 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIC: Masked Image Modeling with Image Correspondences
Jun 28, 2023Many pixelwise dense prediction tasks-depth estimation and semantic segmentation in computer vision today rely on pretrained image representations. Therefore, curating effective pretraining datasets is vital. Unfortunately, the effective pretraining datasets are those with multi-view scenes and have only been curated using annotated 3D meshes, point clouds, and camera parameters from simulated environments. We propose a dataset-curation mechanism that does not require any annotations. We mine two datasets: MIMIC-1M with 1.3M and MIMIC-3M with 3.1M multi-view image pairs from open-sourced video datasets and from synthetic 3D environments. We train multiple self-supervised models with different masked image modeling objectives to showcase the following findings: Representations trained on MIMIC-3M outperform those mined using annotations on multiple downstream tasks, including depth estimation, semantic segmentation, surface normals, and pose estimation. They also outperform representations that are frozen and when downstream training data is limited to few-shot. Larger dataset (MIMIC-3M) significantly improves performance, which is promising since our curation method can arbitrarily scale to produce even larger datasets. MIMIC code, dataset, and pretrained models are open-sourced at https://github.com/RAIVNLab/MIMIC.
Neural Keyphrase Generation: Analysis and Evaluation
Apr 27, 2023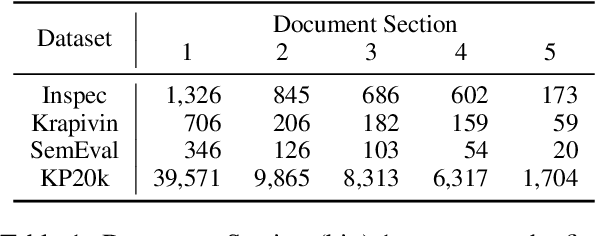



Keyphrase generation aims at generating topical phrases from a given text either by copying from the original text (present keyphrases) or by producing new keyphrases (absent keyphrases) that capture the semantic meaning of the text. Encoder-decoder models are most widely used for this task because of their capabilities for absent keyphrase generation. However, there has been little to no analysis on the performance and behavior of such models for keyphrase generation. In this paper, we study various tendencies exhibited by three strong models: T5 (based on a pre-trained transformer), CatSeq-Transformer (a non-pretrained Transformer), and ExHiRD (based on a recurrent neural network). We analyze prediction confidence scores, model calibration, and the effect of token position on keyphrases generation. Moreover, we motivate and propose a novel metric framework, SoftKeyScore, to evaluate the similarity between two sets of keyphrases by using softscores to account for partial matching and semantic similarity. We find that SoftKeyScore is more suitable than the standard F1 metric for evaluating two sets of given keyphrases.
KPDrop: An Approach to Improving Absent Keyphrase Generation
Dec 08, 2021
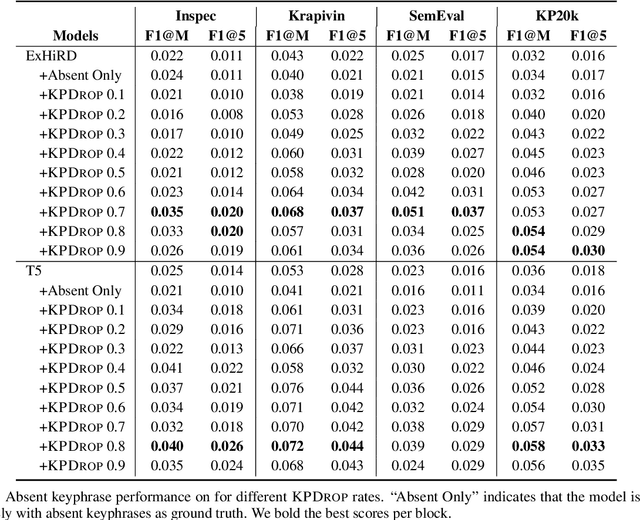

Keyphrase generation is the task of generating phrases (keyphrases) that summarize the main topics of a given document. The generated keyphrases can be either present or absent from the text of the given document. While the extraction of present keyphrases has received much attention in the past, only recently a stronger focus has been placed on the generation of absent keyphrases. However, generating absent keyphrases is very challenging; even the best methods show only a modest degree of success. In this paper, we propose an approach, called keyphrase dropout (or KPDrop), to improve absent keyphrase generation. We randomly drop present keyphrases from the document and turn them into artificial absent keyphrases during training. We test our approach extensively and show that it consistently improves the absent performance of strong baselines in keyphrase generation.