increases the self-attention scores assigned to the targets. We demonstrate the efficacy of the Stanceformer with various BERT-based models, including state-of-the-art models and Large Language Models (LLMs), and evaluate its performance across three stance detection datasets, alongside a zero-shot dataset. Our approach Stanceformer not only provides superior performance but also generalizes even to other domains, such as Aspect-based Sentiment Analysis. We make the code publicly available.\footnote{\scriptsize\url{https://github.com/kgarg8/Stanceformer}}
Data Augmentation for Low-Resource Keyphrase Generation
May 29, 2023Keyphrase generation is the task of summarizing the contents of any given article into a few salient phrases (or keyphrases). Existing works for the task mostly rely on large-scale annotated datasets, which are not easy to acquire. Very few works address the problem of keyphrase generation in low-resource settings, but they still rely on a lot of additional unlabeled data for pretraining and on automatic methods for pseudo-annotations. In this paper, we present data augmentation strategies specifically to address keyphrase generation in purely resource-constrained domains. We design techniques that use the full text of the articles to improve both present and absent keyphrase generation. We test our approach comprehensively on three datasets and show that the data augmentation strategies consistently improve the state-of-the-art performance. We release our source code at https://github.com/kgarg8/kpgen-lowres-data-aug.
Keyphrase Generation Beyond the Boundaries of Title and Abstract
Dec 13, 2021
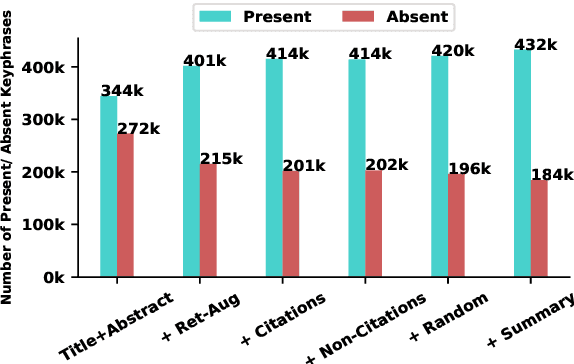


Keyphrase generation aims at generating phrases (keyphrases) that best describe a given document. In scholarly domains, current approaches to this task are neural approaches and have largely worked with only the title and abstract of the articles. In this work, we explore whether the integration of additional data from semantically similar articles or from the full text of the given article can be helpful for a neural keyphrase generation model. We discover that adding sentences from the full text particularly in the form of summary of the article can significantly improve the generation of both types of keyphrases that are either present or absent from the title and abstract. The experimental results on the three acclaimed models along with one of the latest transformer models suitable for longer documents, Longformer Encoder-Decoder (LED) validate the observation. We also present a new large-scale scholarly dataset FullTextKP for keyphrase generation, which we use for our experiments. Unlike prior large-scale datasets, FullTextKP includes the full text of the articles alongside title and abstract. We will release the source code to stimulate research on the proposed ideas.