 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Retrieval Adaptation using Target Domain Description
Jul 06, 2023



In information retrieval (IR), domain adaptation is the process of adapting a retrieval model to a new domain whose data distribution is different from the source domain. Existing methods in this area focus on unsupervised domain adaptation where they have access to the target document collection or supervised (often few-shot) domain adaptation where they additionally have access to (limited) labeled data in the target domain. There also exists research on improving zero-shot performance of retrieval models with no adaptation. This paper introduces a new category of domain adaptation in IR that is as-yet unexplored. Here, similar to the zero-shot setting, we assume the retrieval model does not have access to the target document collection. In contrast, it does have access to a brief textual description that explains the target domain. We define a taxonomy of domain attributes in retrieval tasks to understand different properties of a source domain that can be adapted to a target domain. We introduce a novel automatic data construction pipeline that produces a synthetic document collection, query set, and pseudo relevance labels, given a textual domain description. Extensive experiments on five diverse target domains show that adapting dense retrieval models using the constructed synthetic data leads to effective retrieval performance on the target domain.
Novelty Controlled Paraphrase Generation with Retrieval Augmented Conditional Prompt Tuning
Feb 01, 2022
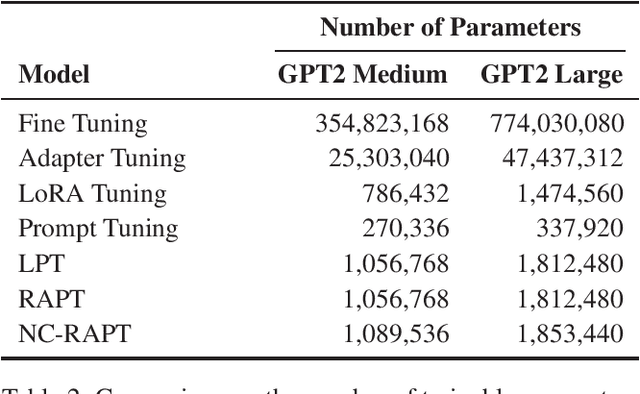

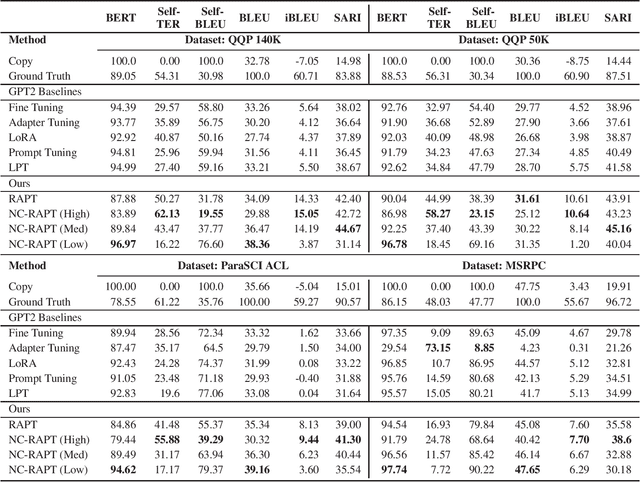
Paraphrase generation is a fundamental and long-standing task in natural language processing. In this paper, we concentrate on two contributions to the task: (1) we propose Retrieval Augmented Prompt Tuning (RAPT) as a parameter-efficient method to adapt large pre-trained language models for paraphrase generation; (2) we propose Novelty Conditioned RAPT (NC-RAPT) as a simple model-agnostic method of using specialized prompt tokens for controlled paraphrase generation with varying levels of lexical novelty. By conducting extensive experiments on four datasets, we demonstrate the effectiveness of the proposed approaches for retaining the semantic content of the original text while inducing lexical novelty in the generation.
Federated Natural Language Generation for Personalized Dialogue System
Oct 13, 2021
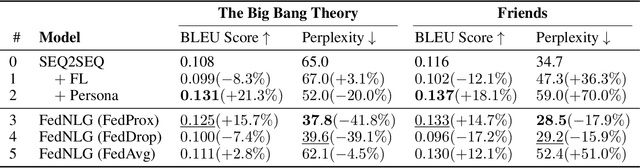

Neural conversational models have long suffered from the problem of inconsistency and lacking coherent personality. To address the issue, persona-based models capturing individual characteristics have been proposed, but they still face the dilemma of model adaption and data privacy. To break this dilemma, we propose a novel Federated Natural Language Generation (FedNLG) framework, which learns personalized representations from various dataset on distributed devices, and thus implements the personalized dialogue system efficiently and safely. FedNLG first pre-trains parameters of standard neural conversational model over a large dialogue corpus, and then fine-tune the model parameters and persona embeddings on specific datasets, in a federated manner. Thus, the model could simultaneously learn the persona embeddings in local clients and learn shared model parameters by federated aggregation, which achieves accuracyprivacy balance. By conducting extensive experiments, we demonstrate the effectiveness of our model by pre-training model over Cornell Movie-Dialogs Corpus and fine-tuning the model over two TV series dataset.